
Short answer: if you are choosing one paid AI model in May 2026, start with Claude Opus 4.8 for premium coding, agentic work, and polished writing; GPT-5.5 for the broadest ChatGPT-style reasoning workflow; Gemini 3.1/3.5 when Google integration, speed, and price matter; and Qwen/Kimi/DeepSeek-class models when cost, local deployment, or open-weight flexibility matters more than a single benchmark crown.
| Use case | Best first pick | Why | Check before paying |
|---|---|---|---|
| Hard coding and agentic software work | Claude Opus 4.8 or GPT-5.5 | These are the models most worth testing first for multi-step engineering, code review, refactoring, and tool-use loops. | SWE-bench-style results, repository tests, tool-call reliability, and IDE integration. |
| General reasoning and daily assistant work | GPT-5.5 | It remains the safest default when the workflow lives inside ChatGPT, files, research, and mixed reasoning tasks. | Whether your plan exposes the exact reasoning mode used in benchmark claims. |
| Long documents, writing, and careful synthesis | Claude Opus 4.8 | Claude’s premium Opus line is especially strong when output quality, careful prose, and long-context review matter. | Context limits, fast-mode behavior, and cost on long prompts. |
| Google Workspace, Android, Search, and low-latency apps | Gemini 3.1/3.5 family | Gemini is the most natural first test when your workflow depends on Google surfaces or high-volume API economics. | Real latency, rate limits, citation quality, and whether Flash is enough. |
| Budget, local, or open-weight experimentation | Qwen, Kimi, or DeepSeek-class models | These models can win on value even when a closed frontier model wins the headline benchmark. | License, deployment complexity, tool-use support, and hidden hosting cost. |
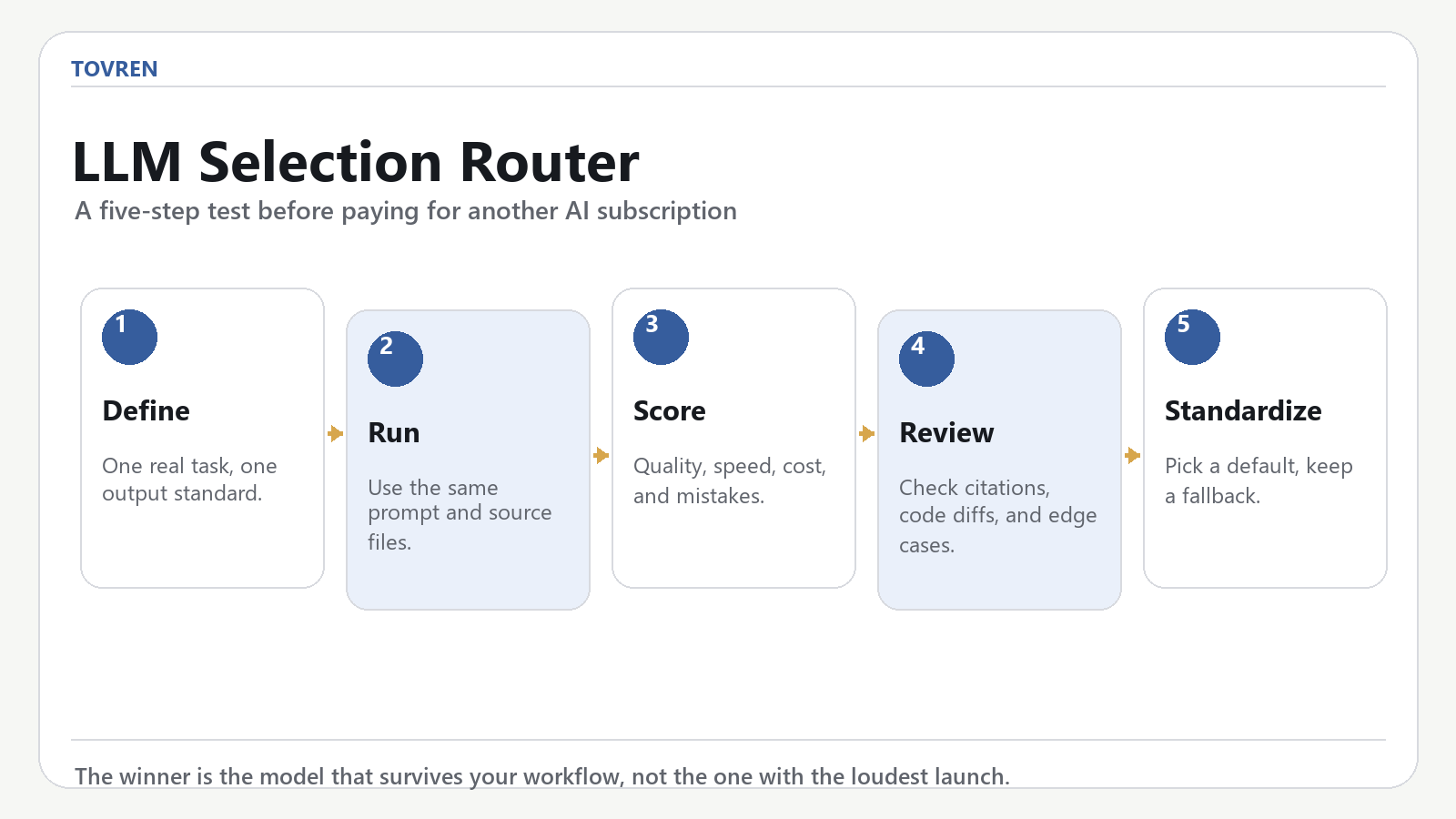
What changed in this update
This page was rebuilt because it was getting impressions but almost no clicks. The old version explained benchmark philosophy before answering the searcher’s question. That is backwards for a leaderboard query. This version gives the verdict first, then explains how to verify the ranking.
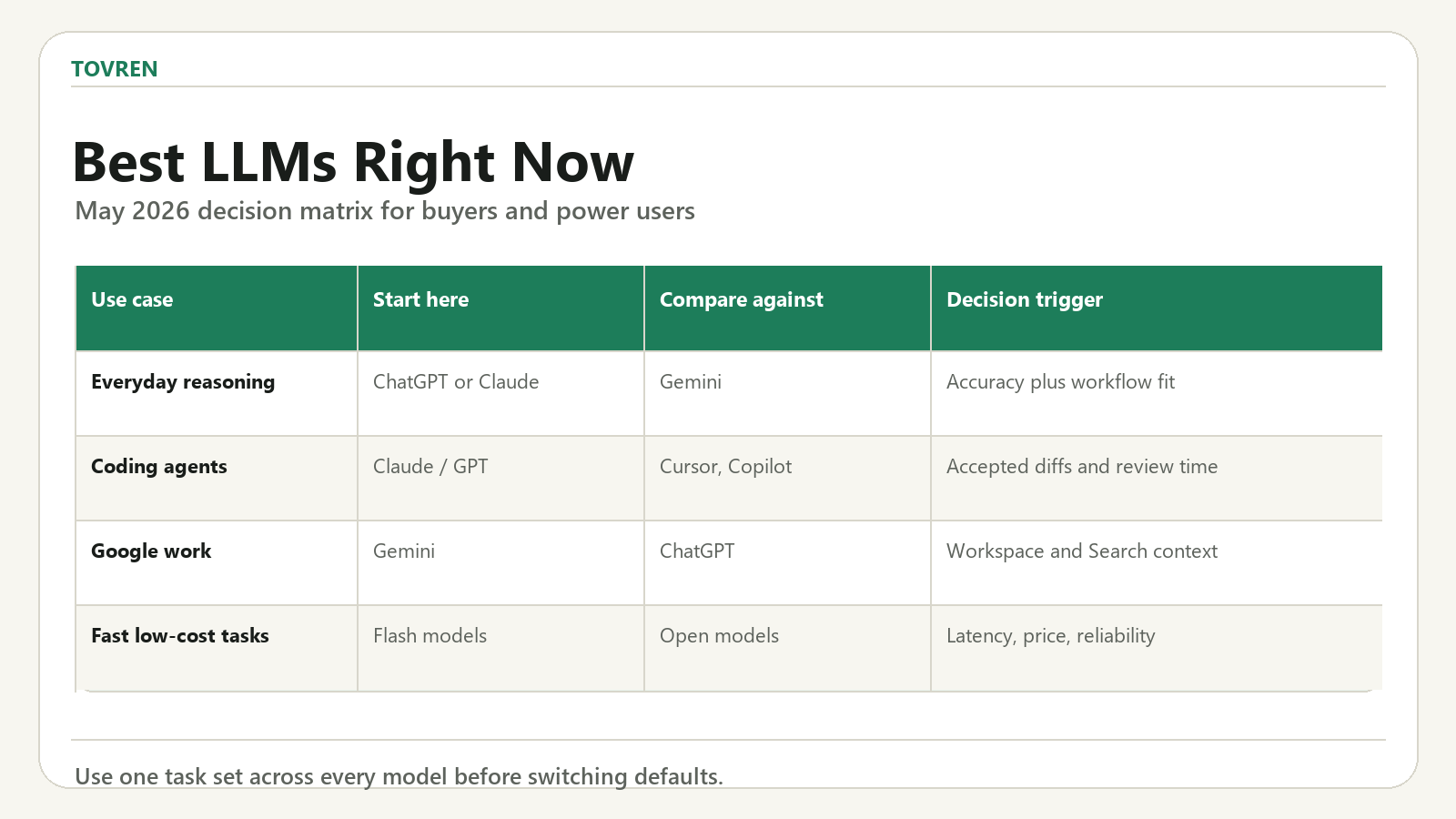
The important May 2026 shift is that the leaderboard is no longer a single ladder. Readers are searching for “current LLM leaderboard,” but they usually need one of four answers: the best model for coding, the best model for reasoning, the best model for writing, or the best model for value. A useful ranking must separate those jobs.
Current LLM leaderboard snapshot
Use this as a practical snapshot, not as a permanent scoreboard. Live leaderboards can change daily as vendors release new modes, post new benchmark runs, or adjust pricing.
| Tier | Models to check first | Best reason to use them | Main risk |
|---|---|---|---|
| Frontier premium | Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro | Highest ceiling for reasoning, agents, coding, and complex professional work. | Expensive, mode-dependent, and sometimes benchmark claims do not match your workflow. |
| Fast frontier | Gemini 3.5 Flash, faster Claude/GPT modes | High-volume search, support, summarization, extraction, and workflow automation. | Can look smart in demos but fail on long multi-step reasoning. |
| Developer value | Qwen3.7 Max, Kimi K2.6, DeepSeek-class models | Strong price/performance for coding, experimentation, and custom deployments. | Tooling, hosting, governance, and evaluation burden moves to your team. |
| Consumer default | ChatGPT, Claude, Gemini, Grok plans | Best when convenience, app ecosystem, file handling, and workflow memory matter more than raw leaderboard rank. | Subscription names often hide which underlying model or reasoning effort is being used. |
How to read Artificial Analysis
Artificial Analysis is useful because it aggregates difficult evaluation families and also tracks practical metrics such as speed and price. Do not read it as a buying order by itself. Read it as a capability screen: which models deserve hands-on testing before you spend money or migrate workflows.
The direct way to use it: shortlist the top capability models, then remove any model that is too slow, too expensive, unavailable in your product tier, or weak on your actual task. If a model only wins when using a high-effort mode that your team will not actually run, treat that result as a ceiling, not a default.
How to read LMArena
LMArena is useful because it reflects human preference across real prompts. That matters for writing, explanation quality, instruction following, and the kind of answer users actually like. But it is not the whole answer for enterprise work.
Human preference can reward style. Production workflows also need factuality, latency, cost, permissions, tool use, audit logs, and failure behavior. A model that feels better in chat may still be the wrong model for a finance workflow, legal workflow, coding agent, or high-volume customer support pipeline.
How to read coding benchmarks
For coding, do not buy from a general leaderboard alone. Use SWE-bench-style results, LiveCodeBench-style results, and your own repository tests. The public benchmark tells you which models are worth trying. Your own test suite tells you whether the model is safe for your codebase.
| Benchmark signal | Good for | Bad for | How to use it |
|---|---|---|---|
| Artificial Analysis Intelligence Index | Broad reasoning and frontier capability screening. | Choosing a workflow by price, app UX, or team constraints. | Use it to make the first shortlist. |
| LMArena | Human preference, answer quality, style, and general chat feel. | Audited enterprise workflows and cost-sensitive automation. | Use it to judge how users may perceive output quality. |
| LiveBench | Fresh reasoning tasks and contamination-resistant evaluation. | Predicting app UX or tool-call reliability. | Use it when a model claims general reasoning superiority. |
| SWE-bench / coding evaluations | Software engineering, issue fixing, and repository-level coding. | Writing, research, support, and business analysis. | Use it only with a repo-specific test run. |
The practical top 10 to test
If you need a working test list today, do not test 40 models. Test these groups first:
- Claude Opus 4.8 for premium coding, long-context synthesis, and polished output.
- GPT-5.5 for broad reasoning, ChatGPT workflows, and mixed file/research tasks.
- Gemini 3.1 Pro for Google-native workflows and high-end multimodal/reasoning tests.
- Gemini 3.5 Flash for fast, high-volume, cost-sensitive tasks.
- Qwen3.7 Max for developer value and non-US frontier competition.
- Kimi K2.6 for coding/value experiments and long-context comparisons.
- DeepSeek V4-class models where cost, speed, or deployment control matters.
- Claude Sonnet-class models for teams that want strong daily performance without Opus cost.
- GPT-5.4/older high-effort modes when stability matters more than the latest crown.
- Specialized local models when privacy, offline work, or custom infrastructure beats raw leaderboard rank.
Which model should you actually choose?
For most readers, the correct answer is not “use the number one model.” The correct answer is:
- Use Claude Opus 4.8 if output quality, coding depth, and long-form reasoning are worth the premium.
- Use GPT-5.5 if your workflow is already built around ChatGPT, files, projects, custom instructions, and broad reasoning.
- Use Gemini if your team lives in Google Workspace, Search, Android, or high-volume API workflows.
- Use Qwen/Kimi/DeepSeek-class models if you are optimizing for cost, control, or open deployment.
- Use a cheaper fast model for summarization, extraction, classification, and internal routing. Do not waste premium reasoning tokens on low-risk bulk work.
The buying checklist
| Question | Why it matters | Pass condition |
|---|---|---|
| Which exact model and reasoning mode are we using? | Benchmarks often use a stronger mode than the default app. | The vendor or product clearly exposes the model/mode you are paying for. |
| Does it beat our current workflow on real tasks? | A leaderboard win does not guarantee better work. | It wins on your own prompts, files, codebase, tests, and review criteria. |
| What is the cost at production volume? | Premium models can be cheap in demos and expensive in automation. | You calculate monthly cost using realistic input/output tokens. |
| Can we audit the output and tool calls? | Enterprise workflows need evidence, not only good answers. | Logs, permissions, citations, and review workflows are available. |
Bottom line
The current LLM race is close enough that “best model” is the wrong buying question. The right question is: which model is best for this workflow, at this cost, with this level of risk?
If you need one default, start with GPT-5.5 and Claude Opus 4.8 side by side. Add Gemini when Google integration or fast API economics matter. Add Qwen, Kimi, or DeepSeek-class models when cost and deployment control matter. Then judge the winner on your own tasks, not a screenshot of a leaderboard.
Related Tovren reading
- Best AI Subscription 2026: ChatGPT vs Gemini vs Claude vs Grok
- The AI Benchmark Leaderboard Is Splitting
- Best AI Coding Agents 2026
- Qwen3.7-Max After Launch
- Google Core Update Recovery Guide for AI Blogs
Source log
- Artificial Analysis evaluations for aggregate frontier-model capability signals.
- LMArena leaderboard for human-preference model comparison.
- LiveBench for contamination-resistant dynamic benchmark context.
- SWE-bench Verified dataset for software-engineering evaluation context.