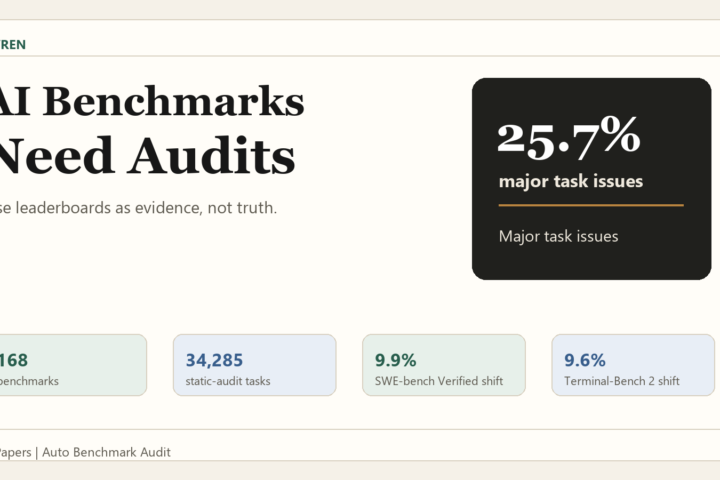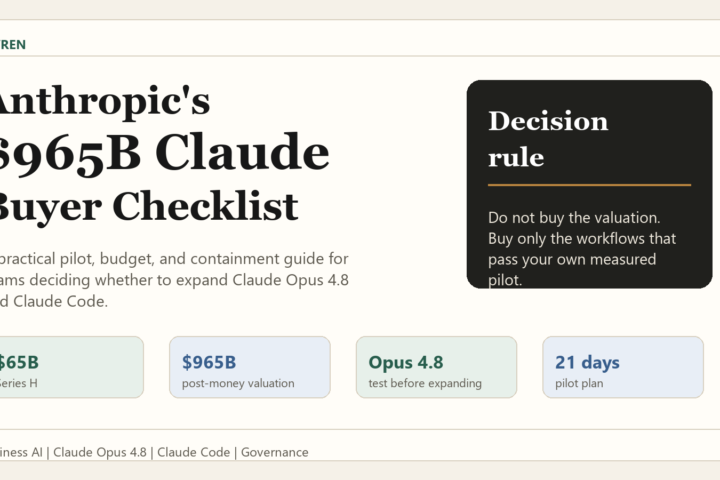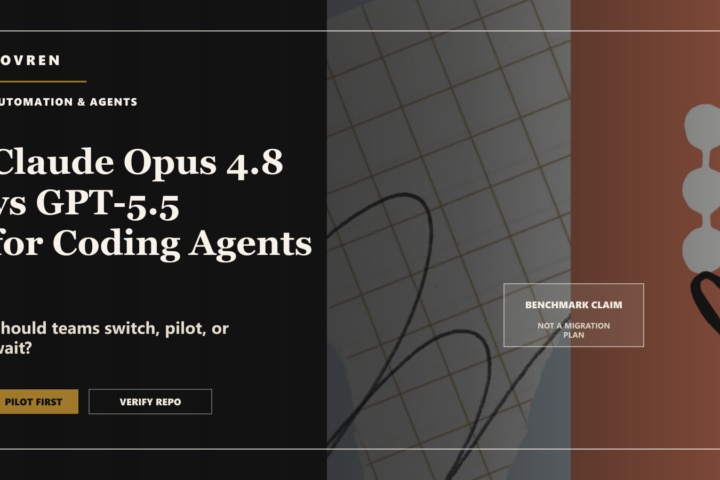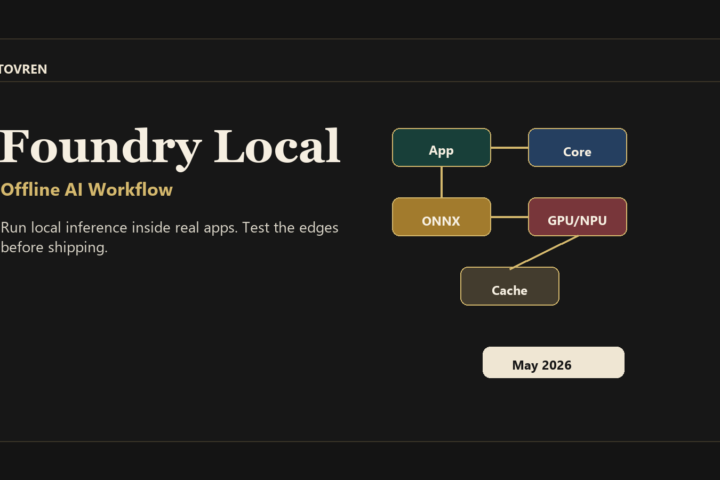
Foundry Local Setup Guide: Use It Now, But Test the Edges
Direct verdict: Foundry Local is worth testing now for desktop, edge, and offline AI apps, but do not replace Ollama, llama.cpp, or cloud inference until your target hardware, model catalog, endpoint behavior, and third-party integrations pass a real pilot.
Tovren Editorial