Short answer: Developers should test Qwen3.7-Max only where agent behavior, tool use, or cost changes a real workflow. Run it against your own coding tasks, compare it with your current default, and keep results tied to speed, quality, and failure rate.
Verdict: Qwen3.7-Max is worth testing this week if you run coding agents, office-workflow agents, or MCP-heavy automation and you can enforce spend limits. It is not the open-weight local Qwen drop many users were waiting for; it is Alibaba’s agent-runtime bet: proprietary, API-accessed through Model Studio, priced like a serious frontier model, and aimed at long-horizon tool use rather than cheap chat.
Put it in a sandbox, give it three real tasks, compare it against your existing Claude/Gemini/GPT stack, and stop the pilot if it cannot beat your incumbent on quality, review time, or cost per accepted change.
What changed
Alibaba Cloud published Qwen3.7-Max on May 21, 2026 as a proprietary model designed for the agent era. The official positioning is unusually explicit: coding and debugging, office workflows, MCP and multi-agent orchestration, and long-horizon autonomous execution are the headline use cases, not casual assistant chat.
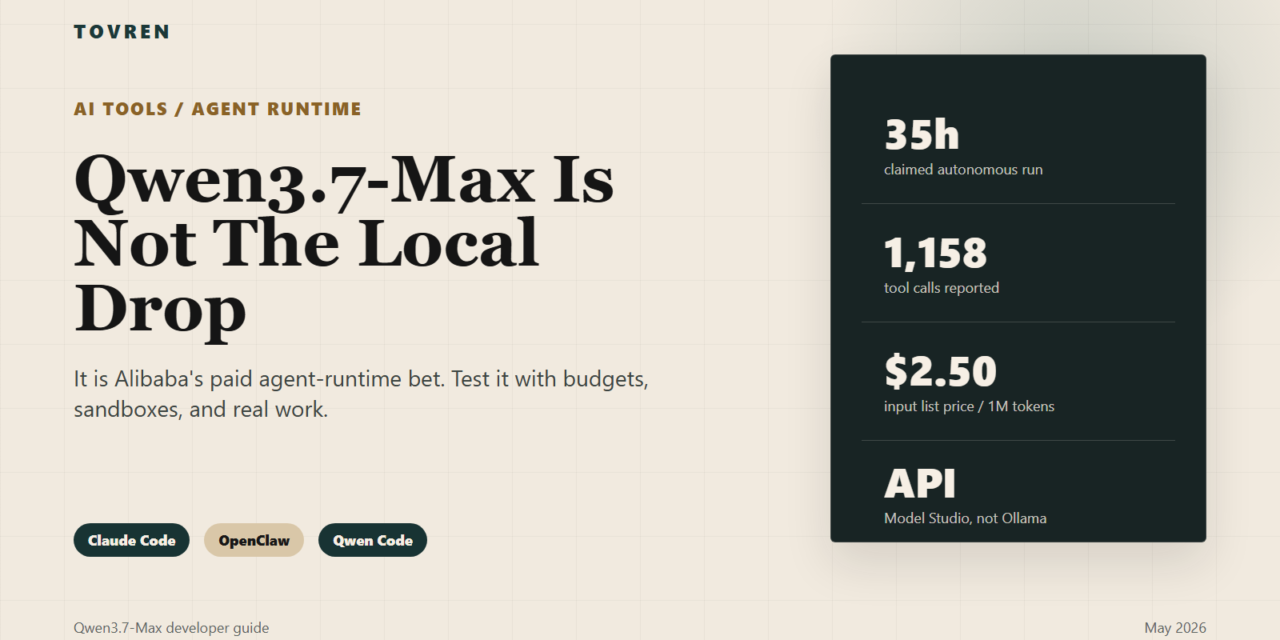
The strongest launch claim is the 35-hour autonomous kernel optimization run. Alibaba says Qwen3.7-Max performed 432 kernel evaluations and 1,158 tool calls while optimizing an SGLang Extend Attention kernel on T-Head ZW-M890 PPUs, eventually reporting a 10.0x geometric mean speedup over the Triton reference. Treat that as a vendor benchmark, not a guarantee for your repo. The useful signal is that this release is about whether an agent can keep improving after the first few hours.
| Launch fact | What it means for developers and operators |
|---|---|
| Qwen3.7-Max is proprietary and exposed through Alibaba Cloud Model Studio. | Plan for API access, vendor billing, permissions, and data-handling review. Do not treat this like a local Ollama or LM Studio model. |
| Model Studio lists Qwen3.7-Max with a May 21, 2026 launch time. | As of May 28, 2026, this is a fresh release. Expect docs, permissions, and community playbooks to move quickly. |
| Standard listed pricing is about $2.50 input and $7.50 output per 1M tokens. | It can be economically reasonable for high-value agent tasks, but it is not a leave-it-running-all-day default. |
| A campaign page shows a 50% discount until June 22, 2026. | Promo math can make pilots attractive, but production budgets should assume the list price returns. |
| Claude Code, OpenClaw, and Qwen Code paths are documented. | The practical test is cross-harness reliability: same task, same repo, same acceptance criteria. |
Who should test it now
Test Qwen3.7-Max now if the bottleneck in your workflow is not “can the model answer a question?” but “can an agent keep using tools safely until the job is done?” That includes teams already running terminal coding agents, QA automation, code migration work, data-cleaning workflows, spreadsheet-heavy operations, or MCP-connected internal assistants.
- Developer teams with annoying multi-file work: dependency upgrades, test-generation passes, refactors with clear failing tests, or bug hunts where the agent must inspect several files before acting.
- Founders and AI operators building internal automation: document processing, spreadsheet cleanup, CRM enrichment, report generation, and repeatable admin workflows where a human can inspect the output before it reaches customers.
- Technical managers comparing agent stacks: use Qwen3.7-Max as a benchmark candidate against your current Claude Code, Gemini, or GPT-based workflow. For a broader model comparison baseline, see Tovren’s best LLMs right now guide.
- Teams experimenting with MCP: Qwen’s launch messaging leans into MCP and multi-agent orchestration. That is interesting, but it makes permission design more important. Pair the pilot with Tovren’s MCP server access audit.
The best first use case has a measurable finish line: tests pass, a report matches a schema, a spreadsheet has no validation errors, or a pull request is small enough to review quickly. Vague “improve our codebase” prompts are where expensive agents turn into fog machines.
Who should skip it
Skip Qwen3.7-Max for now if your main requirement is local control, fixed consumer-style pricing, or cheap high-volume autocomplete. This is the wrong release to chase if you were waiting for a small open-weight Qwen 3.7 model to run on a workstation.
- Local-first users: use an open-weight Qwen model instead. Tovren’s Qwen 3.6 27B local setup guide is a better fit if the priority is 16GB VRAM experimentation.
- Teams without API spend controls: long-horizon agents can burn tokens through planning, file reads, retries, tool output, and verbose reasoning.
- Regulated teams without a cloud review path: treat Model Studio like any external model provider. Review data residency, logging, retention, and whether your prompts may include secrets or customer data.
- Teams expecting benchmark claims to transfer automatically: the 35-hour kernel run is interesting, but your repo, tools, CI speed, and review discipline decide production value.

Setup paths: Claude Code, OpenClaw, and Qwen Code
Do not connect Qwen3.7-Max to your main monorepo with broad credentials. Start with a fork, a disposable branch, least-privilege environment variables, and a task-specific workspace: no production secrets, no write access outside the workspace, no deployment permissions, and no uncontrolled MCP tools.
| Path | Best use | How to wire it | Safety note |
|---|---|---|---|
| Claude Code | Teams already using Claude Code workflows but wanting to compare Qwen as the model backend. | Alibaba documents an Anthropic-compatible endpoint. Set the Qwen model name, base URL, and auth token, then run the same Claude Code task suite. | Use a separate API key and a repo clone. Do not reuse your production Claude Code environment blindly. |
| OpenClaw | Cross-provider agent testing, model routing, and a dashboard-style harness. | Use the Model Studio compatible-mode base URL, add a model provider entry for qwen3.7-max, and set it as the primary model for a pilot agent. |
Review provider config, cache behavior, and tool permissions before enabling browser, shell, or MCP actions. |
| Qwen Code | Qwen-native terminal work, especially if your team wants the provider and agent to evolve together. | Install Qwen Code, authenticate with a Model Studio API key or supported plan, then select the Qwen model in your settings. | Qwen Code is a terminal agent; it still needs the same filesystem and command-execution boundaries as any coding agent. |
Minimum safe setup checklist
- Create a new Alibaba Cloud Model Studio API key for the pilot only.
- Set a hard daily and weekly budget in whatever billing controls are available to your account.
- Use a sandbox repo or throwaway branch with no production deployment credentials.
- Run the agent inside a dev container or restricted workspace where possible.
- Disable tools that can deploy, email customers, alter billing, or access unrelated internal systems.
- Log token usage, tool calls, wall-clock time, accepted changes, failed attempts, and manual-review minutes.
- For agentic tasks, test Alibaba’s recommended
preserve_thinkingbehavior only after you understand its cost and data-handling implications.
Alibaba recommends preserve_thinking for agentic tasks because it preserves thinking content from previous turns. Treat it as a continuity feature with a budget and privacy footprint, not as free magic.
Cost and budget guardrails
At list pricing, Qwen3.7-Max is about $2.50 per 1M input tokens and $7.50 per 1M output tokens. During the limited promotion, Alibaba’s campaign page shows about $1.25 input and $3.75 output per 1M tokens until June 22, 2026, with the 50% discount applying to input, output, explicit cache creation, and explicit cache hits. Build your pilot budget on promo pricing, but make your production decision on list pricing.
| Example run | Token pattern | Promo cost estimate | List cost estimate | Decision rule |
|---|---|---|---|---|
| Small bug fix | 1M input + 200K output | About $2.00 | About $4.00 | Worth testing if it saves 15+ minutes of senior developer time. |
| Multi-file refactor | 10M input + 2M output | About $20.00 | About $40.00 | Proceed only with tests, diff limits, and review checkpoints. |
| Long autonomous task | 20M input + 5M output | About $43.75 | About $87.50 | Use only for high-value work with stop conditions and clear acceptance tests. |
The expensive part of agent work is rarely one answer. It is repeated file reads, tool outputs, retries, and long context. Set a kill switch before the run starts: maximum dollars, tool calls, wall-clock time, files changed, and diff size.
Recommended pilot caps
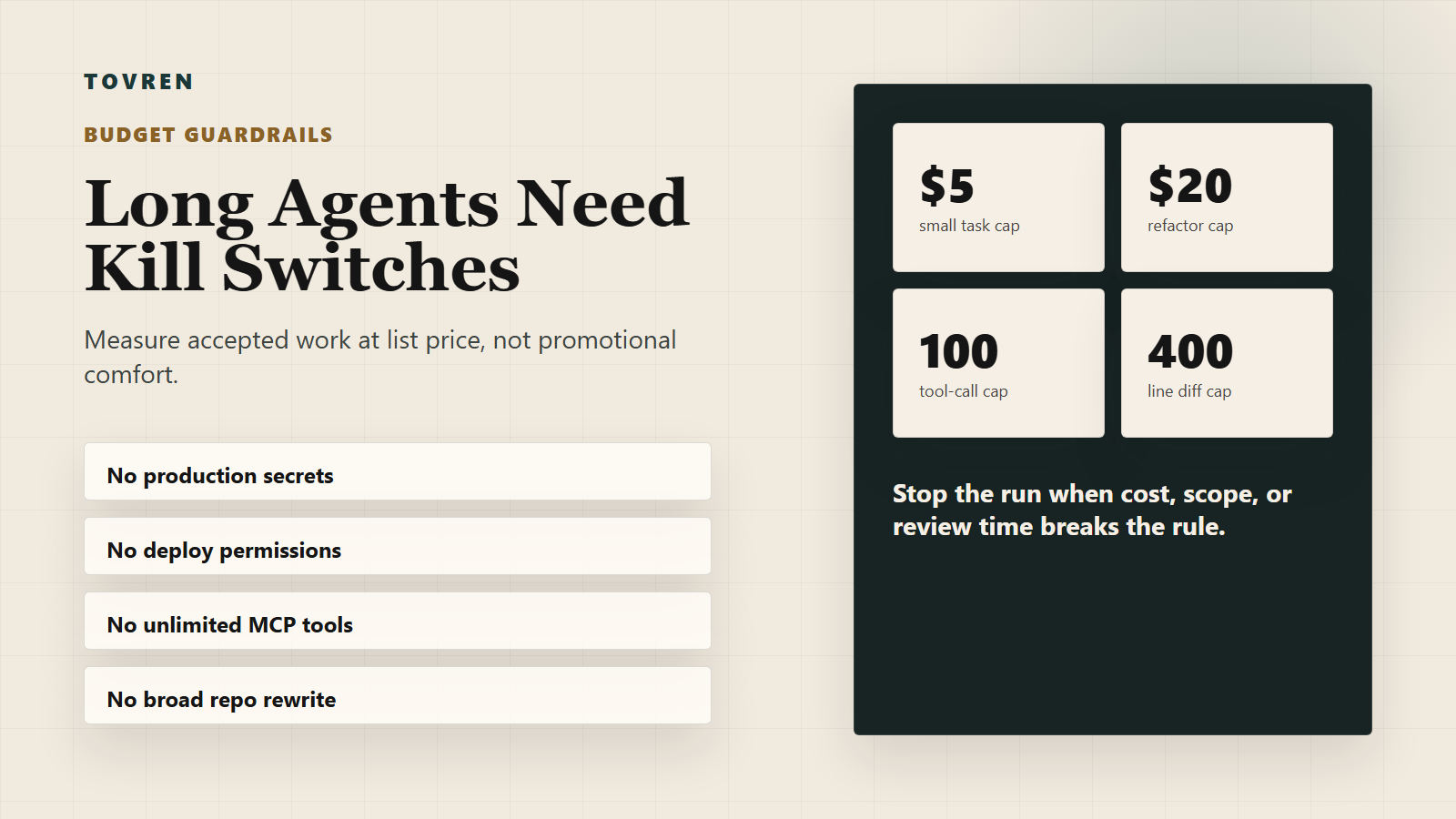
- Daily pilot cap: $25-$50 for an individual developer; $150-$300 for a small team pilot.
- Per-task cap: $5 for small bug fixes, $20 for multi-file refactors, $50 for long autonomous experiments.
- Tool-call cap: 100 for normal coding tasks; raise only when the task has a benchmark-style evaluator.
- Diff cap: no more than 400 changed lines without a human checkpoint.
- Review cap: if review takes longer than doing the work manually twice in a row, the task is not ready for this agent.
For teams already thinking about Claude credits, OpenClaw routing, and model selection, Tovren’s Claude Agent SDK credits and OpenClaw guide is a useful companion: the same credit-governance thinking applies here.

A 7-day Qwen3.7-Max pilot plan
Do not benchmark Qwen3.7-Max with toy prompts. Run three pilot tasks that represent your actual work, then score the outputs with boring metrics.
- Day 1: Access and guardrails. Confirm Model Studio access, enable the model if required, create a pilot-only API key, set billing alerts, and run a one-prompt smoke test.
- Day 2: Harness setup. Configure Claude Code, OpenClaw, or Qwen Code in a sandbox. Record model ID, endpoint, cache settings, and thinking settings.
- Day 3: Pilot task 1 – contained coding. Use a real bug with failing tests. Success means tests pass, diff is reviewable, and no unrelated files change.
- Day 4: Pilot task 2 – multi-file reasoning. Try a dependency upgrade, API migration, or type-system cleanup. Compare against your incumbent agent stack on the same branch.
- Day 5: Pilot task 3 – operator workflow. Use a spreadsheet, report, or document task with structured output. For prompt design ideas, adapt Tovren’s AI browser agent prompt pack.
- Day 6: Security and failure review. Inspect logs for risky commands, credential exposure, hallucinated tool use, excessive file access, and repeated loops.
- Day 7: Decision meeting. Keep, limit, or drop Qwen3.7-Max based on cost per accepted task, manual-review time, error severity, and whether it beats your current stack.
| Scorecard | Pass threshold |
|---|---|
| Completion quality | At least 2 of 3 pilot tasks accepted after normal human review. |
| Cost | At list pricing, cost per accepted task is justified by time saved or revenue protected. |
| Safety | No production secret exposure, uncontrolled deployment, or unexpected external action. |
| Reliability | No repeated tool loops, hidden scope expansion, or massive unrelated diffs. |
| Comparative value | Beats or clearly complements your Claude/Gemini/GPT workflow on at least one task class. |
Community friction: useful signals, not confirmed facts
Early community reports are worth reading, but they should not be treated as vendor-confirmed documentation. As of May 28, 2026, Reddit users in Qwen-related communities are reporting four kinds of friction.
- Access friction: some users say they cannot call
qwen3.7-maxthrough API or Qwen Code until model-call permissions are manually enabled in the business space. Treat this as a preflight item: verify access before scheduling a team pilot. - Credit burn: users have reported that a $30 token or credit plan can be consumed quickly with Qwen3.7-Max, especially through coding-agent workflows. This is anecdotal, but it matches the general economics of long-horizon agents.
- Cost and caching anxiety: OpenClaw/OpenCode-style users are asking whether caching, benchmark results, and real-codebase performance will make the model cost-effective. That is exactly why your pilot should track cache hits, tool calls, and accepted diffs.
- Local-model mismatch: LocalLLaMA-style users appear to be waiting for smaller or open-weight Qwen 3.7 models. Qwen3.7-Max should not be presented to them as a local release.
The takeaway: separate model capability from platform readiness. A strong agent model can still fail your team if permissions, billing, cache behavior, or tool access are unclear.
Bottom line
Qwen3.7-Max deserves a serious pilot, not hype and not dismissal. Alibaba is pushing it as an agent foundation model that can sustain long tool-using runs across frameworks. That claim must be tested against real workflows.
Test it if you have agent-shaped work, a sandbox, and the discipline to measure cost. Skip it if you want local weights, cheap chat, or a plug-and-play replacement for your current coding assistant. The winning move this week is not to crown Qwen3.7-Max. It is to run three bounded tasks, price them honestly at list rates, and decide whether the model earns a place in your agent stack.
FAQ
Is Qwen3.7-Max open source?
No. Alibaba describes Qwen3.7-Max as a proprietary model available through Model Studio. If you want local or open-weight Qwen experiments, use a different Qwen release.
Is Qwen3.7-Max cheap enough for daily coding?
Only with guardrails. The launch promotion makes pilots cheaper until June 22, 2026, but the standard listed pricing is about $2.50 input and $7.50 output per 1M tokens. Daily use should have per-task caps and billing alerts.
Should I use Qwen3.7-Max through Claude Code, OpenClaw, or Qwen Code?
Use the harness you already trust. Claude Code is useful for comparing against existing Claude-style workflows, OpenClaw is useful for cross-provider routing and dashboards, and Qwen Code is the natural Qwen-native terminal path.
What is the first task I should test?
Start with a real but bounded coding task: a failing test, a small bug, or a contained refactor. Avoid broad “improve this repo” prompts until you know the model’s cost, diff behavior, and failure patterns.
Source log
| Source | Publisher / date | Used for |
|---|---|---|
| Qwen3.7: The Agent Frontier | Alibaba Cloud Community, May 21, 2026; accessed May 28, 2026 | Launch positioning, proprietary model description, agent use cases, 35-hour kernel optimization claim, Claude Code/OpenClaw/Qwen Code paths, preserve_thinking. |
| Alibaba Cloud Model Studio | Alibaba Cloud, accessed May 28, 2026 | Model availability, launch time, agent foundation positioning, standard input/output pricing. |
| Qwen3.7-Max 50% Off campaign page | Alibaba Cloud, accessed May 28, 2026 | Promotional pricing, discount end date, discounted input/output pricing, billing items covered by promotion. |
| VentureBeat coverage of Qwen3.7-Max | VentureBeat, May 2026; accessed May 28, 2026 | Secondary context on API-only/proprietary positioning, Claude Code compatibility, pricing comparison. Used cautiously as secondary coverage. |
| QwenLM/qwen-code GitHub repository | QwenLM / GitHub, accessed May 28, 2026 | Qwen Code installation, terminal-agent positioning, authentication methods, provider configuration context. |
| Reddit /r/Qwen_AI access-permission discussion | Community reports, May 2026; accessed May 28, 2026 | User-reported access-permission friction. Treated as anecdotal, not confirmed vendor data. |
| Reddit /r/Qwen_AI thread on $30 token plan consumption | Community report, May 2026; accessed May 28, 2026 | User-reported cost friction. Treated as anecdotal, not confirmed vendor data. |
| Reddit /r/opencodeCLI Qwen 3.7 Max review discussion | Community discussion, May 2026; accessed May 28, 2026 | User-reported concerns about API cost, discounts, and practical model economics. Treated as anecdotal. |
| Reddit /r/LocalLLaMA thread on waiting for Qwen 3.7 open weights | Community discussion, May 2026; accessed May 28, 2026 | Community signal that local/open-weight users are not treating Qwen3.7-Max as a local Ollama/LM Studio release. Treated as anecdotal. |