AI Benchmarks Are Broken: ABA Paper Guide
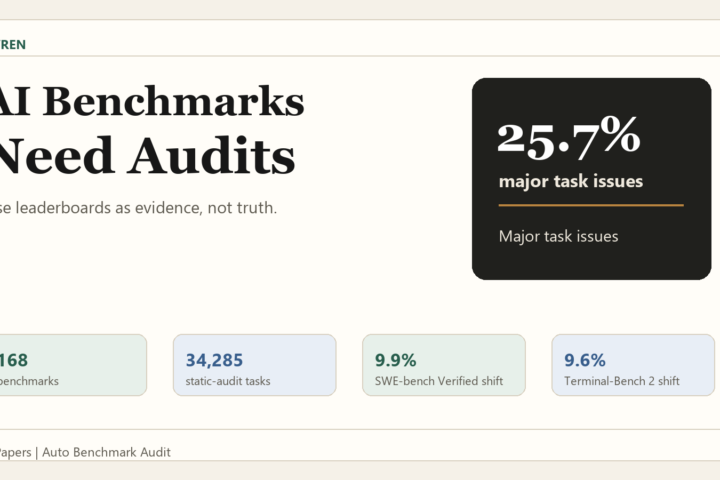
The ABA paper found major issues in 25.7% of audited AI benchmark tasks. Here is how to read model leaderboards without being fooled by flawed tasks.
Tovren Editorial
Editorial Archive
The ABA paper found major issues in 25.7% of audited AI benchmark tasks. Here is how to read model leaderboards without being fooled by flawed tasks.
Claude Opus 4.8 vs GPT-5.5 for coding agents: where each model fits, what to test first, and how teams should pilot agentic coding workflows in 2026.
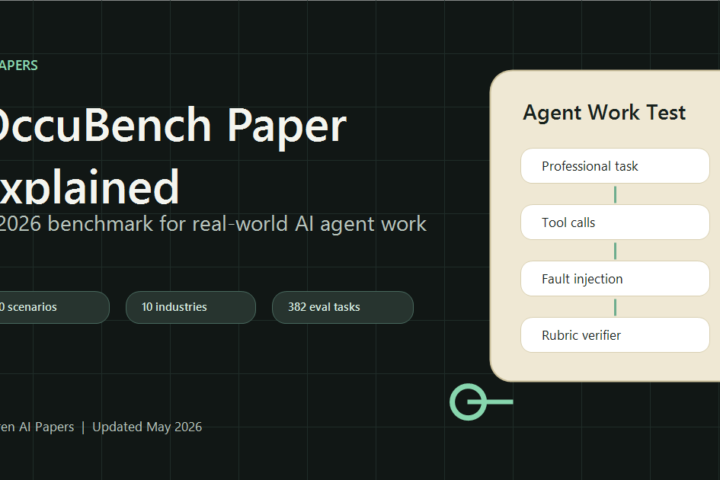
OccuBench Explained: Real-World AI Agent Benchmark: a practical Tovren guide with direct recommendations, current source checks, decision tables, and clear ne