
Answer first: enterprises should test Cohere Command A+ when they need a privately deployable, Apache 2.0, multilingual and multimodal model for agent loops, RAG, document analysis, or sovereign AI programs. They should not treat it as a default replacement for closed hosted models until it passes their own task-success, latency, cost, safety, and operations tests under production-like load.
The practical decision is simple: run a two-week pilot if your workload contains sensitive data, strict residency requirements, high-volume agent calls, multilingual operations, or image-heavy enterprise documents. Wait if you only need occasional chat, do not have B200/H100-class infrastructure or a managed deployment path, or cannot staff model-serving, monitoring, red-team, and procurement work.
What Command A+ changes for enterprise buyers
Cohere released Command A+ on May 20, 2026 as an Apache 2.0 model aimed at enterprise agentic work, not just prompt-and-answer chat. The model ID is command-a-plus-05-2026. Cohere describes it as a Sparse Mixture-of-Experts model with 218B total parameters and 25B active parameters, a 128K input context, a 64K maximum generation length, text and image inputs, tool use, reasoning outputs, and support for 48 languages.
That bundle matters because many enterprise AI programs now have four overlapping requirements: private deployment, tool-using agents, multilingual coverage, and document understanding. Closed hosted models can still be the right answer, especially when teams value managed reliability and fast product iteration. Command A+ is worth testing when control, latency per agent step, data boundaries, and long-term inference economics matter enough to justify a real evaluation.
| Buyer question | Command A+ fact to check | Why it matters |
|---|---|---|
| Can we deploy it privately? | Apache 2.0 license, Hugging Face weights, Cohere Model Vault option | Supports sovereign or private AI strategies, but still requires operational review. |
| Can it run on realistic hardware? | Cohere lists 1 x B200 or 2 x H100s at W4A4 as a minimum profile | The minimum is not a production capacity plan; concurrency and context length can raise requirements. |
| Can it handle agentic workflows? | Tool use, reasoning, structured outputs, citations, and agentic-task positioning | Agent loops should be tested for task completion, retries, tool errors, and latency per action. |
| Can it handle global operations? | 48 languages and improved tokenizer efficiency claims for Arabic, Korean, and Japanese | Multilingual quality must be measured on company-specific documents and user intents. |
| Can it analyze documents? | Text and image inputs, multimodal document-processing positioning | Useful for invoices, forms, scanned pages, charts, tables, and mixed-language files. |
Who should test Command A+ now
Command A+ belongs on the shortlist for enterprises that already know why a hosted black-box model is not enough. The strongest candidates are organizations where data control, deployment locality, repeatable agent behavior, and high-volume inference economics are board-level issues rather than engineering preferences.
- Public sector and regulated industries that need private deployment, auditability, and jurisdictional control.
- AI platform teams building shared agent infrastructure across business units.
- Global enterprises with Arabic, Korean, Japanese, European-language, and mixed-language workflows.
- RAG-heavy teams that need long-context retrieval, citations, and controlled answer generation.
- Document automation teams processing forms, tables, charts, screenshots, or scanned business documents.
- Cost-sensitive agent builders where each user task may trigger many model calls and tool calls.
Who should wait
Do not test Command A+ just because it is new or open-weight. The model is large, the runtime plan is non-trivial, and the vendor benchmarks are not a substitute for your own workload results.
| Wait if… | Reason | Better next step |
|---|---|---|
| You only need basic assistant chat | The deployment and evaluation overhead may exceed the benefit. | Use an existing hosted model and revisit when volume or data constraints change. |
| You cannot access B200/H100-class capacity or Model Vault | The minimum hardware profile still implies serious infrastructure planning. | Start with API testing or the Hugging Face Space before infrastructure procurement. |
| You have no observability for agents | Agent failures are often caused by tools, state, retrieval, and policies, not only the model. | Build tracing and evaluation first; Tovren’s agent observability stack guide is a useful companion. |
| Your legal team has not reviewed Apache 2.0 model use | Open license does not remove security, privacy, procurement, or compliance obligations. | Run license, acceptable-use, data-handling, and indemnity reviews before production. |
| You need guaranteed current knowledge | Cohere docs list a knowledge cutoff of April 1, 2025. | Use RAG, verified tools, and freshness checks for current facts. |

The decision framework: when Command A+ earns a pilot
Use this rule: test Command A+ when at least two strategic constraints favor open-weight or private deployment, and at least one target workflow can be measured end-to-end in 14 days. Do not compare models only with generic benchmark screenshots. Compare them on a paid invoice, a policy search, a claims investigation, a procurement workflow, a multilingual support case, or a tool-using agent task your organization actually runs.
| Decision factor | Green light | Red flag | Metric to collect |
|---|---|---|---|
| Data control | Sensitive data cannot leave approved infrastructure | Hosted processing is already contractually acceptable | Data boundary map and retention proof |
| Agent workload | Tasks require tools, memory, retries, and multi-step plans | Mostly one-shot summarization | Task success rate and average model calls per task |
| Multilingual need | Production users operate in many languages | English-only internal assistant | Per-language accuracy, refusal, and escalation rates |
| Document load | Images, charts, tables, and scanned pages are common | Mostly clean text | Field extraction accuracy and citation correctness |
| Cost exposure | High call volume or long contexts make unit economics strategic | Low usage and low concurrency | Cost per successful task, not cost per token alone |
| Operations maturity | MLOps can serve, monitor, patch, and roll back models | No owner for model-serving incidents | SLO attainment and incident response time |
A 14-day enterprise pilot plan
The pilot goal is not to crown a universal winner. The goal is to decide whether Command A+ deserves production hardening for your workloads. Compare it against your current closed hosted baseline and, where relevant, one smaller open model. Keep prompts, retrieval indexes, tool definitions, and grading rubrics stable across candidates.
| Day | Workstream | Output | Pass criterion |
|---|---|---|---|
| 1 | Select three workflows | One agent loop, one RAG task, one document or multilingual task | Each workflow has known inputs, expected outputs, and failure labels. |
| 2 | Define evaluation set | 50-100 representative cases per workflow | Cases include easy, normal, adversarial, and edge examples. |
| 3 | Set baselines | Closed hosted model results and current production metrics | Baseline includes latency, cost, human corrections, and refusal behavior. |
| 4-5 | Run API and Space smoke tests | Prompt compatibility, image input checks, tool schema checks | No blocker in basic request/response, structured output, or citations. |
| 6-8 | Serve W4A4 in a test environment | vLLM or Transformers path documented | Stable generation under target context lengths and safe concurrency. |
| 9-10 | Agent loop tests | Tool-call traces, retry counts, task outcomes | Task success is within agreed margin of baseline or better on priority cases. |
| 11 | RAG and citation tests | Answer faithfulness, citation accuracy, abstention quality | Unsupported claims and bad citations stay below the risk threshold. |
| 12 | Multilingual and document tests | Per-language and per-document-type report | No critical degradation for regulated, customer-facing, or high-volume languages. |
| 13 | Security and governance review | License, logging, PII, red-team, access-control findings | No unresolved production blocker. |
| 14 | Buyer decision | Go, extend pilot, or stop | Decision is based on task success, cost per successful task, SLOs, and risk. |
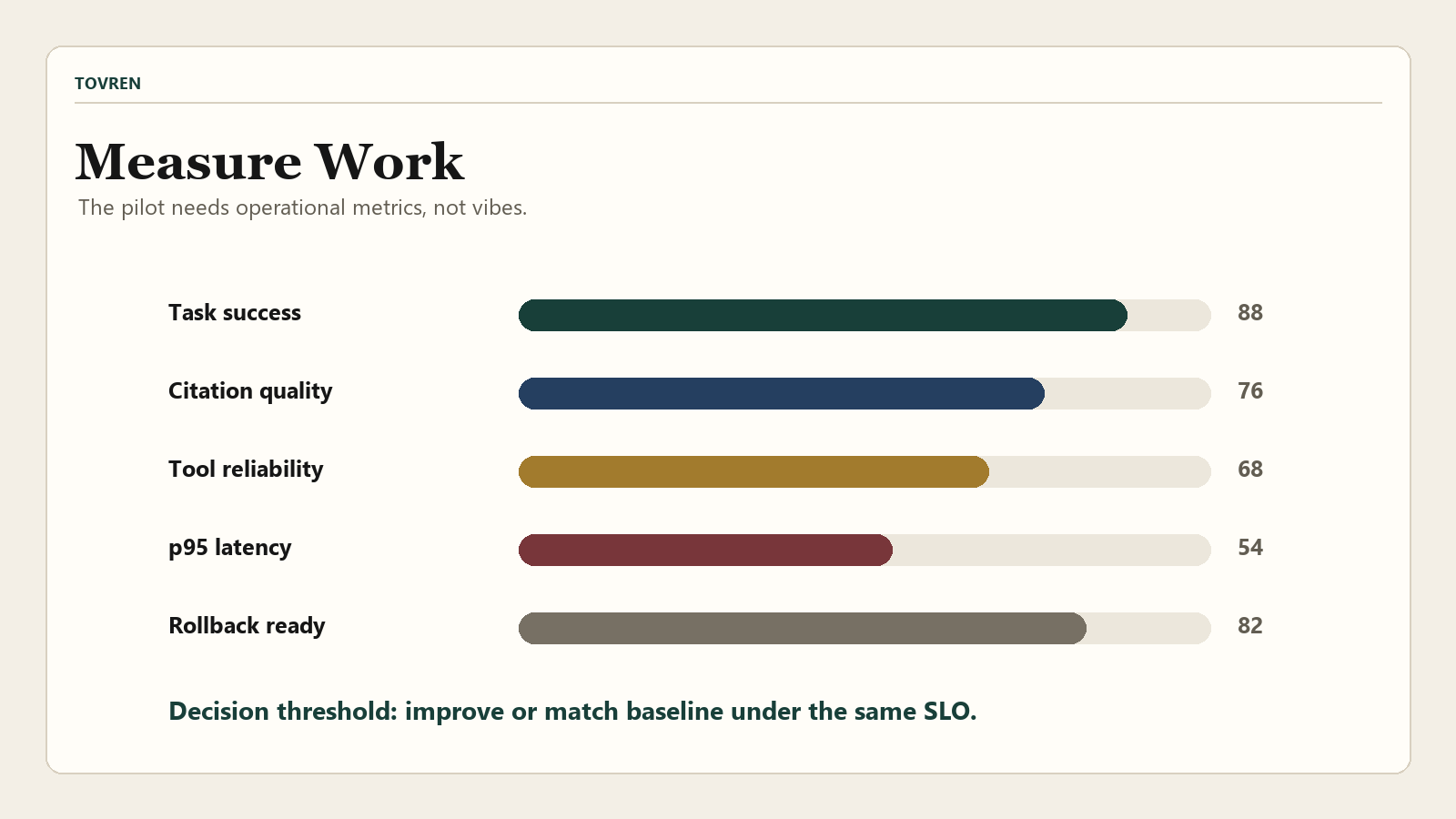
Benchmark plan: measure work, not vibes
Cohere reports strong gains versus Command A Reasoning, including 2-Bench Telecom moving from 37% to 85%, Terminal-Bench Hard from 3% to 25%, North Agentic QA improvement of 20%, spreadsheet analysis improvement of 32%, and memory usage quality of 54% versus 39%. Cohere also reports multimodal results including 63% on MMMU Pro, 75.1% on MMMU, 80.6% on MathVista, 52.7% on CharXiv reasoning, and an Artificial Analysis Intelligence Index score of 37. Treat those as screening signals. Cohere notes that the North application metrics use LLM-as-judge methods, so they should not be used as final procurement proof.
| Workload | Test cases | Primary metric | Failure labels |
|---|---|---|---|
| Agentic operations | Ticket triage, data lookup, workflow update, tool execution | Successful task completion without human rescue | Wrong tool, missing step, unsafe action, loop stall, bad state |
| RAG | Policy Q&A, contract search, technical support, audit evidence | Faithful answer with correct citations | Hallucination, unsupported citation, missed source, overconfident answer |
| Multilingual | Customer emails, internal policies, regional product docs | Per-language answer quality and escalation accuracy | Translation drift, code-switch failure, tone error, jurisdiction error |
| Multimodal documents | Invoices, forms, tables, charts, scanned PDFs, screenshots | Field accuracy and reasoning correctness | OCR miss, table confusion, chart misread, invented field |
| Long context | 100K-token dossiers, case files, board packs | Recall, synthesis, and citation accuracy | Lost instruction, stale context, wrong section, unsupported synthesis |
| Latency and throughput | Concurrent users and agent steps under load | p50/p95 latency, time to first token, output tokens per second | SLO breach, memory pressure, queue growth, timeout |

Self-hosting checklist
Cohere lists vLLM and Transformers support, and the Hugging Face W4A4 model card includes image-text-to-text and vLLM examples using CohereLabs/command-a-plus-05-2026-w4a4. That does not make deployment trivial. A 218B total-parameter MoE model is still a large operational object, even when only 25B parameters are active and W4A4 reduces the serving footprint.
| Checklist item | Minimum decision | Owner |
|---|---|---|
| Deployment path | Choose Cohere API, Model Vault, Hugging Face trial, or self-hosted serving | AI platform lead |
| Quantization | Start with W4A4 for hardware feasibility; compare BF16/FP8 only if quality requires it | ML engineer |
| Hardware | Validate 1 x B200 or 2 x H100 minimum against your concurrency, context, and SLO targets | Infrastructure lead |
| Runtime | Test vLLM first if your stack already uses OpenAI-compatible serving; test Transformers for integration flexibility | MLOps engineer |
| Observability | Log prompts, retrieved chunks, tool calls, model outputs, latency, retries, and evaluator results | Platform team |
| Rollback | Keep the current hosted model or earlier production model as a fallback route | Service owner |
| Security | Review model file provenance, access controls, network egress, secrets, and audit logging | Security team |
Cost and hardware checklist
Do not compare Command A+ to closed hosted models using list prices alone. For agentic systems, the meaningful metric is cost per successful task under an SLO. That includes model calls, long-context tokens, retrieval, reranking, tool execution, failed retries, human review, GPU utilization, platform labor, and incident handling.
- Measure p50 and p95 latency for each agent step, not only final answer latency.
- Track average and worst-case output length, especially because Command A+ supports up to 64K output tokens.
- Measure long-context memory pressure at 32K, 64K, and 128K input sizes.
- Separate smoke-test speed from sustained throughput over several hours.
- Compare W4A4 results against a small BF16 or FP8 sample only if the workload is sensitive to quantization artifacts.
- Include engineering labor and operations ownership in the model TCO.
Cohere says Command A+ delivers 63% higher output tokens per second and 17% lower time-to-first-token than Command A Reasoning at the same quantization and concurrency settings; W4A4 adds 47% more speed and 13% lower latency; speculative decoding adds another 1.5-1.6x inference speedup. These claims are useful for sizing a pilot, not for signing a production business case without your own load test.
Do not assume this
- Do not assume Command A+ beats every closed hosted model. Test it against your current baseline.
- Do not assume Apache 2.0 means risk-free deployment. Legal, security, privacy, procurement, and model-governance reviews still apply.
- Do not assume W4A4 is always quality-neutral. Cohere says quality degradation is virtually absent in practice, but sensitive tasks should be tested.
- Do not assume long context solves retrieval. RAG still needs chunking, ranking, citations, freshness, and abstention behavior.
- Do not assume model benchmarks predict agent performance. Tool schemas, memory, state, retries, and permissions can dominate outcomes.
- Do not assume free API access means free production. Cohere docs say Command A+ is free until rate limits are reached, while production through Model Vault is available; production economics must be negotiated and measured.
Closed hosted model comparison checklist
Command A+ should be compared with closed hosted models as a system choice, not a brand contest. For a broader procurement baseline, pair this test with Tovren’s AI subscription pricing guide, the continuous agent improvement loop, and the open model test-plan pattern.
| Question | Command A+ evidence needed | Closed hosted evidence needed |
|---|---|---|
| Which completes our workflow? | End-to-end task success on private eval cases | Same eval cases, same prompts, same tools where possible |
| Which is cheaper at scale? | GPU, utilization, operations, and failed-retry costs | Contract price, token usage, rate limits, and overage rules |
| Which is safer? | Policy compliance, red-team results, refusal quality, audit logs | Provider controls, data terms, logs, retention, indemnity, audit rights |
| Which is easier to operate? | Serving stability, patch process, rollback, monitoring | Provider SLA, incident transparency, admin tooling, integration support |
| Which supports sovereignty? | Private deployment, region control, model-file governance | Available regions, private cloud options, contractual data controls |
Risk controls for enterprise pilots
Before any production rollout, connect model evaluation to governance. For agents, require scoped tool permissions, dry-run modes for high-impact actions, human approval for irreversible steps, and trace-level observability. For RAG, require source-grounded answers, refusal when evidence is missing, and separate freshness checks for time-sensitive claims. For document analysis, require confidence scoring, human review thresholds, and sampling audits. For local or sovereign deployments, use the same discipline you would apply to any critical infrastructure component: version pinning, access control, vulnerability review, monitored egress, backup routing, and incident playbooks.
Teams building smaller local systems can compare the operational contrast with Tovren’s local AI setup guide. Command A+ is in a different infrastructure class, but the same lesson applies: a model is not a product until deployment, monitoring, evaluation, and rollback are solved.
Source log
| Source | Date/access | URL | Why it matters |
|---|---|---|---|
| Cohere official blog | Published May 20, 2026; accessed May 30, 2026 | https://cohere.com/blog/command-a-plus | Primary source for release date, model architecture, size, license, context, modalities, languages, hardware minimum, quantization, speed claims, and benchmark claims. |
| Cohere Command A+ documentation | Accessed May 30, 2026 | https://docs.cohere.com/docs/command-a-plus | Primary source for model ID, capabilities, pricing note, API endpoints, context, max output, knowledge cutoff, and production availability through Model Vault. |
| Cohere release notes | May 20, 2026 entry; accessed May 30, 2026 | https://docs.cohere.com/changelog | Primary source confirming standard API availability, Command A family positioning, MoE status, and throughput/latency positioning. |
| Hugging Face model card | Accessed May 30, 2026 | https://huggingface.co/CohereLabs/command-a-plus-05-2026-w4a4 | Primary distribution source for W4A4 model card, files, license label, and implementation examples for image-text-to-text and vLLM serving. |
| Reddit community discussion | Accessed May 30, 2026 | https://www.reddit.com/r/LovingAIAgents/comments/1tjhc09/cohere_introducing_cohere_command_a_weve_created/ | Used only as a community-interest signal that practitioners care about agent-loop steadiness and speed, not as verified technical evidence. |
Conclusion
Command A+ is not an automatic replacement for closed hosted models. It is a serious enterprise candidate when the problem is private, multilingual, multimodal, agentic, or sovereignty-driven enough to justify a controlled pilot. The right question is not whether it is the “best model.” The right question is whether Command A+ can complete your workflows with acceptable quality, latency, cost per successful task, safety behavior, and operational burden. If it can, it deserves a production hardening plan. If it cannot, the pilot still pays for itself by clarifying what your enterprise actually needs from open-weight AI.