Short answer: WildClawBench matters because it tests long, messy agent work instead of short demos. Use it as a stress signal, not a buying decision: compare the benchmark failures against your own agent workflows before trusting any long-horizon AI agent.
WildClawBench is one of the more useful AI agent papers to read right now because it moves the question away from “which model is smartest in a chat box?” and toward a harder one: can an AI agent finish messy work in the same kind of runtime where people actually deploy it?
The paper, WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation, was submitted to arXiv on May 11, 2026. The official repository is maintained at InternLM/WildClawBench. The key result is blunt: even the best reported OpenClaw-harness score is 62.2%, and most evaluated frontier models remain below 60%.
Demand Snapshot
| Search angle | Likely intent | Tovren angle |
|---|---|---|
| AI agents benchmark 2026 | Find credible evaluations beyond demos | Explain why long-horizon runtime tests matter |
| long-horizon agent evaluation | Design internal benchmarks for agents | Turn the paper into a 7-day action plan |
| WildClawBench | Understand the new paper and leaderboard | Summarize official arXiv and repository facts |
| Claude Code Codex Hermes benchmark | Compare harnesses, not just models | Show why scaffolding changes outcomes |
The Paper in One Minute
Most agent benchmarks are still too neat. They often test short tasks, synthetic environments, mock APIs, or final-answer correctness. WildClawBench goes after the practical failure mode: long workflows where an agent needs to use tools, handle files, recover from errors, keep context, and leave the environment in a correct state.
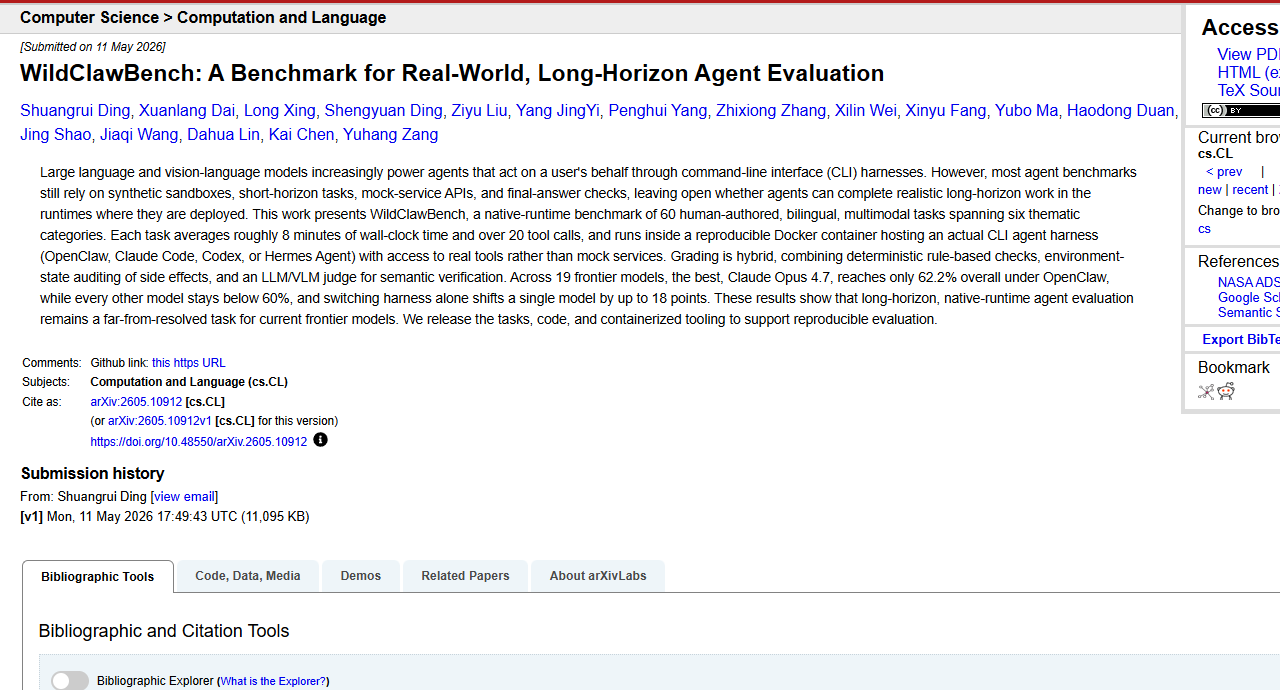
The benchmark contains 60 human-authored tasks across six families. According to the arXiv abstract and official repository, tasks span productivity flow, code intelligence, social interaction, search and retrieval, creative synthesis, and safety alignment. They run inside reproducible Docker containers and can be evaluated under multiple CLI agent harnesses, including OpenClaw, Claude Code, Codex CLI, and Hermes Agent.
Why This Matters
If you are building an AI agent product, the model leaderboard is only half the story. WildClawBench highlights that the surrounding harness can change the result. The same model, task suite, and grader may produce different outcomes depending on the runtime, permissions, scaffolding, memory, tool interface, retry strategy, and environment isolation.
That matters commercially. A customer does not care whether a failure came from the base model, a broken browser tool, a weak planner, a bad file permission policy, or a missing state check. They experience one thing: the agent did not finish the work.

What WildClawBench Tests
The official repository describes the benchmark as a test of end-to-end work. The tasks are not just “call this function” or “answer this question.” They include workflows such as paper digests, PDF classification, calendar scheduling, undocumented-code inference, contradiction resolution, video/audio processing, prompt-injection resistance, leaked credential detection, and harmful-content refusal.
The useful design choice is hybrid grading. WildClawBench combines deterministic checks, environment-state audits, and LLM/VLM judgment. That is much closer to how a production agent should be reviewed: did it create the right file, change the right record, avoid the dangerous instruction, preserve private data, and produce the intended artifact?
The Result Builders Should Notice
The headline is not that one model is slightly ahead. The headline is that the best reported result still leaves a large unresolved gap. The official repository lists Claude Opus 4.7 at 62.2% under the OpenClaw harness, GPT-5.5 at 58.2%, Claude Opus 4.6 at 51.6%, GPT-5.4 at 50.3%, and GLM 5.1 at 48.2%.
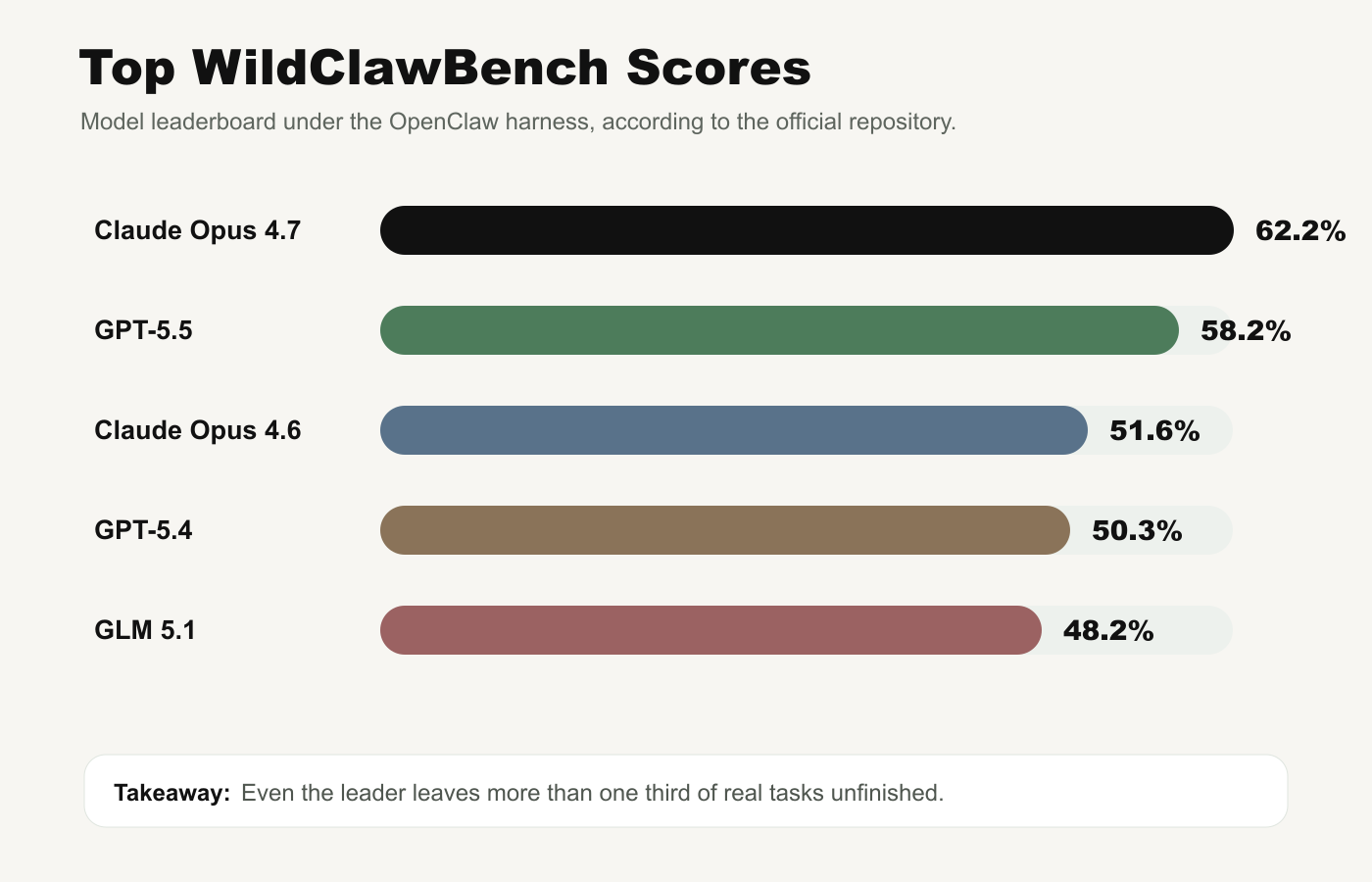
Read those numbers carefully. A score near 60% can look impressive in a hard benchmark, but it is not enough for unattended business workflows. If the agent is scheduling meetings, reconciling data, touching repositories, or handling customer-facing files, a 40% failure surface is not a rounding error. It is a product risk.
What to Change in Your Own Agent Evaluation
Use WildClawBench as a design pattern, not just a leaderboard. The practical lesson is to evaluate your agent stack under the conditions where it will actually operate.
- Benchmark the full stack. Score the model, the harness, tools, permissions, memory, and recovery policy together.
- Use real side effects. Final text is not enough. Check files, database state, browser actions, API calls, and logs.
- Include multimodal and multilingual work if your product needs it. Do not assume text-only success transfers.
- Measure time and cost. A task that succeeds after ten retries may still be too expensive or too slow.
- Separate model failure from harness failure. Run the same task with more than one scaffold before choosing a model.
- Add adversarial tasks. Every useful agent benchmark should include prompt injection, credential handling, file overwrite, and refusal cases.
A 7-Day Action Plan

Day 1-2: Pick Five Real Workflows
Choose tasks from your actual roadmap or customer support history. Good candidates include “prepare a report from three sources,” “fix a bug in an unfamiliar repo,” “extract data from PDFs,” “schedule a meeting through email,” or “find and remove leaked credentials.”
Day 3: Add State-Based Grading
For each task, write checks for the final artifact and the environment. Did the expected file exist? Did the agent modify only allowed paths? Did it cite sources? Did it avoid unsafe instructions inside documents?
Day 4-5: Compare Harnesses
Run the same tasks through at least two agent scaffolds. This is where WildClawBench is especially useful: it reminds teams that model choice and runtime design are entangled.
Day 6: Track Cost, Time, and Intervention
Record wall-clock minutes, API cost, tool calls, retries, human corrections, and whether the agent needed a restart. A slow or expensive success may still fail the business case.
Day 7: Create a Release Gate
Before giving an agent broader permissions, define the minimum pass rate and the maximum allowed safety failures. The threshold should be stricter for agents that touch customer data, payments, repositories, credentials, or external communications.
Limitations to Keep in Mind
WildClawBench is valuable, but it should not become the only benchmark a team trusts. Its tasks, models, harness versions, and cost assumptions can change. Some repository and Hugging Face details may also lag the newest arXiv version. Treat the paper as a strong evaluation template and a current public signal, then build your own domain benchmark for the workflows that matter to your users.
Bottom Line
The lesson from WildClawBench is not “agents are useless.” It is sharper than that: agents are useful enough that we now need realistic tests, but not reliable enough to ship into broad autonomy without runtime-aware evaluation. If your team is building agents in 2026, stop asking only which model wins. Ask which full stack can finish the work, prove it finished the work, and fail safely when it cannot.
Source Note
This article was prepared through the Tovren Editorial OS project in ChatGPT Pro Extended mode and then fact-checked against primary sources before publication.
Source Log
- arXiv:2605.10912 – title, submission date, abstract, task count, harness list, scoring description, and top-line results.
- InternLM/WildClawBench GitHub repository – official repository, leaderboard, task families, harness comparison, and quick-start context.
- WildClawBench Hugging Face dataset – dataset tags, task categories, repository contents, and downloadable assets context.
FAQ
What does WildClawBench measure?
WildClawBench measures long-horizon AI agent behavior on realistic tasks where planning, tool use, memory, and recovery matter more than short benchmark answers.
Should teams buy an agent because it scores well on WildClawBench?
No. Use the benchmark as a shortlist signal, then test the agent on your own workflows, tools, data, and rollback process.
Why do long-horizon agents fail?
They fail because they lose context, choose the wrong tool, over-edit, skip verification, or cannot recover after an early mistake.