Short answer: Anthropic’s May 28, 2026 Series H is a procurement signal, not a blank check. The practical move is to expand Claude only where Opus 4.8, Claude Code dynamic workflows, and Cowork can be tested against owned work with acceptance tests, budget caps, audit logs, and containment controls. Treat the $965B valuation as evidence that Anthropic is financing supply, compute, and enterprise distribution; treat your own pilot results as the evidence for spend.
Anthropic announced on May 28, 2026 that it raised a $65B Series H at a $965B post-money valuation. On the same date, it introduced Claude Opus 4.8, a new Opus model positioned around stronger coding, agentic work, professional collaboration, effort control, Claude Code dynamic workflows, and cheaper fast mode. Three days earlier, on May 25, 2026, Anthropic published a detailed engineering post about containing Claude across claude.ai, Claude Code, and Cowork.
For buyers, those items belong in one decision. Funding affects supply and enterprise support. Opus 4.8 affects workload quality. Dynamic workflows affect software throughput. Containment decides whether any of it can be deployed safely.
This checklist is for CFOs, founders, engineering leaders, AI platform owners, and power users deciding whether to buy more Claude, pilot Claude Code or Cowork, or wait. Pair it with Tovren’s Claude Opus 4.8 vs GPT-5.5 coding agents guide and Claude Code setup costs and workflow planning.
Confirmed facts: what changed on May 28, 2026
The facts below are the procurement-relevant parts of Anthropic’s announcement and product release. They should be separated from community reaction and Tovren analysis.
| Item | Confirmed fact | Buyer relevance |
|---|---|---|
| Funding | Anthropic said it raised $65B in Series H funding at a $965B post-money valuation on May 28, 2026. | Signals capital for compute, hiring, enterprise support, and product scale; does not prove ROI for your use case. |
| Round leadership | The round was led by Altimeter Capital, Dragoneer, Greenoaks, and Sequoia Capital. | Confirms major institutional backing; still requires vendor due diligence and contract review. |
| Revenue | Anthropic said run-rate revenue crossed $47B earlier in May 2026. | Suggests large commercial adoption; buyers should still request customer references in their sector. |
| Use of funds | Anthropic said the funding is expected to advance safety and interpretability research, expand compute, and scale Claude products and partnerships. | Directly relevant to availability, roadmap confidence, and enterprise support capacity. |
| Infrastructure | The round includes $15B of previously committed hyperscaler investments, including $5B from Amazon; infrastructure partners include Micron, Samsung, and SK hynix. | Memory, storage, cloud, and accelerator supply are now core procurement questions, not background trivia. |
| Compute agreements | Anthropic said it signed agreements for up to 5GW new capacity with Amazon, 5GW next-generation TPU capacity with Google and Broadcom, and access to SpaceX GPU capacity in Colossus 1 and 2. | For large deployments, ask how your workload is routed, metered, regioned, and supported across cloud channels. |
| Cloud availability | Anthropic said Claude is available on AWS, Google Cloud, and Microsoft Azure. | Enterprise buyers can compare direct, AWS, Google Cloud, and Azure procurement paths. |
Confirmed product update: Claude Opus 4.8
Anthropic’s May 28, 2026 Opus 4.8 release matters because it is not just a benchmark update. The release bundles model improvement with controls that affect day-to-day workflow design: effort control in claude.ai and Cowork, Claude Code dynamic workflows, and cheaper fast mode.
| Feature | Anthropic’s claim | How to test it |
|---|---|---|
| Opus 4.8 | Builds on Opus 4.7, improves benchmarks, is a more effective collaborator, and is available today for the same regular price. | Run the same 10 real tasks you used on Opus 4.7. Score correctness, self-correction, uncertainty, latency, and cost. |
| Regular API pricing | Anthropic listed unchanged regular pricing at $5 per million input tokens and $25 per million output tokens. | Estimate token cost per completed task, not per prompt. Include retries and review time. |
| Fast mode | Anthropic said fast mode can work at about 2.5x speed and is now three times cheaper than previous fast-mode pricing, with listed fast-mode pricing at $10 per million input tokens and $50 per million output tokens. | Use it for high-volume review, triage, and draft tasks; avoid assuming it is the best mode for high-risk changes. |
| Dynamic workflows | In Claude Code research preview, Claude can plan larger work, run hundreds of parallel subagents in one session, and verify outputs before reporting back. Anthropic says it is available in Claude Code for Enterprise, Team, and Max plans. | Test only on tasks with separable surfaces, real tests, clean rollback, and a written definition of done. |
| Effort control | Users can choose how much effort Claude puts into a response in claude.ai and Cowork; Anthropic says it is available on all plans, higher effort thinks more, and lower effort responds faster and uses rate limits more slowly. | Create a routing rule: low effort for simple transformations, high or extra effort for architecture, code changes, finance analysis, and long-running tasks. |
| API instruction update | The Messages API accepts system entries inside the messages array, allowing developers to update instructions mid-task without breaking prompt cache or routing through a user turn. | Useful for agent harnesses that adjust permissions, budgets, environment context, or risk state during execution. |
Tovren analysis: what the valuation does and does not change
The Series H changes supply-side risk. Anthropic is tying the raise to compute expansion, safety and interpretability research, and Claude product scale. That matters if your concern has been rate limits, cloud procurement, model availability, or enterprise support.
It does not change the buyer-side test. A $965B post-money valuation does not prove Claude Code will finish your migration, Cowork will fit your compliance model, or Opus 4.8 will reduce rework enough to justify spend. Run a tighter pilot if real work was blocked by model quality, latency, or orchestration limits.
Place Claude into your broader AI stack deliberately. Tovren’s business AI stack 2026 guide explains why most companies will not standardize on one model. A mature stack routes tasks by security boundary, data source, cost envelope, user skill, and evaluation result.

The practical buyer checklist
Use this as the first-pass decision screen before expanding Anthropic spend.
| Question | Buy or expand if… | Wait or limit if… | Action this week |
|---|---|---|---|
| Do we have work Claude is uniquely good at? | You have complex coding, migration, research, legal, finance, data, or document workflows with measurable acceptance criteria. | Your main use is generic chat, lightweight summarization, or undifferentiated writing. | Pick 3 high-value workflows and write a definition of done for each. |
| Can we measure cost per completed outcome? | You can track tokens, seats, retries, human review time, and error remediation. | You only track monthly subscription spend. | Create a per-task cost sheet before the pilot starts. |
| Can dynamic workflows be safely tested? | Your tasks can be split into independent workstreams with tests, fixtures, rollback, and code review. | The task is vague, has production secrets, lacks tests, or requires subjective judgment without review. | Start with one migration or bug sweep in a sandboxed repo. |
| Can business users safely use Cowork? | You have permission boundaries, logs, connector review, and data classification rules. | Users can connect sensitive systems without approvals or monitoring. | Define approved connectors and denied data classes before inviting users. |
| Can finance approve variable usage? | You can set budget caps by team, model, effort level, and task type. | Teams can run high-effort Opus jobs without visibility. | Separate low, high, extra, and max effort budgets. |
| Do we have a fallback model or workflow? | Critical processes can route to another model, a human queue, or an older workflow. | Claude becomes a single point of operational failure. | Document fallback paths for every pilot workflow. |
Buyer actions by role
| Role | What to do now | What not to do |
|---|---|---|
| Founder | Use Opus 4.8 and Claude Code on one revenue-adjacent workflow where speed matters and quality can be checked. | Do not replace human review on customer-visible output during the first pilot. |
| CFO | Approve a capped pilot with unit economics: cost per migrated file, closed ticket, analyst report, or completed PR. | Do not approve broad seat expansion because of the valuation alone. |
| Engineering leader | Test dynamic workflows against a repo with tests, branch protection, rollback, and reviewer ownership. | Do not let parallel subagents make production changes without clear merge gates. |
| AI platform owner | Build a routing policy for effort levels, model access, logs, connectors, and retention. | Do not let each team invent separate Claude usage rules. |
| Power user | Use effort control deliberately: low for quick transformations, higher effort for uncertain analysis and multi-step plans. | Do not treat higher effort as a universal default; it may spend more tokens than the task deserves. |
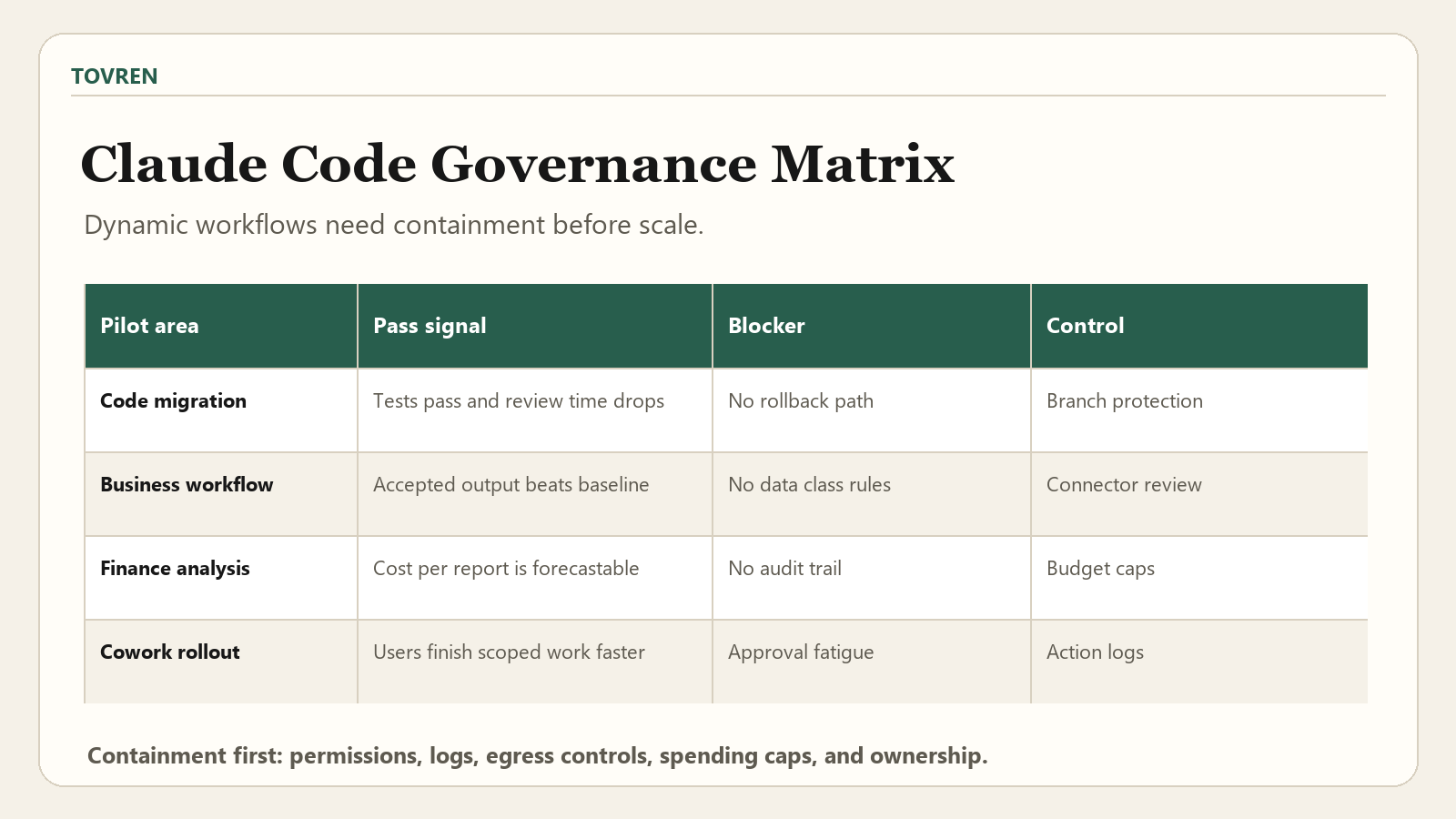
Governance checklist: agent containment before agent expansion
Anthropic’s May 25, 2026 containment post is the key non-financial source for buyers. Its warning: as agents become more capable, their blast radius grows. Anthropic emphasizes environment-layer boundaries, approvals, logs, isolation, egress controls, and risk caps across claude.ai, Claude Code, and Cowork.
Approval prompts are not enough. Anthropic said users approved roughly 93% of permission prompts in one Claude Code context. It also warned that allowlists act like capability grants: any function reachable through an allowed domain can become attack surface. Ask what the agent can access when trust fails.
| Control | Minimum requirement | Why it matters |
|---|---|---|
| Environment containment | Run Claude Code or Cowork pilots in sandboxed repos, VMs, containers, or restricted workspaces. | Limits damage from mistaken commands, prompt injection, tool misuse, or bad merges. |
| Permission boundaries | Grant only the files, branches, connectors, and APIs needed for the pilot task. | Reduces blast radius before relying on model behavior. |
| Egress controls | Control outbound destinations and treat allowlisted services as capability grants. | Prevents data leaving through permitted but unsafe paths. |
| Approval policy | Use human approval for high-impact actions, but do not depend on users reading every prompt perfectly. | Approval fatigue is a known failure mode. |
| Logs and observability | Capture prompts, tool calls, commands, file changes, connector use, approvals, and output artifacts where policy allows. | Needed for debugging, audit, incident response, and ROI analysis. |
| Risk caps | Set spending, runtime, file-change, branch, connector, and data-class limits. | Stops a pilot from becoming an uncontrolled production process. |
| Identity | Decide whether the agent acts as the user, a scoped service principal, or a separate agent identity. | Agent identity affects audit trails, revocation, least privilege, and compliance. |
For a full control-plane view, see Tovren’s AI agent control plane governance guide. If you are benchmarking agent behavior, also compare your internal results with the evaluation approach in WildClawBench AI agent benchmark 2026.
A 21-day pilot plan for Claude Opus 4.8 and Claude Code
| Phase | Days | Work | Exit criteria |
|---|---|---|---|
| Scope | 1-3 | Select one coding workflow and one business workflow. Write definitions of done, risk boundaries, budget caps, and fallback paths. | Every task has an owner, acceptance test, data boundary, and cost target. |
| Baseline | 4-6 | Run the current human or AI-assisted process without Opus 4.8 changes. Record time, cost, quality, and failure modes. | You know the real baseline, not a guessed productivity number. |
| Claude run | 7-13 | Run Opus 4.8 with effort levels documented. Test fast mode separately from high-effort work. Use Claude Code dynamic workflows only on separable tasks. | Outputs are reviewed, logged, and scored against the same baseline rubric. |
| Governance test | 14-17 | Attempt safe red-team prompts, bad inputs, connector misuse scenarios, and rollback drills. | The agent cannot exceed data, network, file, or spending boundaries. |
| Decision | 18-21 | Calculate cost per accepted outcome and review qualitative user feedback. | Expand only if quality improves, cycle time drops, risk controls hold, and finance can forecast usage. |
Community heat check
Community signal is useful for finding issues early, but it is not proof. On Reddit’s r/ClaudeCode, the launch post for Introducing Claude Opus 4.8 was reported at about +1253 votes, with discussion around same-day availability, fast mode, effort control, dynamic workflows, and the honesty benchmark. A separate dynamic workflows post was reported at about +57 votes and asked whether the feature feels bigger than benchmark deltas.
The takeaway: dynamic workflows may change perceived productivity when work can be decomposed. The risk is parallel mess if tasks lack acceptance tests, shared constraints, and verification. Treat community reaction as a pilot-design input, not deployment evidence.
Who should buy more Claude now?
Expand Claude spend if you have complex, high-value work that benefits from stronger agentic execution: codebase migrations, test-backed refactors, compliance document review, finance or legal analysis, data-heavy research, or internal automation. The best candidates have reviewers, measurable outputs, and high cost of delay.
Wait, or keep usage narrow, if you lack test coverage, audit logging, data classification, connector controls, or an AI incident owner. Opus-class models are valuable when judgment, context handling, and tool use change the outcome. They are wasteful as expensive autocomplete.
Source log
| Source | Date | Used for |
|---|---|---|
| Anthropic Series H announcement | May 28, 2026 | Funding amount, valuation, investors, revenue, compute, hyperscaler, infrastructure, and cloud availability claims. |
| Anthropic Claude Opus 4.8 announcement | May 28, 2026 | Opus 4.8 availability, pricing, fast mode, effort control, dynamic workflows, Messages API update, and product positioning. |
| Anthropic engineering: How we contain Claude across products | May 25, 2026 | Containment principles, blast radius framing, approval fatigue, allowlist risk, egress controls, logs, and agent identity. |
| Axios coverage of Anthropic fundraising | May 28, 2026 | Corroboration of Series H amount, valuation, round leadership, and market-context valuation comparison. |
| Reddit r/ClaudeCode: Introducing Claude Opus 4.8 | May 28, 2026 | Community signal around the launch, honesty discussion, same-day availability, dynamic workflows, fast mode, and effort control. |
| Reddit r/ClaudeCode: dynamic workflows discussion | May 28, 2026 | Community signal that dynamic workflows may feel larger than benchmark deltas for decomposable coding work. |
FAQ
Should we buy more Claude because Anthropic raised $65B?
No. The Series H improves confidence that Anthropic is investing in compute, safety, partnerships, and enterprise scale, but procurement should still depend on your pilot results, controls, and unit economics.
Is Claude Opus 4.8 worth testing if we already use Opus 4.7?
Yes, if you have real tasks where quality, self-correction, coding judgment, or agentic execution matter. Test it against your own Opus 4.7 baseline rather than relying on headline benchmarks.
What is the biggest buyer risk with Claude Code dynamic workflows?
The risk is uncontrolled parallel work. Dynamic workflows are promising for separable tasks, but they need tests, branch controls, clear acceptance criteria, logs, and rollback paths.
How should CFOs evaluate Opus 4.8 spend?
Measure cost per accepted outcome: completed PR, migrated file, reviewed contract, finished analysis, or resolved support case. Include token spend, seat costs, retries, human review time, and error remediation.
What governance controls should be in place before using Cowork or Claude Code broadly?
At minimum: scoped permissions, connector review, data classification, egress controls, audit logs, budget caps, approval policy, incident ownership, and fallback workflows.
Bottom line: Anthropic’s May 28, 2026 funding and Opus 4.8 launch make Claude more credible as an enterprise AI platform, but they do not remove the buyer’s job. The right move is a staged, governed pilot focused on expensive work with measurable outcomes. Expand only where Claude produces accepted work faster, safer, and at a cost finance can defend.