
Wall-OSS-0.5 is worth testing, but it is not proof that general-purpose robots are solved. The practical news is narrower and more useful: X Square Robot has released an open 4B vision-language-action model with public weights, a visible code path, and a vendor-reported real-robot zero-shot benchmark claim. That is enough to justify a serious pilot, not enough to justify procurement, production deployment, or automation redesign.
The right response is to run a controlled replication. Treat the May 28, 2026 launch as an invitation to measure Wall-OSS-0.5 against your own hardware, safety envelope, task distribution, latency budget, and recovery requirements. Public results remain vendor-reported until independent labs reproduce them on separate robot cells with clear task definitions, video logs, failure logs, and timing traces.
What changed
X Square Robot announced Wall-OSS-0.5 as an open-source Vision-Language-Action model for real-world robotic manipulation. The company’s central claim is that VLA pretraining can create robot behavior directly observable on physical hardware, instead of merely providing an initialization point for downstream fine-tuning. The reported headline is a pretrained checkpoint tested on a 17-task real-robot zero-shot suite, with task-progress scores above 80 on several tasks, including Block Sorting at 100, Fruit Sorting at 96, Ring Stacking at 86, and the held-out deformable Rope Tightening task at 82.
The Hugging Face model card describes Wall-OSS-0.5 as a 4B VLA foundation model built on a 3B vision-language backbone with dedicated action-generation components. It also says the model was pretrained across more than 20 robot embodiments and processes more than 1M trajectories per epoch with a grounded multimodal corpus. That is an unusually concrete open-model robotics release, especially for teams trying to inspect whether a pretrained VLA can do anything useful before task-specific fine-tuning.
| Item | What is public | How to read it |
|---|---|---|
| Model | Wall-OSS-0.5, described as an open-source 4B VLA model | Large enough to matter, still small enough for motivated labs to inspect locally |
| Backbone | 3B VLM backbone with action-generation components | Not a plain language model; evaluate perception, proprioception, and action output together |
| Zero-shot claim | Vendor-reported 17-task real-robot suite | Promising, but not independent evidence yet |
| Fine-tuning claim | Vendor-reported 60.5 average task progress on a 15-task real-robot fine-tuning suite | Useful as a benchmark target, not as a procurement guarantee |
| Release assets | Model weights, training code, recipes, optimizer implementations are described as part of the stack | Check the current repository state before planning a build around any specific script |
Why this is still useful
Most robotics demo cycles fail buyers and builders in the same way: they show a clean task, hide the sampling rate, omit the failed attempts, and never expose enough implementation detail for outsiders to reproduce the result. Wall-OSS-0.5 is more interesting because the release points to weights, a GitHub repository, Hugging Face loading examples, training recipes, and evaluation utilities. That does not make the model production-ready. It makes the claim testable.
For robotics builders, the key question is whether Wall-OSS-0.5 can serve as a better starting prior than a smaller imitation-learning policy or a closed demo model. For warehouse and manufacturing buyers, the question is harder: can any integrator show repeatable performance on your objects, lighting, grippers, fixtures, and fault conditions without heroic data collection? For embodied AI researchers, the question is whether the reported zero-shot progress survives independent task definitions and out-of-distribution perturbations.
This is also why the new VLA-REPLICA paper matters. Its authors argue that real-world VLA evaluation is constrained by the lack of accessible, reproducible, and consistent benchmarks, and they propose a low-cost, off-the-shelf benchmark that can be replicated across laboratories. That is exactly the standard Wall-OSS-0.5 should be held to: not one polished video, but reproducible tasks, independent setups, and comparable failure logs.
Do not assume this
The fastest way to misuse Wall-OSS-0.5 is to treat a zero-shot tabletop demo as evidence for a production robot cell. Keep the boundary sharp.
| Do not assume | Why it is unsafe | What to verify instead |
|---|---|---|
| Zero-shot means zero engineering | Robot calibration, camera placement, gripper choice, action scaling, and safety interlocks still decide whether a run works | Run the same task across at least three scene layouts and log all manual interventions |
| Vendor-reported task progress equals independent benchmark performance | Task-progress scoring can depend on definitions, partial-credit rules, object selection, and reset policy | Demand task cards, scoring rubrics, raw videos, and failure categories |
| Open weights equal deployable software | The Hugging Face model card is a starting point, not a complete robot deployment recipe | Verify inference loop, controller bridge, robot DOF mapping, watchdogs, and stop behavior |
| A tabletop demo transfers to a warehouse or production line | Industrial environments add occlusion, speed pressure, safety constraints, fixtures, human proximity, and rare edge cases | Test on your actual SKU families, bin geometry, lighting, and cycle-time limits |
| Multimodal reasoning is the bottleneck | The model may understand the instruction while failing grasp stability, contact dynamics, or precise placement | Separate semantic failures from manipulation failures in your logs |
What to test first: Wall-OSS-0.5 checklist
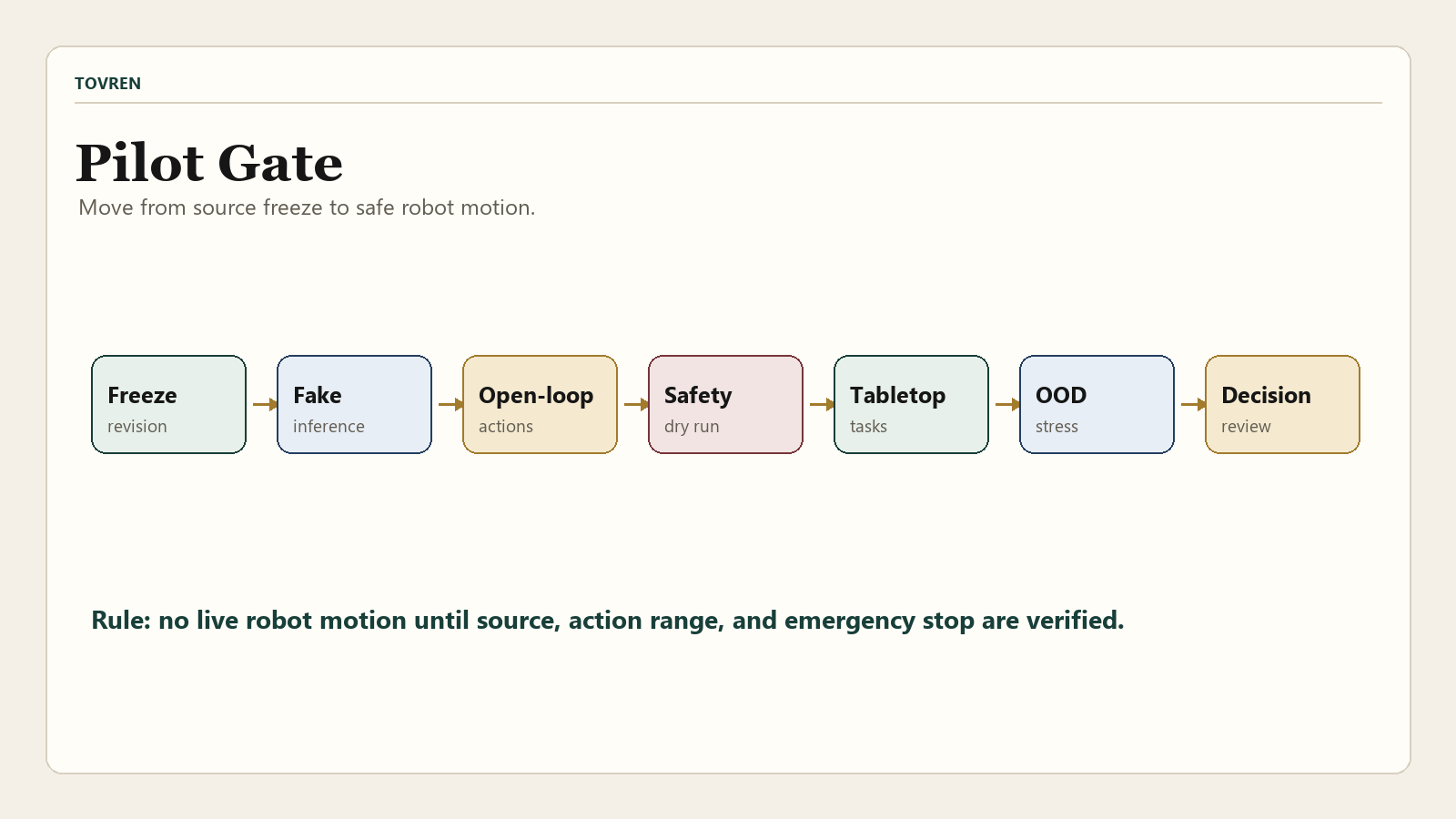
Start with a narrow pilot. The goal is not to prove that Wall-OSS-0.5 is generally intelligent. The goal is to decide whether it deserves more engineering time than your existing policy stack.
- Freeze the repository state. Record the GitHub commit, Hugging Face model revision, CUDA version, PyTorch version, FlashAttention version, and LeRobot commit before every run.
- Replicate a public-style tabletop task. Choose one semantic sorting task and one deformable or precision task. Avoid cherry-picking only the easiest case.
- Run open-loop inference before hardware motion. Validate shapes, dtypes, proprioception inputs, DOF masks, numerical stability, and action ranges.
- Measure latency end to end. Log camera capture, preprocessing, model forward pass, action decoding, controller handoff, and robot response time separately.
- Add safety before autonomy. Use a physical test cell, speed limits, collision boundaries, emergency stop, human exclusion zone, and supervised first-motion protocol.
- Score progress, not vibes. Use objective task cards with success, partial success, failure, unsafe motion, timeout, and recovery-needed labels.
- Preserve every failed run. A clean demo reel is less useful than a sortable archive of failures.
| First test | Pass signal | Fail signal | Decision |
|---|---|---|---|
| Local load and fake inference | Model loads reproducibly, produces stable outputs, and runs without dtype or dependency errors | Install breaks, outputs contain NaNs, or required modules are missing | Stop and fix environment before robot tests |
| Open-loop action playback | Actions are within expected robot limits and visually plausible against recorded observations | Action magnitudes, coordinate frames, or DOF mappings look wrong | Do not connect to hardware yet |
| Simple sorting task | Correct object selection and placement under minor scene variation | Instruction is understood but grasping, handoff, or placement fails repeatedly | Log as manipulation bottleneck, not language failure |
| Precision or deformable task | Progress remains measurable under object pose changes | Performance collapses outside the demo-like setup | Treat zero-shot claim as non-transferable for your use case |
| Latency and recovery test | Control loop meets safe timing budget and failure state is recoverable | High jitter, delayed actions, or unsafe continuation after perception errors | Block any unsupervised pilot |

Setup cautions builders should not skip
Wall-OSS-0.5 is not deployed by Hugging Face Inference Providers, so teams should plan for local execution or their own hosted inference environment. The public quick start includes installing Torch, TorchVision, Transformers, Hugging Face Hub, cloning the Wall-X repository, and loading Qwen2_5_VLMoEForAction.from_pretrained(“X-Square-Robot/wall-oss-0.5”). That verifies a model path. It does not replace a robot-safe inference server, a calibrated camera pipeline, controller integration, or a tested emergency-stop path.
The GitHub repository describes training and inference code for WALL open-source embodied foundation models, including data preparation through LeRobot, model configuration, flow-matching and FAST action branches, and evaluation utilities for real and simulated robots. Its environment references include Python 3.10, PyTorch, FlashAttention, LeRobot, CUDA, and Ubuntu 22.04. At the same time, a current repository news line says code for Wall-OSS-0.5 is coming soon, while the present setup and inference sections point to scripts such as fake_inference.py, draw_openloop_plot.py, and vqa_inference.py. Check the repository state before scheduling a hardware build.
| Area | Minimum question | Why it matters |
|---|---|---|
| Hardware | Which arm, gripper, cameras, force sensing, and controller rates are supported in your fork? | A VLA policy is only useful if its action representation maps safely to your robot |
| Compute | What GPU, VRAM, batch size, precision, and latency are measured? | A 4B VLA can be practical, but control latency and jitter matter more than parameter count |
| Data | Which of your task objects resemble the pretraining and fine-tuning distribution? | Open-world language does not eliminate embodiment and object-distribution mismatch |
| Evaluation | Can every task be repeated by another lab from a written task card? | Reproducibility is the difference between a demo and a usable benchmark |
| Safety | What happens on invalid action, perception dropout, collision proximity, or timeout? | Robot safety and a physical test cell are mandatory before real autonomy tests |
A 14-day pilot plan
A good Wall-OSS-0.5 pilot should be short, instrumented, and biased toward falsification. Do not spend two weeks making a demo look good. Spend two weeks finding the first hard failure.
| Day | Workstream | Output | Go/no-go rule |
|---|---|---|---|
| 1 | Source freeze | Commit hash, model revision, environment manifest, safety owner | No robot motion without manifest and stop plan |
| 2-3 | Environment setup | Local load, fake inference, dtype and numerical stability report | No hardware if model path is not reproducible |
| 4 | Open-loop evaluation | Recorded observations, predicted actions, range checks | No hardware if coordinate frames or DOF masks are unclear |
| 5-6 | Robot bridge | Controller adapter, rate limits, emergency stop, dry run | No autonomy if safety stop is not tested |
| 7-8 | Two baseline tasks | Sorting and placement task cards with 20 attempts each | Continue only if failure logs are complete |
| 9-10 | OOD perturbations | Lighting, object pose, distractors, camera shift, object substitutions | Mark as fragile if small perturbations collapse performance |
| 11-12 | Latency and recovery | End-to-end timing traces and recovery-state videos | No buyer demo if recovery is manual-only or unsafe |
| 13 | Comparison | Same tasks against existing policy, teleop baseline, or simpler imitation model | Continue only if Wall-OSS-0.5 beats a simpler baseline on something that matters |
| 14 | Decision review | Scorecard, failure taxonomy, engineering estimate, next experiment | Fund next phase only with measurable task advantage |

Failure modes that matter more than the highlight reel
The most valuable Wall-OSS-0.5 result will not be another successful grape, block, or ring demo. It will be a failure matrix that explains where the model breaks. Community discussion around the release is already asking the right practical questions: has anyone tried the checkpoint on real hardware, what fails out of distribution, and what is the latency on commodity hardware? Treat that as demand signal, not verified performance data.
| Failure mode | What it looks like | Likely cause | How to log it |
|---|---|---|---|
| Semantic miss | Chooses the wrong object or wrong target area | Instruction grounding or visual recognition error | Save prompt, frame, object labels, and chosen target |
| Pose miss | Understands the object but approaches from the wrong angle | Camera calibration, pose estimation, or action representation mismatch | Save camera extrinsics, end-effector pose, and action sequence |
| Contact failure | Pushes, slips, pinches, or drops the object | Gripper, compliance, force, or contact dynamics issue | Mark contact timestamp and include slow-motion video if available |
| Long-horizon drift | Early steps work, later steps accumulate errors | State tracking, recovery, or closed-loop correction weakness | Score progress by step, not only final success |
| Latency instability | Action comes late, jittery, or after the scene has changed | Compute bottleneck, preprocessing delay, or controller handoff issue | Log timing for every pipeline stage |
| Unsafe continuation | Robot keeps acting after invalid state, obstruction, or failed grasp | Missing watchdog, poor state validation, or absent recovery policy | Flag as safety-critical, not merely task failure |
How buyers should evaluate Wall-OSS-0.5
Buyers should not ask whether Wall-OSS-0.5 is impressive. Ask whether an integrator can make it boring. A useful automation model should run repeated tasks under agreed constraints, fail safely, expose logs, and beat a simpler baseline on cost, speed, flexibility, or changeover time.
For a warehouse buyer, the first paid pilot should focus on SKU handling variance, bin clutter, reflective packaging, picking speed, and recovery. For a manufacturing operations leader, the first pilot should focus on fixture tolerance, part orientation, repetitive cycle time, safety-rated integration, and downtime cost. For lab automation, the critical questions are contamination risk, vessel variability, calibration drift, and auditability.
| Reader type | Best next action | Stop condition |
|---|---|---|
| Robotics builder | Run local inference, then replicate one public-style task and one hard OOD task | Stop if action mapping or safety envelope cannot be verified |
| AI engineer | Profile model load, memory, throughput, and action decoding on available GPUs | Stop if latency cannot meet the robot control budget |
| Embodied AI researcher | Recreate task cards and publish raw success, partial progress, and failure logs | Stop claiming generalization without independent setup replication |
| Warehouse buyer | Ask vendors for task-specific pilots using your SKUs and failure reporting | Stop if only edited videos or aggregate success rates are offered |
| Manufacturing leader | Evaluate fixture-bound tasks with safety-rated integration and downtime analysis | Stop if the system cannot explain recovery and maintenance workflow |
This same discipline applies to other robotics foundation model claims. Tovren’s Genesis AI GENE-265 robotics foundation model buyer checklist covers broader procurement questions. For benchmark skepticism, the AI agent benchmark audit guide is relevant because the same trap appears in robotics: polished aggregate scores can hide narrow task design and missing failure disclosure. For teams building a continuous evaluation loop, the production-loop approach to agent improvement maps well to robot policies. For local compute planning, the local AI setup guide is a useful reminder that dependency control and hardware profiling matter before demos.
Source log
| Source | Date/access | URL | Why it matters |
|---|---|---|---|
| X Square Robot PRNewswire release | Published May 28, 2026; accessed May 30, 2026 | https://www.prnewswire.com/news-releases/x-square-robot-open-sources-wall-oss-0-5–bringing-pretrained-vla-performance-closer-to-post-training-levels-302784293.html | Primary announcement for open-source release, vendor-reported zero-shot scores, training mixture, fine-tuning claim, and stated release stack |
| Hugging Face model card | Accessed May 30, 2026 | https://huggingface.co/x-square-robot/wall-oss-0.5 | Model size, backbone description, quick start, no Inference Provider deployment, and loading example |
| Wall-X GitHub repository | Accessed May 30, 2026 | https://github.com/X-Square-Robot/wall-x | Repository scope, environment references, LeRobot setup, inference scripts, and caution that Wall-OSS-0.5 code state should be checked before builds |
| VLA-REPLICA arXiv paper | Submitted May 20, 2026; accessed May 30, 2026 | https://arxiv.org/abs/2605.20774 | Supports the need for accessible, reproducible, consistent real-world VLA benchmarks across independent labs |
| Reddit robotics discussion | Posted May 28, 2026; accessed May 30, 2026 | https://www.reddit.com/r/robotics/comments/1tq8myb/walloss05_is_an_open_vla_with_a_zeroshot_tabletop/ | Community-interest signal only: independent real-hardware testing, latency profiling, and failure reports are the questions practitioners care about |
Conclusion
Wall-OSS-0.5 deserves attention because it moves an embodied AI claim closer to something outsiders can inspect: open weights, a visible repository path, a model card, and a real-robot zero-shot benchmark claim. That is meaningful progress for the VLA field.
But the buyer-safe conclusion is simple: do not believe the zero-shot demo until it survives your hardware, your objects, your timing budget, and your failure logging. The winning Wall-OSS-0.5 article, pilot, or procurement memo should not say “robots are solved.” It should say which tasks were tested, what failed, how fast the loop ran, whether a simpler baseline lost, and whether the robot stopped safely when the model was wrong.