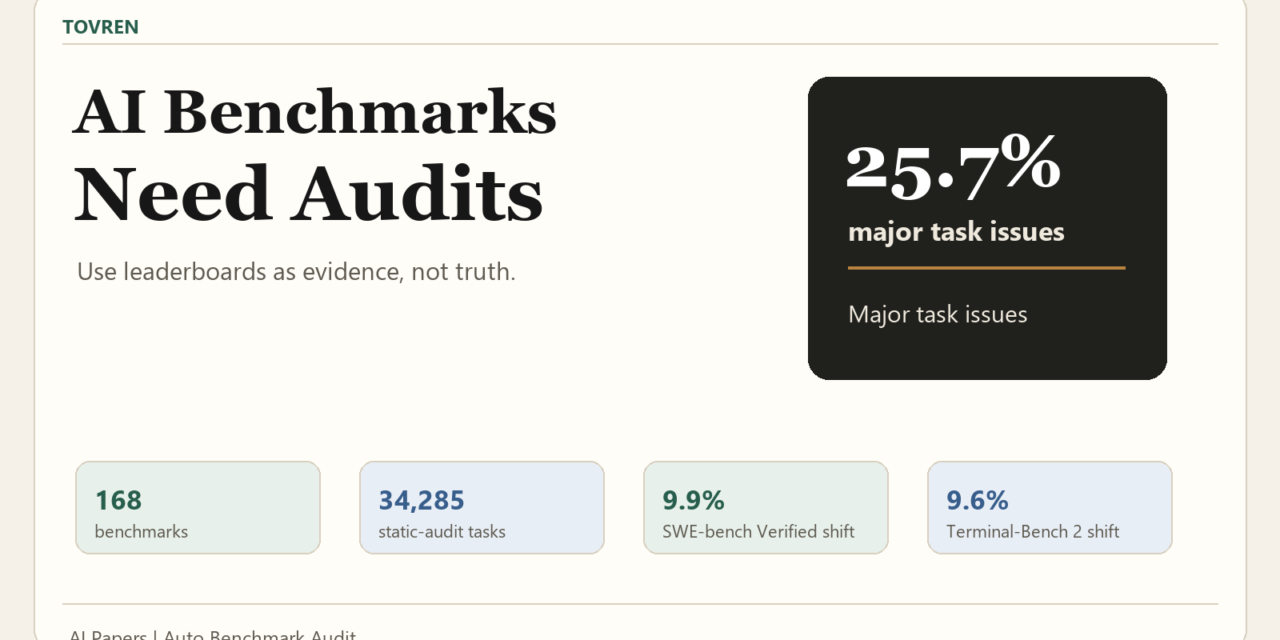
Direct verdict: AI benchmark leaderboards are not safe to read at face value. The Automated Benchmark Auditing for AI Agents and Large Language Models paper reports that ABA found major issues in 25.7 percent of audited tasks across 168 benchmarks and nine domains. Action rule: do not trust small model ranking deltas unless the benchmark publishes task audits, contamination controls, failure analysis, and fixes. For developers, buyers, founders, researchers, and operators, the right move is not to ignore leaderboards. It is to treat them as screened evidence, then ask whether the task set itself survived audit pressure.
The paper’s practical message is simple: the benchmark can be wrong even when the model score is calculated correctly. A model may appear stronger or weaker because a task has ambiguous instructions, a broken environment, a brittle grader, or an evaluation setup that rejects valid solutions. That matters for anyone choosing LLMs or AI agents from public benchmark claims, especially in coding, tool use, medical, safety, retrieval, and professional workflow settings.
This is directly relevant to how Tovren evaluates models and agents in guides such as Best LLMs Right Now, coding-agent comparisons like Claude Opus 4.8 vs GPT-5.5 for coding agents, and benchmark coverage such as WildClawBench. A leaderboard is useful only when the evaluation instrument is also being evaluated.

What the paper found
Automated Benchmark Auditing for AI Agents and Large Language Models was submitted to arXiv on May 25, 2026, with v2 posted on May 26, 2026. The DOI is 10.48550/arXiv.2605.26079. The paper introduces Automated Benchmark Auditing, or ABA, as a framework for auditing benchmark tasks for instruction ambiguity, environment conflicts, and evaluation quality problems.
The paper ran a static audit across 168 benchmarks, nine domains, and 34,285 tasks. ABA found that 25.7 percent of tasks had major issues and 15.1 percent had minor issues. Less than 60 percent were clean. That is the headline result buyers should remember: a benchmark score can be affected not only by model capability, but also by task defects at meaningful scale.
| Audit scope | Paper result | Why it matters |
|---|---|---|
| Benchmarks audited | 168 | The result spans many benchmark families, not a single narrow dataset. |
| Domains covered | 9 | The issue is cross-domain: coding, safety, medical, retrieval, math, science, multimodal, professional, and tool-use tasks all need scrutiny. |
| Tasks in paper audit | 34,285 | The study is large enough to expose systematic benchmark-quality problems. |
| Major issue rate | 25.7% | Roughly one in four audited tasks had a serious defect according to ABA. |
| Minor issue rate | 15.1% | Additional tasks had lower-severity problems that may still affect interpretation. |
| Clean tasks | Less than 60% | Leaderboards need clean-set and flagged-task reporting, not just aggregate scores. |
The live AutoBenchAudit snapshot supplied for this article shows a similar but not identical picture: 168 benchmarks, 35,205 task audits, 25.5 percent major findings, and 15.2 percent minor findings. Those numbers can differ from the paper because a live project site may reflect updated audits, additional tasks, or changed aggregation after the paper snapshot.
The highest-risk domains are not where buyers can afford weak evaluation
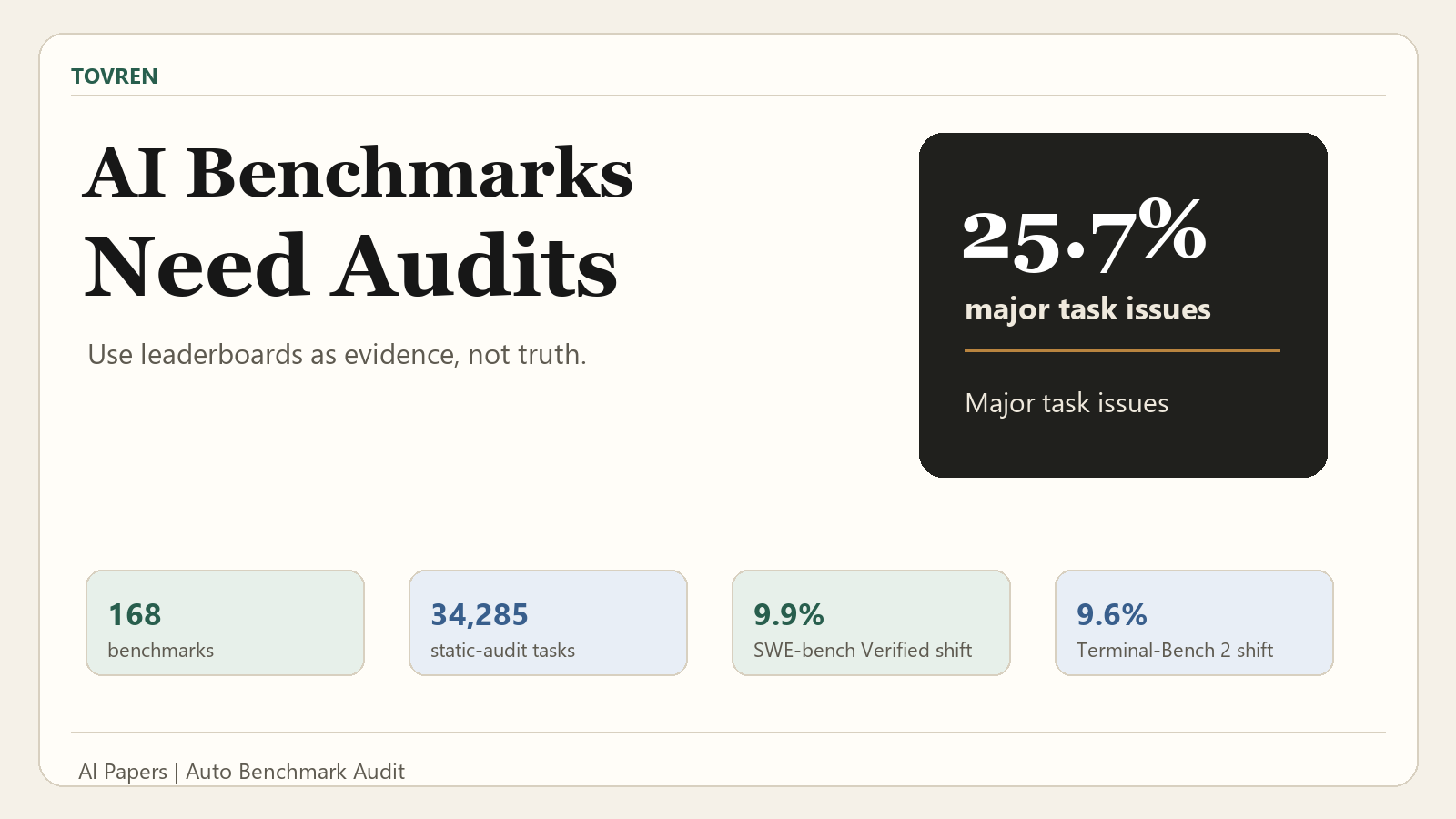
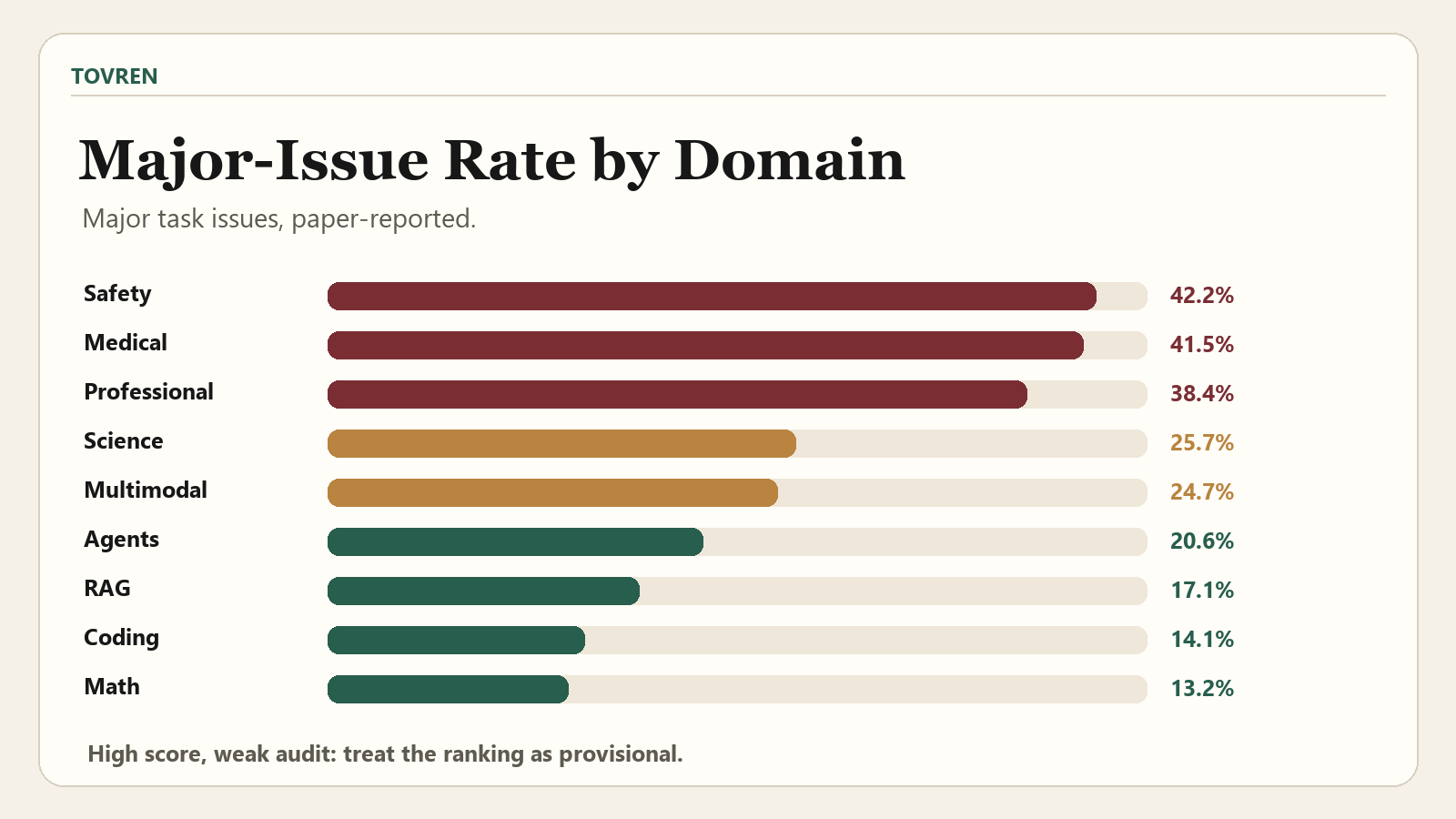
The domain-level results are especially important. Medical, safety/alignment, and professional benchmarks show some of the highest major issue rates. Those are also domains where buyers are most likely to over-interpret benchmark claims as evidence of reliability, compliance readiness, or expert-level reasoning.
| Domain | Major issue rate | Tovren reading |
|---|---|---|
| Safety / Alignment | 42.2% | Safety claims need unusually strong rubric transparency, task review, and failure analysis. |
| Medical | 41.5% | Clinical or biomedical benchmark claims should not be treated as deployment evidence without expert review. |
| Professional | 38.4% | Business-style tasks often depend on unstated assumptions, ambiguous goals, or subjective grading rules. |
| Science | 25.7% | Expert tasks can still contain hidden assumptions that affect scoring. |
| Multimodal | 24.7% | Vision-language tasks need careful inspection of image context, prompt wording, and answer contracts. |
| Agentic Tool Use | 20.6% | Tool-use benchmarks must validate runtime setup, tool contracts, and environment assumptions. |
| Retrieval / RAG | 17.1% | Retrieval benchmarks need source-grounding checks, answer-provenance review, and grader inspection. |
| Coding | 14.1% | Coding appears cleaner than several other domains, but not clean enough for blind leaderboard trust. |
| Math | 13.2% | More deterministic answer formats may reduce some defects, but they do not eliminate audit risk. |
The domain spread changes how a careful reader should interpret “state of the art” claims. A safety benchmark with a high issue rate should not be used as a thin marketing credential. A medical benchmark with many flawed tasks should not be used as evidence that a model is safe for clinical work. A professional benchmark with ambiguous tasks should not be used to claim that a model can replace expert judgment in complex workflows.
Why leaderboards change after benchmark audits
Benchmark errors do not affect every model equally. Some models may be better at guessing a benchmark author’s hidden intent. Some may be more brittle in a broken environment. Some may produce valid answers that the evaluator rejects. Others may appear strong because they exploit a flawed test rather than solve the intended problem.
That is why ABA’s ranking-shift result is so important. Filtering problematic tasks increased average performance by 9.9 percent on SWE-bench Verified and 9.6 percent on Terminal-Bench 2. The practical interpretation is not that models suddenly became better. It is that some measured failures were not clean evidence of model weakness.
| Benchmark or validation point | Reported result | Practical implication |
|---|---|---|
| SWE-bench Verified after filtering problematic tasks | Average performance increased by 9.9% | Some failures reflected task or evaluation defects rather than pure model incapability. |
| Terminal-Bench 2 after filtering problematic tasks | Average performance increased by 9.6% | Terminal and agent benchmarks need environment-level audit, not just final scoring. |
| Terminal-Bench 2 fix PR validation | A fix PR targeted 22 tasks; the paper decomposed 21 issues; trajectory audit recovered 14 strictly and 17 partially. | Automated audit findings overlapped with concrete benchmark-maintenance work. |
| Manual review precision for major issues | 73% strict precision and 91% partial precision | ABA is useful as a scalable audit method, but findings still benefit from expert review. |
| SWE-bench Verified trajectory issues | 92% strict precision and 96% partial precision | Trajectory-backed issues are especially strong because they are tied to actual model runs. |
| Trajectory mode versus static mode across eight benchmarks | Trajectory mode found 8.5% more major tasks and 6.1% more flagged tasks than static mode. | Runtime traces expose defects that static file inspection can miss. |
This is the central lesson for leaderboard readers: small deltas are fragile unless the benchmark has been cleaned. A model that leads by a narrow margin on a dirty benchmark may not be the better model for your workflow. It may simply be less penalized by the benchmark’s defects, or more aligned with its hidden assumptions.
How ABA works
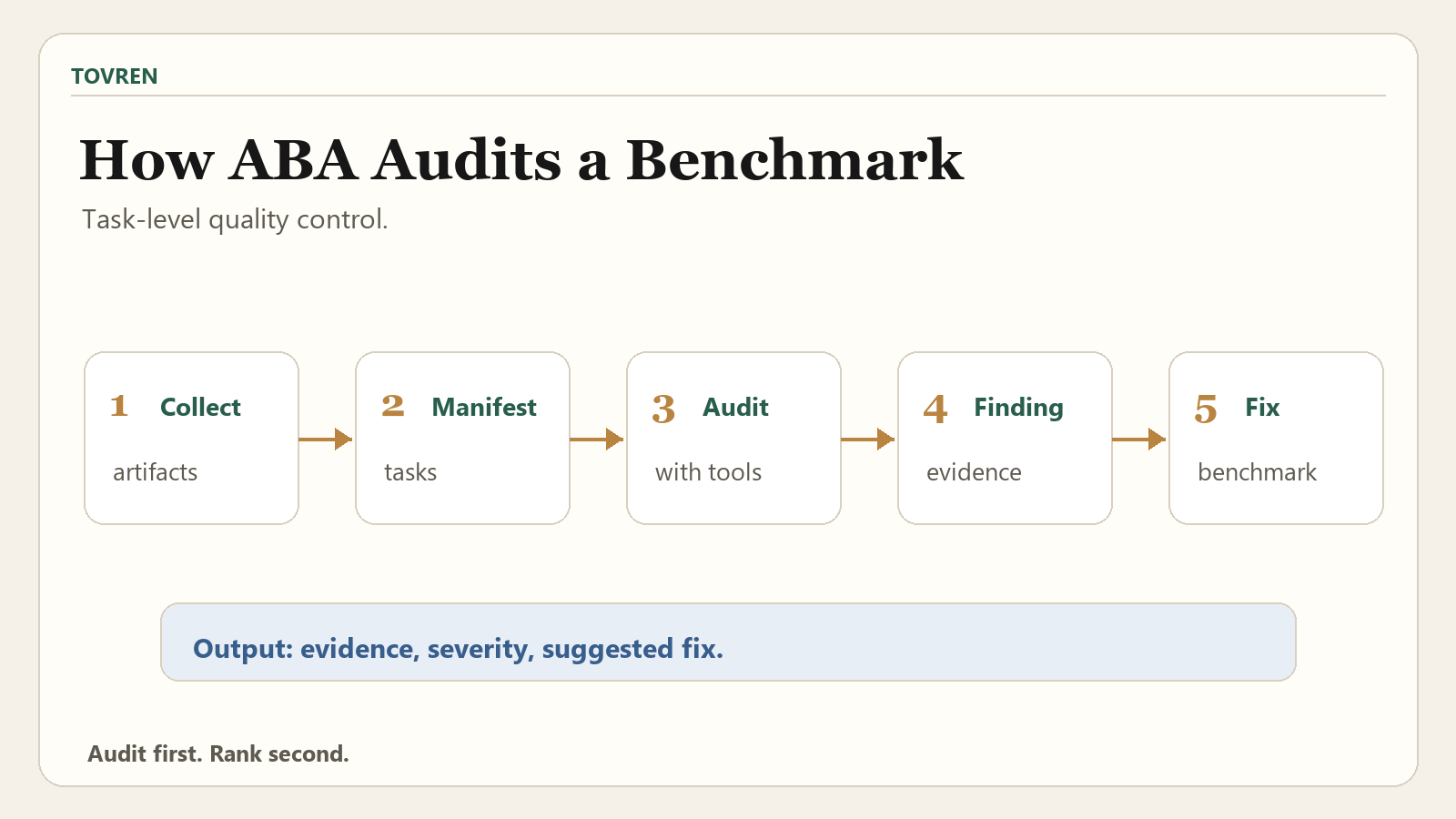
ABA is not just a text classifier that labels tasks as good or bad. It is an agentic auditing process that inspects benchmark artifacts, task configurations, evaluation files, and, where available, trajectories from actual model runs.
The process starts with an evidence collector that maps benchmark artifacts into a manifest. Then an auditor agent inspects task configurations with shell tools. The findings include the issue category, severity, evidence, why the issue matters, and a suggested fix. That last part matters: useful benchmark auditing should create repairable evidence, not just a scorecard of defects.
| ABA component | What it does | Output | Why it matters |
|---|---|---|---|
| Evidence collector | Maps benchmark artifacts into a manifest. | A structured view of task files, configs, evaluation artifacts, and related evidence. | Benchmarks vary widely in structure; normalized evidence is needed before scalable auditing. |
| Auditor agent | Inspects task configs with shell tools. | Structured findings about task and evaluation problems. | The auditor can examine more than the visible prompt, including files and harness assumptions. |
| Finding category | Labels the type of problem found. | Issue categories such as ambiguity, environment conflict, or evaluation-quality problem. | Categories make benchmark defects easier to triage and repair. |
| Severity | Distinguishes major from minor issues. | A prioritization signal for benchmark authors and leaderboard readers. | Not every defect has the same impact on model ranking or interpretation. |
| Evidence | Records the basis for the finding. | File paths, task details, trajectory evidence, or inspection notes. | Findings are more useful when reviewers can verify them. |
| Suggested fix | Explains how the task could be repaired. | An actionable recommendation. | Benchmark auditing should improve future evaluations, not merely criticize existing ones. |
The paper’s reproducibility details are also important. The reported setup used Claude Code CLI v2.1.96, Claude Opus 4.7, default tools, and headless one-shot JSON sessions. The GitHub README pipeline includes audit-benchmark, collect-evidence, sample-tasks, audit-tasks, and cleanup. It uses Python 3.12 and uv.
| Reproducibility item | Reported detail | How to interpret it |
|---|---|---|
| Auditor CLI | Claude Code CLI v2.1.96 | The audit environment is pinned more concretely than a vague “LLM judge” description. |
| Auditor model | Claude Opus 4.7 | Future replications should record auditor model version because audit outputs may change with the model. |
| Tooling | Default tools | The auditor can use tool access to inspect files and execute shell-level analysis. |
| Session mode | Headless one-shot JSON sessions | Findings can be collected and aggregated across many tasks. |
| Repository pipeline | audit-benchmark, collect-evidence, sample-tasks, audit-tasks, cleanup | The workflow is designed as a repeatable benchmark-auditing pipeline. |
| Runtime requirements | Python 3.12 and uv | Teams evaluating the repository should check local environment compatibility first. |
OpenAI’s SWE-bench Verified context
The ABA paper should also be read alongside OpenAI’s February 23, 2026 blog post, Why we no longer evaluate SWE-bench Verified. OpenAI said SWE-bench Verified is increasingly contaminated, stopped reporting it, recommended SWE-bench Pro, and found that 59.4 percent of audited problems in a 138-problem subset had material test or design issues.
That context reinforces the ABA paper’s central point. Benchmark problems are not only theoretical. Public coding benchmarks can become contaminated. Tests can reject valid fixes. Design flaws can make scores less informative as frontier models improve. When a benchmark becomes widely used, it can become less useful as a clean measurement instrument.
For model selection, the right conclusion is not “ignore SWE-bench-style evaluations.” It is to ask whether the benchmark is current, audited, contamination-aware, and still discriminative for frontier systems. If a benchmark no longer separates real capability from benchmark familiarity, small score differences are not a reliable basis for tool selection.
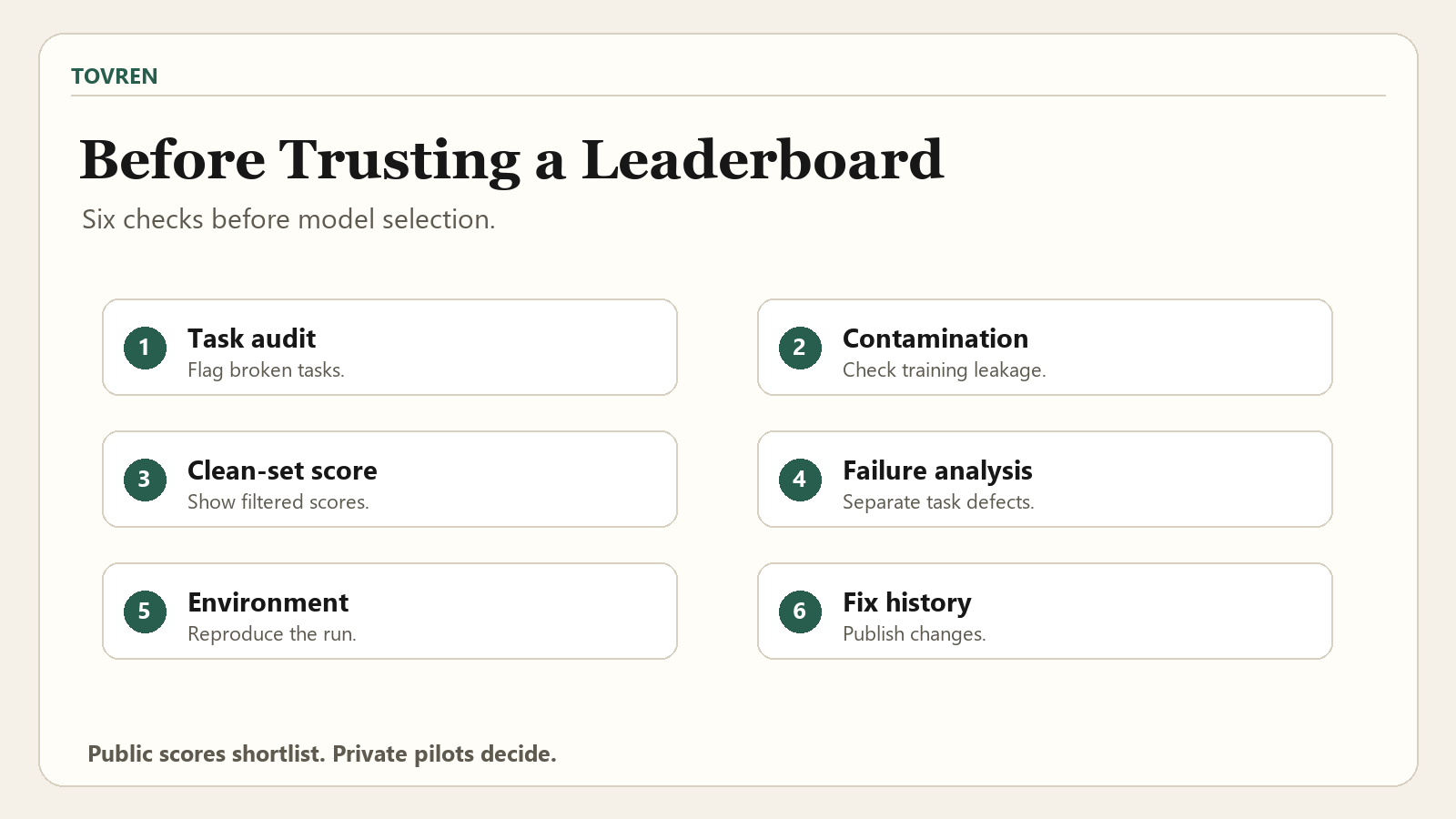
Benchmark-claim reading checklist
Use this checklist before accepting benchmark claims from a model launch, vendor sales deck, research paper, leaderboard, or social media thread. It is intentionally strict because the paper shows that benchmark defects are large enough to affect model-ranking interpretation.
| Question to ask | Good evidence | Weak evidence | Decision rule |
|---|---|---|---|
| Was the task set audited? | Task-level audit with severity, evidence, and suggested fixes. | A general claim that the benchmark was reviewed. | Discount small ranking deltas without task-level audit evidence. |
| Were ambiguous instructions identified? | Ambiguous tasks are removed, fixed, or reported separately. | The benchmark assumes the grader’s interpretation is the only valid one. | Be cautious with professional, medical, safety, and open-ended tasks. |
| Were environment conflicts tested? | Dependencies, containers, file paths, runtime assumptions, and tool contracts are checked. | The benchmark reports pass/fail scores without environment diagnostics. | Require environment audit for coding, tool-use, terminal, and agent benchmarks. |
| Was evaluation quality inspected? | Rubrics, tests, answer contracts, and grader behavior are reviewed. | The benchmark hides grading behavior behind a single score. | Do not trust a benchmark that may reject valid alternative solutions. |
| Were contamination controls used? | The benchmark explains exposure risk, private task design, or contamination testing. | Public tasks are treated as clean by default. | Separate model capability from possible benchmark memorization. |
| Are clean-set scores reported? | The benchmark reports full-set, clean-set, and flagged-task sensitivity. | Only one aggregate leaderboard number is shown. | Ask how rankings move after major-issue tasks are removed. |
| Is there failure analysis? | Failures are classified by model limitation, task defect, environment issue, and evaluator problem. | All failures are treated as model failures. | Prefer benchmarks that explain why agents fail, not only whether they fail. |
This same verification mindset applies beyond model leaderboards. Tovren’s AI hallucinated citations audit workflow uses a similar principle: output quality cannot be assumed just because the surface form looks credible. Measurement systems need audit trails.
Vendor questions for buyers
For AI buyers, the ABA paper turns leaderboard reading into procurement diligence. A vendor should be able to explain what benchmark evidence proves, what it does not prove, and how the score behaves after flawed tasks are removed.
| Buyer question | Why to ask | Strong answer | Red flag |
|---|---|---|---|
| Which tasks were flagged, removed, or fixed before this score was reported? | Filtering problematic tasks can change average performance and rankings. | The vendor provides full-set, clean-set, and flagged-task sensitivity results. | The vendor reports only a headline leaderboard number. |
| How did you test for benchmark contamination? | Public benchmark exposure can inflate model scores. | The vendor describes contamination probes, private holdouts, or newly authored evaluation tasks. | The vendor assumes public benchmark tasks are uncontaminated. |
| What failed: the model, the task, the environment, or the grader? | Agent failures can be caused by multiple layers of the evaluation system. | The vendor separates model errors from task defects, runtime problems, and evaluator defects. | Every failure is collapsed into a simple pass/fail count. |
| Can we inspect task-level logs or trajectories? | Trajectory evidence can reveal silent failures and benchmark defects. | The vendor supports reviewable logs, traces, and failure examples. | The vendor refuses task-level inspection. |
| Can we run a private workflow-specific evaluation? | Your production workflow may not match public benchmark tasks. | The vendor supports customer-specific evaluation with clear scoring and review. | The vendor treats public benchmark scores as sufficient proof. |
| What runtime governance exists after deployment? | Benchmark performance does not guarantee safe production behavior. | The vendor supports logging, replay, approval gates, rollback, and incident review. | The vendor uses leaderboard performance as a substitute for governance. |
That final point is where evaluation meets operations. Public benchmark performance can help with shortlisting, but production agents need runtime controls. Tovren’s AI agent evaluations and runtime governance pilot covers that deployment layer: logs, approval gates, failure review, and operational monitoring.
Who should change behavior after this paper?
| Reader | What to change now | What not to do |
|---|---|---|
| Developers choosing coding agents | Run a small private evaluation on your own repository and inspect failed trajectories. | Do not switch agents based only on a narrow public coding leaderboard delta. |
| AI buyers and operators | Ask vendors for audited task sets, clean-set scores, contamination controls, and failure analysis. | Do not treat benchmark rankings as procurement proof. |
| Founders comparing model APIs | Track public scores, but validate cost, latency, reliability, and task success on your own workflows. | Do not equate one leaderboard win with product superiority. |
| Researchers building benchmarks | Publish task-audit metadata, issue categories, severities, fixes, and versioned changelogs. | Do not assume expert-authored tasks are automatically clean. |
| Benchmark maintainers | Add ABA-style auditing before release and after major task-set updates. | Do not leave known-bad tasks inside a leaderboard without clear flags. |
Limits
ABA is not an infallible judge. The paper’s manual review results show strong but imperfect precision: major issues reached 73 percent strict precision and 91 percent partial precision. That means an ABA finding should be treated as serious evidence, not automatic ground truth. Benchmark owners and domain experts still need to review, confirm, and fix the underlying task.
Static audits also have limits. The paper reports that trajectory mode found 8.5 percent more major tasks and 6.1 percent more flagged tasks than static mode across eight benchmarks. That matters because some failures are visible only when an agent actually runs: a missing dependency, an inconsistent environment, an evaluator mismatch, or a tool interaction problem may not be obvious from static files alone.
The auditor setup matters too. The paper reports Claude Code CLI v2.1.96 and Claude Opus 4.7. A different auditor model, tool environment, or prompt design could produce different findings. Reproducible benchmark auditing should therefore record the auditor model, tool versions, task snapshot, and evidence collection process.
Finally, task defects are not the only leaderboard risk. Contamination, prompt selection, inference budget, pass@k reporting, hidden retries, tool access, and cherry-picked submissions can all affect model ranking. ABA addresses an important part of the evaluation problem, but it should be combined with broader evaluation governance.
Bottom line
The ABA paper is a warning against leaderboard literalism. It does not say AI benchmarks are worthless. It says benchmark scores are only as trustworthy as the tasks, environments, graders, and audit processes behind them.
For practical model selection, the safest rule is this: use leaderboards to discover candidates, not to make final decisions. Before trusting a claimed win, ask whether the benchmark publishes task audits, contamination controls, failure analysis, clean-set sensitivity, and fixes. If those are missing, treat small ranking deltas as weak evidence.
FAQ
What is the Automated Benchmark Auditing paper about?
It introduces ABA, a framework for auditing AI benchmark tasks for instruction ambiguity, environment conflicts, and evaluation quality problems. The paper applies ABA across 168 benchmarks, nine domains, and 34,285 tasks.
What is the main finding?
The paper reports that 25.7 percent of audited tasks had major issues and 15.1 percent had minor issues. Less than 60 percent of tasks were clean in the paper’s static audit snapshot.
Does this mean AI benchmark leaderboards are useless?
No. It means leaderboards need context. They are useful when paired with task-level audits, contamination controls, clean-set reporting, failure analysis, and documented fixes.
Why can model rankings change after filtering benchmark tasks?
Flawed tasks do not affect every model equally. Some models may fail because of ambiguous instructions, broken environments, or brittle graders rather than true lack of capability. Filtering problematic tasks increased average performance by 9.9 percent on SWE-bench Verified and 9.6 percent on Terminal-Bench 2.
How should buyers use this paper?
Buyers should use public benchmarks as an initial signal, then ask vendors for audited task sets, contamination analysis, clean-set scores, task-level logs, failure analysis, and private workflow evaluations before making decisions.
Source log
| Source | Publisher | Date | Claims supported |
|---|---|---|---|
| Automated Benchmark Auditing for AI Agents and Large Language Models | arXiv | Submitted May 25, 2026; v2 May 26, 2026 | Paper identity, DOI 10.48550/arXiv.2605.26079, ABA framing, audit scope, headline issue rates, ranking-shift claims. |
| Automated Benchmark Auditing for AI Agents and Large Language Models — HTML version | arXiv | v2 May 26, 2026 | Domain issue rates, ABA workflow, static and trajectory audit details, validation results, reproducibility setup, limitations. |
| AutoBenchAudit | AutoBenchAudit project site | Live snapshot supplied for this article | Live snapshot: 168 benchmarks, 35,205 task audits, 25.5 percent major findings, and 15.2 percent minor findings; note that live site numbers can differ from paper numbers. |
| IsThatYou/auto-bench-audit | GitHub | Repository source supplied for this article | README pipeline: audit-benchmark, collect-evidence, sample-tasks, audit-tasks, cleanup; Python 3.12 and uv. |
| Why we no longer evaluate SWE-bench Verified | OpenAI | February 23, 2026 | SWE-bench Verified contamination context, OpenAI stopping SWE-bench Verified reporting, recommendation of SWE-bench Pro, and 59.4 percent material test or design issues in a 138-problem audited subset. |