
Short answer: do not switch your whole coding team to Claude Opus 4.8 today. Pilot it first. Use it on hard codebase navigation, multi-file refactors, agentic bug fixing, and tasks where GPT-5.5 or your current Copilot setup keeps missing context. Keep GPT-5.5 in the comparison set for terminal-heavy work, general reasoning, and workflows already tuned around ChatGPT or Codex.
| Decision | Use Claude Opus 4.8 when | Keep GPT-5.5 / current default when | Proof required |
|---|---|---|---|
| Team default | Opus wins on your repo with fewer bad diffs and less review correction. | Your existing model already passes tests faster and cheaper. | 10 real issues, same prompt, same tests, measured cost. |
| Claude Code pilot | You need long-running migrations or large-codebase exploration. | You mainly run short edits, explanations, or small PRs. | Merge rate, rollback rate, tool-call count, reviewer time. |
| GitHub Copilot users | Your org can enable the model policy and absorb premium multipliers. | Developers do not need Opus-level reasoning for routine work. | Usage reports and accepted-change cost after rollout. |
| High-risk code | You add human review, tests, and rollback before merge. | You cannot inspect generated changes carefully. | Security review and test evidence, not model confidence. |

What actually shipped
Anthropic released Claude Opus 4.8 on May 28, 2026. The release matters because it is not only a model swap. Anthropic also introduced effort control for claude.ai and Cowork, dynamic workflows for Claude Code, and cheaper fast mode pricing compared with the previous fast mode setup.
The practical details are the ones buyers should care about. Regular Opus 4.8 pricing is unchanged from Opus 4.7 at $5 per million input tokens and $25 per million output tokens. Fast mode is listed at $10 per million input tokens and $50 per million output tokens, and Anthropic says fast mode can work at 2.5x speed while being three times cheaper than previous fast mode. Developers can call the model as claude-opus-4-8.
GitHub also moved quickly. Its May 28 changelog says Claude Opus 4.8 is generally available in GitHub Copilot for Pro+, Business, and Enterprise users. It can appear across VS Code, Visual Studio, Copilot CLI, GitHub Copilot cloud agent, GitHub Mobile, JetBrains, Xcode, Eclipse, and github.com. Business and Enterprise admins need to enable the policy. GitHub also notes a 15x premium request multiplier until usage-based billing launches on June 1, 2026.
The GPT-5.5 baseline
GPT-5.5 is not a weak default. OpenAI’s GPT-5.5 launch page positions it as a frontier model for agentic coding, computer use, knowledge work, and long-running tool workflows. The current GPT-5.5 API model page lists a 1,050,000 token context window, reasoning effort support from none through xhigh, and API pricing of $5 per million input tokens, $0.50 per million cached input tokens, and $30 per million output tokens.
That means the real question is not “which model is smarter in a press release?” The useful question is narrower: which model turns your actual repository issues into accepted changes with less review burden and lower total cost?
| Comparison point | Claude Opus 4.8 | GPT-5.5 | Decision rule |
|---|---|---|---|
| Best first test | Large-codebase navigation, migrations, Claude Code dynamic workflows. | Terminal-heavy Codex tasks, tool-heavy agents, long-context professional work. | Run both on the same 10 issues before changing defaults. |
| Listed API price | $5/M input and $25/M output for regular use; fast mode costs more but is faster. | $5/M input, $0.50/M cached input, and $30/M output on OpenAI’s model page. | Compare cost per accepted change, not input price alone. |
| Access path | Claude API, Claude Code, Claude plans, and GitHub Copilot rollout. | ChatGPT, Codex, and API availability with OpenAI safeguards and usage rules. | Choose the model that fits your team’s governance and audit process. |
| Risk control | Use effort control, admin policy, test gates, and review before merge. | Use reasoning effort, tool logs, evals, and repository-specific prompts. | Block either model from autonomous production changes without review evidence. |
Why people are arguing about it
The launch hit exactly where developers are already sensitive: coding agents are expensive, flaky, and suddenly useful enough that teams cannot ignore them. Community threads on Claude Code and ChatGPT are mostly debating four things: whether Opus 4.8 fixes Opus 4.7 reliability complaints, whether it beats GPT-5.5 on real code, whether fast mode changes the cost math, and whether premium model usage limits make the upgrade less attractive in practice.
Treat that community reaction as a demand signal, not proof. Reddit comments can show what users are testing and complaining about, but they are not a benchmark. For hard claims, rely on Anthropic’s system card, GitHub’s Copilot changelog, and your own controlled repo tests.
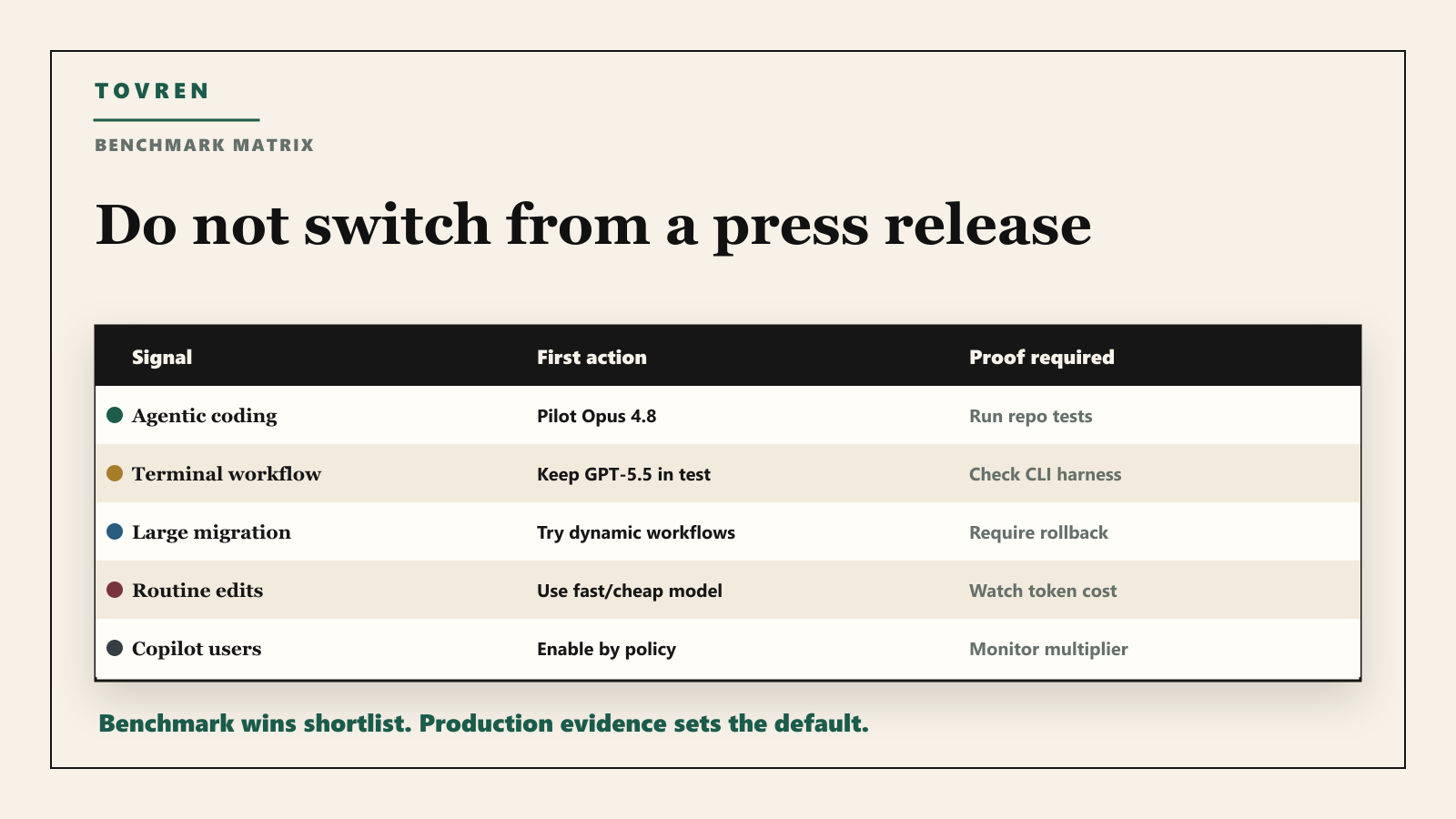
The benchmark claim is not enough
Anthropic’s release page says Opus 4.8 improves across coding, agentic skills, reasoning, and knowledge-work evaluations. It also highlights better honesty: the model is described as more likely to flag uncertainty and less likely to let flaws in its own code pass without comment. That is the right direction for agentic coding, because the worst coding agent is not the one that fails loudly. It is the one that confidently ships a bad patch.
But a benchmark table does not answer whether your team should switch. Coding benchmarks vary by harness, scaffolding, allowed tools, token budget, and model effort. Anthropic’s own footnotes point to harness differences on Terminal-Bench 2.1, including a separate reported GPT-5.5 score with the Codex CLI harness. That is exactly why teams should avoid screenshot-driven procurement.
| Claim to verify | Why it matters | How to test it |
|---|---|---|
| Better code judgment | Agents must catch bad plans and suspicious diffs before a human does. | Give both models ambiguous issues and score pushback quality. |
| Large-codebase navigation | Most agent failures come from missing project context, not syntax. | Use issues that require reading multiple directories and tests. |
| Fast mode economics | A faster premium model can still be the wrong default if it burns budget. | Track cost per accepted PR, not cost per prompt. |
| Copilot availability | Easy access can create uncontrolled premium spend. | Enable policy for a pilot group before org-wide rollout. |
Who should test Opus 4.8 first
1. Teams doing migration work. Dynamic workflows are the most interesting part of the release for engineering managers. Anthropic says Claude Code can plan work, run many parallel subagents, verify outputs, and handle codebase-scale migrations with the test suite as the bar. If your backlog has framework upgrades, dependency migrations, API rewrites, or test modernization, this is where Opus 4.8 deserves a pilot.
2. Teams already paying for premium coding agents. If your engineers are already using GPT-5.5, Opus 4.7, Cursor, Copilot premium models, or Claude Code Max/Team/Enterprise, Opus 4.8 is worth testing because the marginal comparison is real. If your team still uses free chatbots for occasional snippets, Opus 4.8 is probably not the next step.
3. Teams with painful review overhead. The strongest reason to test Opus 4.8 is not that it writes more code. It is whether it produces fewer review comments, catches bad assumptions earlier, and avoids unexplained changes. That reduces the hidden cost of agentic coding.
Who should wait
Wait if your coding-agent process is not measured. If you do not track accepted diffs, failed tests, revert rate, reviewer time, and token cost, switching models will only create opinions. Measure first.
Wait if your work is mostly small edits. A premium Opus model is overkill for routine summarization, comments, small CSS tweaks, and obvious test additions. Route those to cheaper models or fast modes.
Wait if your company cannot control access. GitHub’s Copilot rollout includes admin policy controls for Business and Enterprise. Use them. A 15x premium multiplier is manageable in a pilot and dangerous as an invisible default.
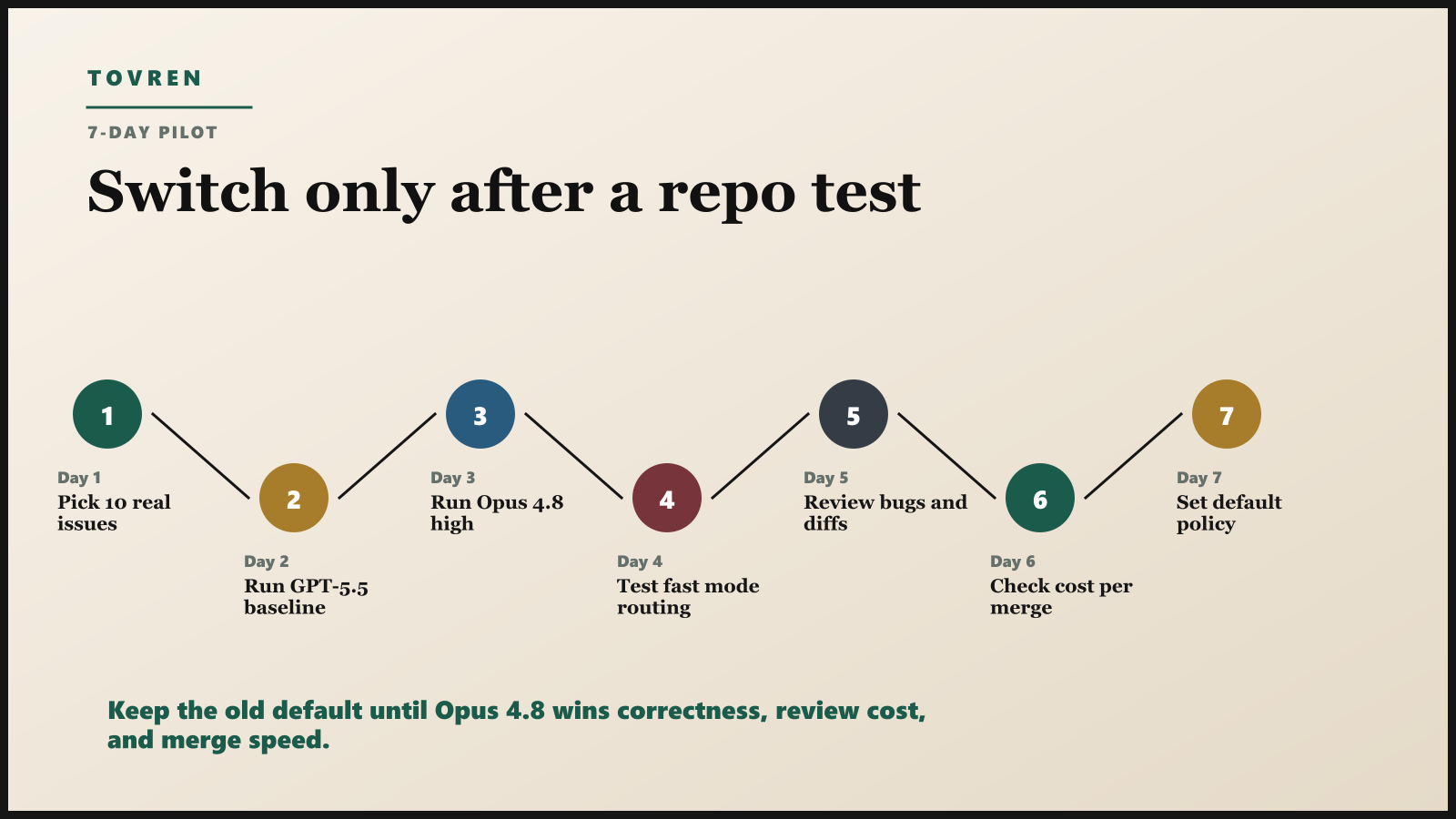
A practical 7-day pilot
Day 1: Pick 10 real issues. Use closed or internal issues from your own repo. Include at least three multi-file tasks, two failing-test tasks, two refactors, one security-sensitive task, one documentation task, and one ambiguous product request.
Day 2: Run your current default. Use GPT-5.5, Copilot, Cursor, or whatever the team already trusts. Save prompts, diffs, tool calls, test results, review notes, elapsed time, and token cost.
Day 3: Run Opus 4.8 high effort. Use the same issue descriptions and constraints. Do not let the operator give one model extra context that the other model did not receive.
Day 4: Test fast mode routing. Put low-risk tasks through fast mode or cheaper models. Save Opus 4.8 high effort for risky or complex work. The goal is a router, not a fan club.
Day 5: Review bad diffs. Count hallucinated APIs, out-of-scope edits, unnecessary rewrites, missed tests, broken style conventions, and security-sensitive mistakes.
Day 6: Calculate cost per accepted change. Do not compare token price alone. Compare cost per accepted PR after review. A model that costs more per token can still be cheaper if it saves reviewer time and avoids rework.
Day 7: Set policy. Decide where Opus 4.8 becomes allowed, where it becomes recommended, and where it remains blocked. Publish a short internal rule: which tasks get premium reasoning, which use fast mode, and which require human approval before merge.
| Pilot metric | Good signal | Bad signal |
|---|---|---|
| Accepted-change rate | More diffs merged without major rewrite. | Large impressive diffs that reviewers reject. |
| Review correction time | Reviewer spends less time explaining obvious mistakes. | Reviewer must inspect every line because the agent over-edits. |
| Test pass rate | Model runs or respects existing tests and fixes failures. | Model claims success without evidence. |
| Scope discipline | Patch stays inside requested files and behavior. | Agent rewrites adjacent systems without approval. |
| Cost per merge | Higher model cost is offset by fewer retries. | Premium model becomes the default for cheap routine work. |
The cost gate
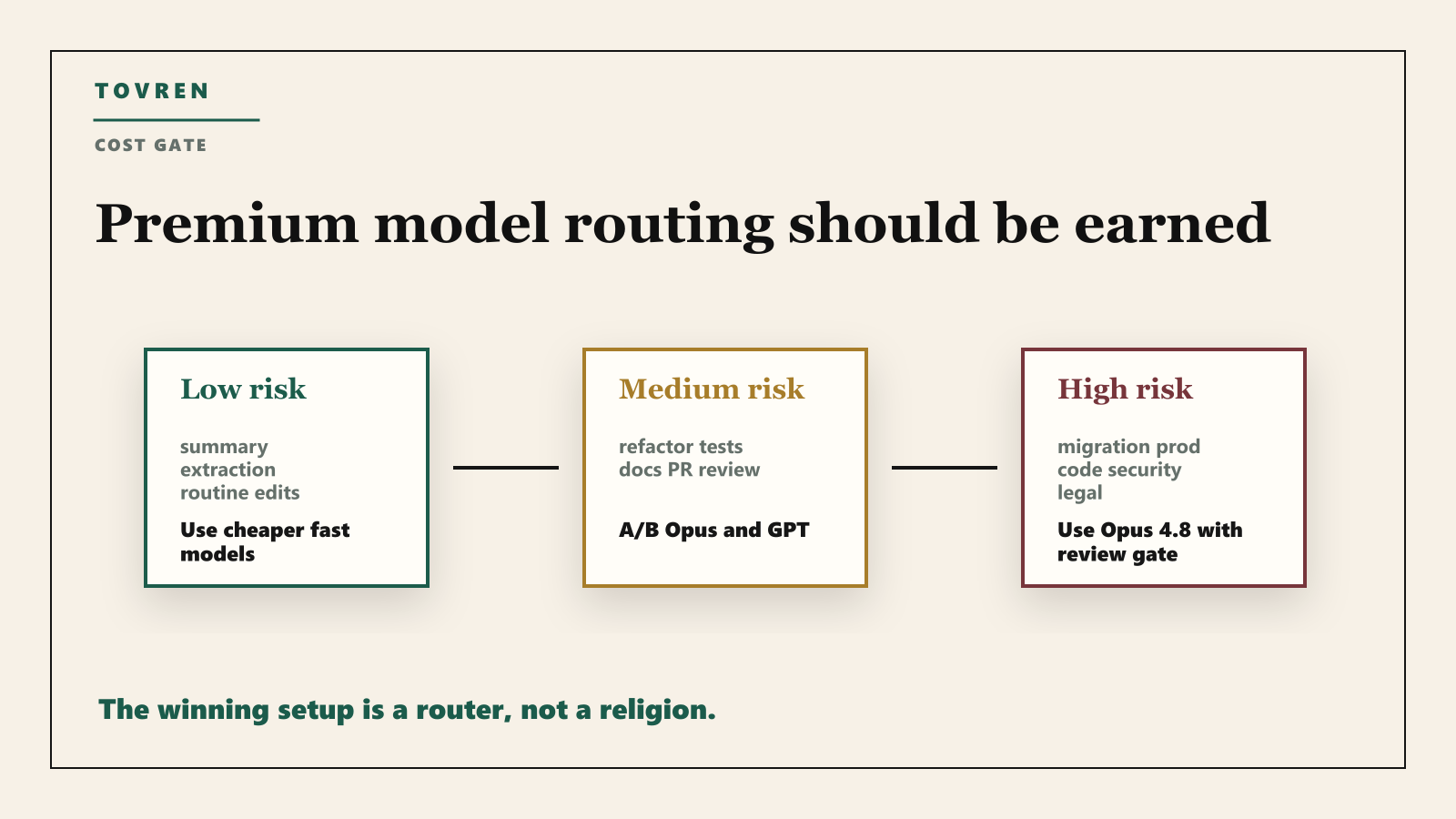
The fastest way to waste money is to make Opus 4.8 the default for every prompt. The better pattern is routing. Use cheaper models for low-risk work, use fast mode for routine but volume-heavy coding support, and reserve Opus 4.8 high or extra effort for tasks where mistakes are expensive.
| Task type | Recommended route | Reason |
|---|---|---|
| Summaries, small docs, simple explanations | Cheaper fast model | Low risk and easy to review. |
| Routine bug fix with narrow failing test | Fast mode or current default | Premium reasoning is not always needed. |
| Multi-file refactor or migration | Claude Opus 4.8 pilot | This is where better context handling can matter. |
| Security-sensitive production change | Opus 4.8 plus human gate | The model can help, but review evidence is mandatory. |
Bottom line
Claude Opus 4.8 is a serious coding-agent release. The combination of better agentic claims, effort controls, dynamic workflows, GitHub Copilot availability, and cheaper fast mode makes it worth testing immediately. But it does not automatically replace GPT-5.5 or your current coding-agent setup.
The right move is direct: run a 7-day pilot on real issues. If Opus 4.8 produces better accepted diffs with less review pain and acceptable cost, promote it for complex coding and migration work. If it only wins on vibes or benchmark screenshots, keep it as an option, not the default.
Related Tovren reading
- Current LLM Leaderboard May 2026
- Best AI Coding Agents 2026
- Claude Code Models, Usage and Limits
- AGENTS.md Prompt Pack for Coding Agents
- GH-600 Agentic AI Developer Certification Guide
Source log
- Anthropic: Introducing Claude Opus 4.8
- GitHub Changelog: Claude Opus 4.8 in GitHub Copilot
- Claude: Introducing dynamic workflows in Claude Code
- OpenAI: Introducing GPT-5.5
- OpenAI API model page: GPT-5.5
- Axios coverage of Claude Opus 4.8 and Mythos timing
- Claude Code community launch discussion