AI Benchmarks Are Broken: ABA Paper Guide
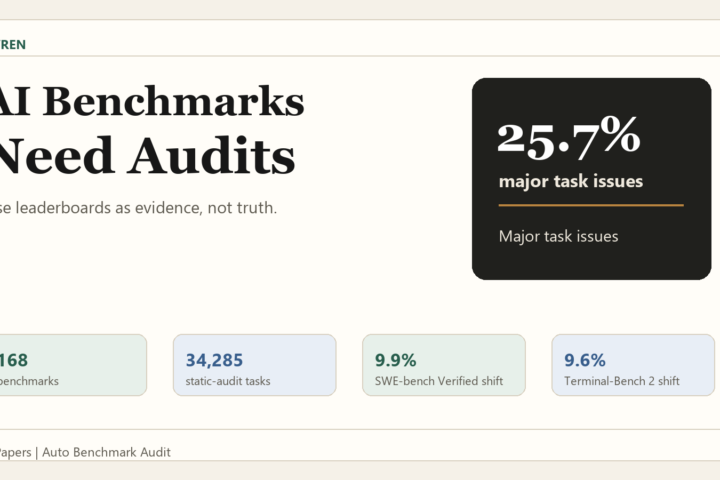
The ABA paper found major issues in 25.7% of audited AI benchmark tasks. Here is how to read model leaderboards without being fooled by flawed tasks.
Tovren Editorial
Editorial Archive
Plain-English analysis of important AI research papers, benchmarks, datasets, and methods, focused on what practitioners can actually use.
The ABA paper found major issues in 25.7% of audited AI benchmark tasks. Here is how to read model leaderboards without being fooled by flawed tasks.
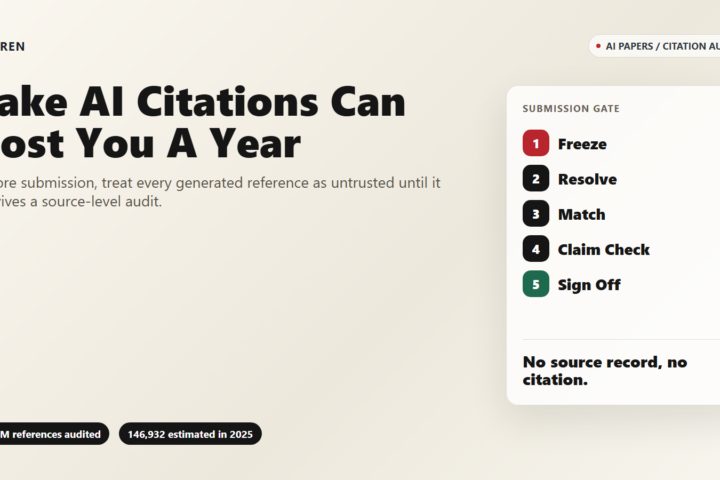
arXiv’s One-Year Penalty for Fake AI Citations: Run This Audit Before You Submit: a practical Tovren guide with direct recommendations, current source checks,
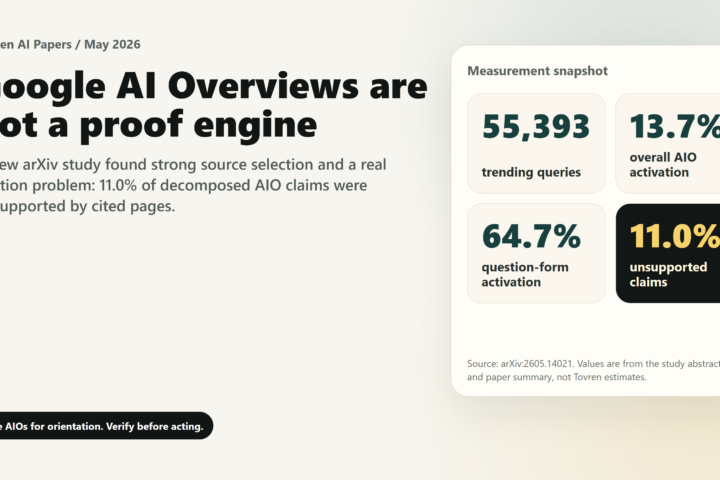
Google AI Overviews Paper: 11% Unsupported Claims and What Publishers Should: a practical Tovren guide with direct recommendations, current source checks, dec
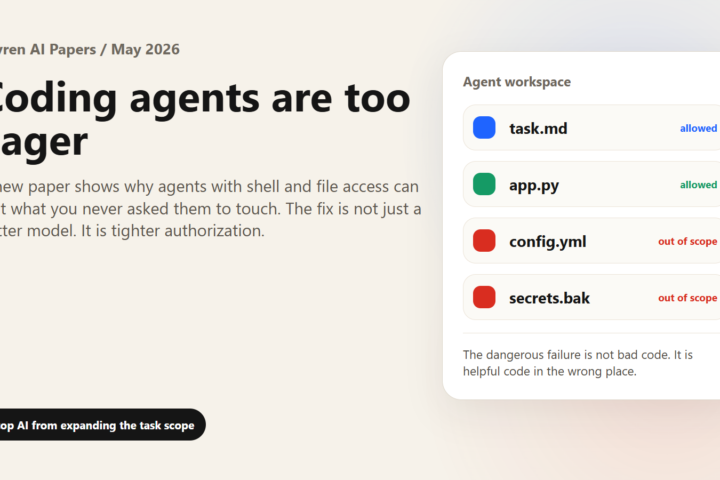
New Paper Warns Coding Agents Are Too: a practical Tovren guide with direct recommendations, current source checks, decision tables, and clear next steps for
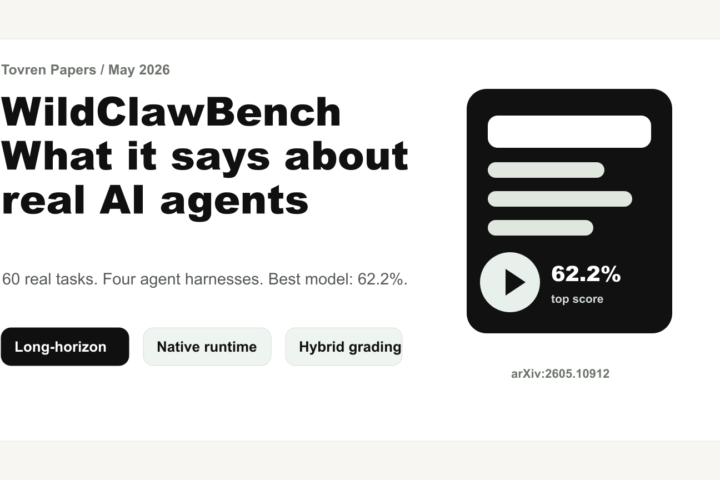
What WildClawBench measures, why long-horizon AI agents still fail, and how teams should use the benchmark before trusting agent demos.
SkillRet explained in practical terms: why AI agents fail to retrieve the right skills and what builders should test before deployment.
OccuBench Explained: Real-World AI Agent Benchmark: a practical Tovren guide with direct recommendations, current source checks, decision tables, and clear ne