Short answer: AI agent evaluations should happen before and during production use. A serious pilot logs actions, measures task success, tests failure recovery, and blocks deployment until the agent passes runtime governance checks.
Verdict: Do not let an AI agent touch production data, customer accounts, payments, HR records, contracts, CRM fields, CI/CD, or regulated workflows until you can replay its runs, score its tool use, block unsafe actions at runtime, and prove who approved each high-risk step. Agent evaluation is no longer a research afterthought. It is the production gate.
As of May 28, 2026, the practical question for enterprise agents is not “can the model answer?” It is “can the system run the right process, with the right tools, under enforceable controls, when the case is messy?” The answer has to be proven before go-live, not hoped for after deployment.
This guide gives operators, founders, IT leaders, automation teams, and developers a direct way to test agents before they touch real workflows. It focuses on invoice processing, HR onboarding, support refunds, contract review, CRM updates, CI/CD, and banking or other regulated workflows.
What changed in May 2026
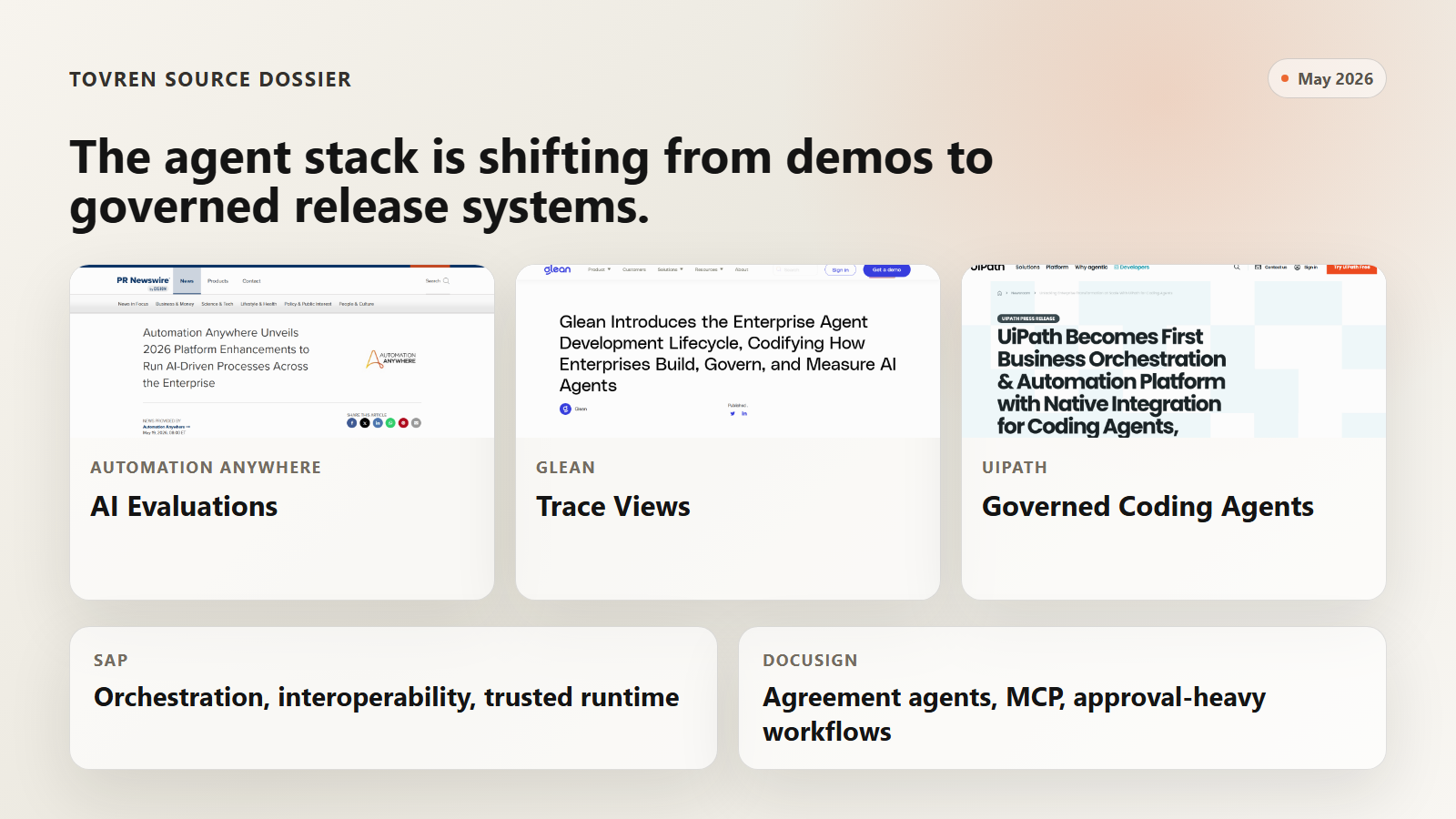
May 2026 made the production-agent pattern much clearer. The important signal across vendor announcements was not just “more agents.” It was evaluations, traceability, orchestration, secure runtime, access policy, sandboxing, and governance.
| Source | What changed | Why it matters for operators |
|---|---|---|
| Automation Anywhere | Announced 2026 APA platform enhancements, including AI Evaluations available as of that announcement. The company says AI Evaluations assess agents at design time and runtime by checking correct outcome, right tool use, and appropriate execution paths. It also announced Process Simulation, Optimization & Testing to simulate full processes, including failures, exceptions, and edge cases, before deployment. Context Intelligence Graph is in preview and is described as built on insights from more than 400 million automation executions, with internal evaluations claiming more than 30 percent higher accuracy versus agents without it. | Enterprise agent testing is moving from prompt checks to process-level release gates. |
| Glean | Introduced an Enterprise Agent Development Lifecycle with capabilities such as Debug & Trace Views, Expanded Agent Sandbox, Agent Access Policies, and an Agent Insights Dashboard. Glean frames agents as software that need to be defined, built, launched, governed, and improved. | Agents need lifecycle management, not one-off prompt experiments. |
| UiPath | Announced UiPath for Coding Agents, positioned to let enterprises build, test, deploy, operate, and govern automations at scale using coding agents. UiPath emphasized open support for multiple coding agents, orchestration, policy enforcement, audit trails, credential vaults, RBAC, and runtime controls. | Coding agents need the same promotion, testing, access, and audit path as human-built automation. |
| SAP Sapphire 2026 | SAP announced an autonomous enterprise direction with partnerships across Anthropic, AWS, Google Cloud, Microsoft, Mistral AI, Cohere, n8n, NVIDIA OpenShell, Parloa, and others. | The enterprise stack is converging around orchestration, interoperability, business context, and trusted runtime. |
| Docusign | Announced AI Assistant and agents for agreement work. Docusign said its open platform and MCP connect with Claude, Gemini, and ChatGPT so teams can create, review, and manage agreements in natural language inside tools they already use. | Agreement agents will touch legal, sales, HR, procurement, and finance workflows, so evaluation has to include approvals, obligations, and risk flags. |
The cautious community signal points in the same direction.
The cautious community signal points in the same direction. In May 2026, Reddit discussions in r/AI_Agents, r/AI_Governance, and r/sre focused on runtime enforcement, audit trails, ownership, and the gap between written AI policy and what agents actually do. Treat those threads as anecdotal operator sentiment, not proof of market adoption or incident rates.
Why agent evaluations matter more than chatbot benchmarks
A chatbot can be wrong in a visible answer. A workflow agent can be wrong in a hidden action.
That is the difference. An agent can retrieve the wrong record, call the wrong tool, pass sensitive context to the wrong step, update a CRM field, approve a refund, open a support ticket, generate a contract redline, run a shell command, or trigger a payment workflow. The final summary can look clean while the execution path was unsafe.
For production agents, evaluation has to test four layers:
- Outcome: Did the agent finish the business task correctly?
- Tool use: Did it use the right tools, with the right arguments, in the right order?
- Runtime controls: Did the system block, pause, escalate, or require approval when the action became risky?
- Evidence: Can the team reconstruct what happened from traces, logs, approvals, and outputs?
Observability is not enough. A dashboard that shows a bad refund after it happened is not governance. Governance means the agent was prevented from issuing the refund, asked for approval, or restricted to a safer workflow before the external side effect occurred.

The production gate: what to evaluate before go-live
Use this checklist before connecting an agent to any real system of record. For MCP-based access, start by auditing exposed tools and shadow integrations with Tovren’s guide to MCP
servers, shadow IT, and agent tool access. For browser agents and search-driven agents, also review the practical risks in Tovren’s AI
browser agent prompt pack, Google
Search agents and AI Mode shopping agents guide, and website
AI agent data source guide.
| Evaluation area | What to test | Example failure | Required control |
|---|---|---|---|
| Goal correctness | Does the agent solve the actual workflow, not just produce a plausible answer? | An invoice agent approves the right vendor but the wrong invoice version. | Golden test cases with expected final state and human-reviewed exceptions. |
| Tool selection | Does the agent choose read, write, approve, send, refund, deploy, or delete tools correctly? | A support agent uses a refund tool when it should only create a manager review ticket. | Tool allowlists, per-action scopes, and approval gates for side effects. |
| Tool arguments | Are the exact arguments safe and valid? | A coding agent runs a database command against production instead of staging. | Argument-level validation before execution, deny-by-default rules, protected environment detection. |
| Data boundaries | Does the agent only access data needed for the task? | An HR onboarding agent retrieves compensation data for employees outside the hiring workflow. | Least privilege, row-level permissions, redaction, and separate service identities. |
| Context movement | Does sensitive context move between steps, tools, agents, or vendors? | A contract review agent sends confidential clause notes into an external drafting tool. | Context classification, tool-specific data policies, and blocked cross-boundary transfers. |
| Execution path | Does the agent follow approved steps and stop when required? | An invoice agent skips three-way match because the vendor email seems trustworthy. | Workflow state machine, required checkpoints, trace comparison against approved path. |
| Exception handling | What happens when records are missing, contradictory, stale, or suspicious? | A CRM update agent invents a missing company ID and writes to the closest match. | Refusal, escalation, duplicate detection, and no-write mode for ambiguous cases. |
| Human approval | Are approvals meaningful, logged, and placed before the risky action? | A banking workflow asks for approval after a customer notification has already been sent. | Pre-action approval, approver identity, reason capture, and immutable audit trail. |
| Rollback and recovery | Can the team undo or isolate the agent’s action? | A batch CRM update overwrites sales stage values for hundreds of accounts. | Dry run, diff preview, versioned writes, rollback scripts, and blast-radius caps. |
| Traceability | Can every input, tool call, decision, output, and approval be reconstructed? | The final answer exists, but no one can see which contract clause or policy source drove the decision. | Trace views, signed logs, prompt and context snapshots, and log storage the agent cannot modify. |
Seven workflow examples to test first
1. Invoice processing
Test an agent that reads invoices, matches them to purchase orders, checks vendor records, routes exceptions, and updates ERP or accounts payable systems. Include duplicate invoice numbers, changed bank details, missing purchase orders, currency mismatches, high-value approvals, and suspicious vendor email domains. The agent should be allowed to draft a recommendation before it is allowed to create or release a payment.
2. HR onboarding
Test a workflow that creates onboarding tasks, checks required documents, sends welcome materials, and requests access. Include name mismatches, missing identity documents, contractors versus employees, nonstandard job roles, manager requests for excessive access, and regional privacy requirements. The agent should never grant system access outside a pre-approved role template without human approval.
3. Support refunds
Test order lookup, refund eligibility, fraud flags, customer history, and refund issuance. Include partial refunds, duplicate refund attempts, chargeback risk, account takeover signals, and refunds above threshold. A safe agent can summarize the case and prepare the refund; production control decides whether it can execute.
4. Contract review
Test redline suggestions, policy checks, approval routing, obligation extraction, renewal tracking, and clause risk scoring. Include missing governing law, nonstandard indemnity, unusual payment terms, personal data clauses, and conflicting versions. Agreement agents such as those announced by Docusign make this workflow attractive, but legal review and approval evidence remain mandatory for material commitments.
5. CRM updates
Test whether an agent can summarize calls, update opportunity fields, create follow-up tasks, and flag account risk. Include duplicate accounts, conflicting notes, missing consent, private customer information, and stale deal stages. The first production mode should be “draft changes for review,” not direct writes to high-value accounts.
6. CI/CD and coding agents
Test coding agents that create automation, run tests, open pull requests, or touch deployment workflows. Include protected branches, production credentials, test failures, missing review, unsafe shell commands, and infrastructure changes. Developer teams should connect this to normal CI/CD gates, code review, credential vaults, and runtime controls. For deeper developer context, see Tovren’s guides to Anthropic
, Stainless SDK, and MCP for agent developers and the Claude
Agent SDK and OpenClaw guide.
7. Banking and regulated workflows
Test loan document triage, KYC support, transaction review, complaint routing, and internal policy Q&A. Include sanctions flags, PII boundaries, regional data residency, contradictory customer records, and required human attestations. For regulated workflows, a pilot should prove evidence quality before autonomy. If the agent cannot produce a defensible trace, it should not execute the action.

14-day pilot plan: from demo to controlled canary
This plan assumes one workflow, one agent, one business owner, one technical owner, and one risk or security reviewer. The goal is not full autonomy in 14 days. The goal is a decision: block, keep in sandbox, or run a narrow canary with controls.
| Day | Work | Output | Gate |
|---|---|---|---|
| 1 | Pick one workflow and define the smallest useful agent action. Prefer invoice exception triage, support refund preparation, CRM draft updates, or contract risk summary before direct writes. | One-page workflow charter with owner, systems, user group, risk level, and excluded actions. | No pilot starts without a named business owner and technical owner. |
| 2 | Map systems, tools, data, permissions, and side effects. Separate read, write, send, approve, delete, deploy, and pay actions. | Tool inventory and data-flow map. | Any unknown tool or data path blocks production access. |
| 3 | Write the agent policy as executable rules, not a policy PDF. Define what the agent can read, draft, recommend, write, and escalate. | Policy matrix with allow, warn, block, and require-approval outcomes. | High-risk side effects require pre-action approval. |
| 4 | Build the evaluation set. Use real historical cases where allowed, synthetic cases for privacy, and adversarial edge cases. | At least 50 cases: 30 normal, 10 edge, 10 adversarial or exception cases. | Every case has an expected outcome, expected tools, and forbidden actions. |
| 5 | Run the agent in sandbox with no write permissions. Capture inputs, context, tool requests, reasoning summaries if available, outputs, and latency. | Baseline eval report. | Do not optimize prompts until failures are classified. |
| 6 | Classify failures by outcome error, wrong tool, unsafe argument, missing escalation, data boundary issue, or trace gap. | Failure taxonomy and remediation backlog. | Critical failures in permissions or side effects block canary. |
| 7 | Add runtime controls: least privilege identity, tool allowlist, argument validation, rate limits, approval gates, and immutable logs. | Runtime control configuration. | Unknown actions fail closed. |
| 8 | Re-run the evaluation set and compare outcome, tool choice, execution path, blocked actions, and escalation quality. | Before-and-after eval comparison. | Controls must reduce unsafe actions without hiding failures. |
| 9 | Run exception simulations: missing records, conflicting policies, expired credentials, API errors, duplicate records, and unusual amounts. | Exception-handling report. | The agent must pause or escalate rather than invent missing facts. |
| 10 | Test human approval. Approvers must see the case, proposed action, source evidence, policy reason, risk rating, and rollback option. | Approval workflow evidence. | Approval must occur before the action, not after. |
| 11 | Run red-team cases. Try prompt injection, malicious attachments, sensitive data leakage, wrong account selection, and tool misuse. | Red-team failure report. | Any successful destructive or unauthorized action blocks production. |
| 12 | Define canary scope. Limit users, records, dollar amounts, systems, time window, and action types. | Canary plan with rollback and on-call owner. | No canary without rollback and incident owner. |
| 13 | Run a supervised canary in draft or assisted mode. Sample every run. Compare agent recommendation with human decision. | Canary evidence pack. | Do not expand scope if humans cannot explain disagreements. |
| 14 | Make the release decision: block, keep in sandbox, extend canary, or approve limited production. | Go/no-go memo with scorecard, risks, owners, and refresh date. | Production approval requires scorecard pass and zero critical failures. |
Agent production scorecard
Use the scorecard below for the go/no-go decision. A reasonable first threshold is 85 out of 100, with zero critical failures in permissions, side effects, auditability, or human approval. Do not average away a catastrophic control failure.
| Gate | Weight | Pass condition | Critical red flag |
|---|---|---|---|
| Business outcome accuracy | 20 | Agent reaches the correct final state across normal and edge cases. | Confidently completes the wrong customer, invoice, contract, account, or deployment task. |
| Tool choice | 15 | Agent uses approved tools for the task and avoids unnecessary high-risk tools. | Uses refund, payment, delete, deploy, send, or approve tool without policy basis. |
| Execution path | 15 | Agent follows required workflow steps and checkpoints. | Skips required match, review, risk check, legal approval, or test stage. |
| Data and permission boundaries | 15 | Agent only accesses allowed data and respects user, role, region, and system limits. | Retrieves or transmits sensitive data outside scope. |
| Runtime enforcement | 10 | Unsafe actions are blocked, rate-limited, or escalated before execution. | System only logs the unsafe action after it happens. |
| Human approval quality | 10 | Approver sees evidence, risk, proposed action, and rollback path before approval. | Approval is vague, post-action, or impossible to verify. |
| Traceability and audit | 10 | Inputs, context, tool calls, outputs, approvals, and policy decisions can be reconstructed. | Agent can modify its own logs or traces are missing. |
| Cost, latency, and reliability | 5 | Runtime cost and latency are acceptable for the workflow and fail safely under errors. | Retries, loops, or timeouts create hidden operational risk. |
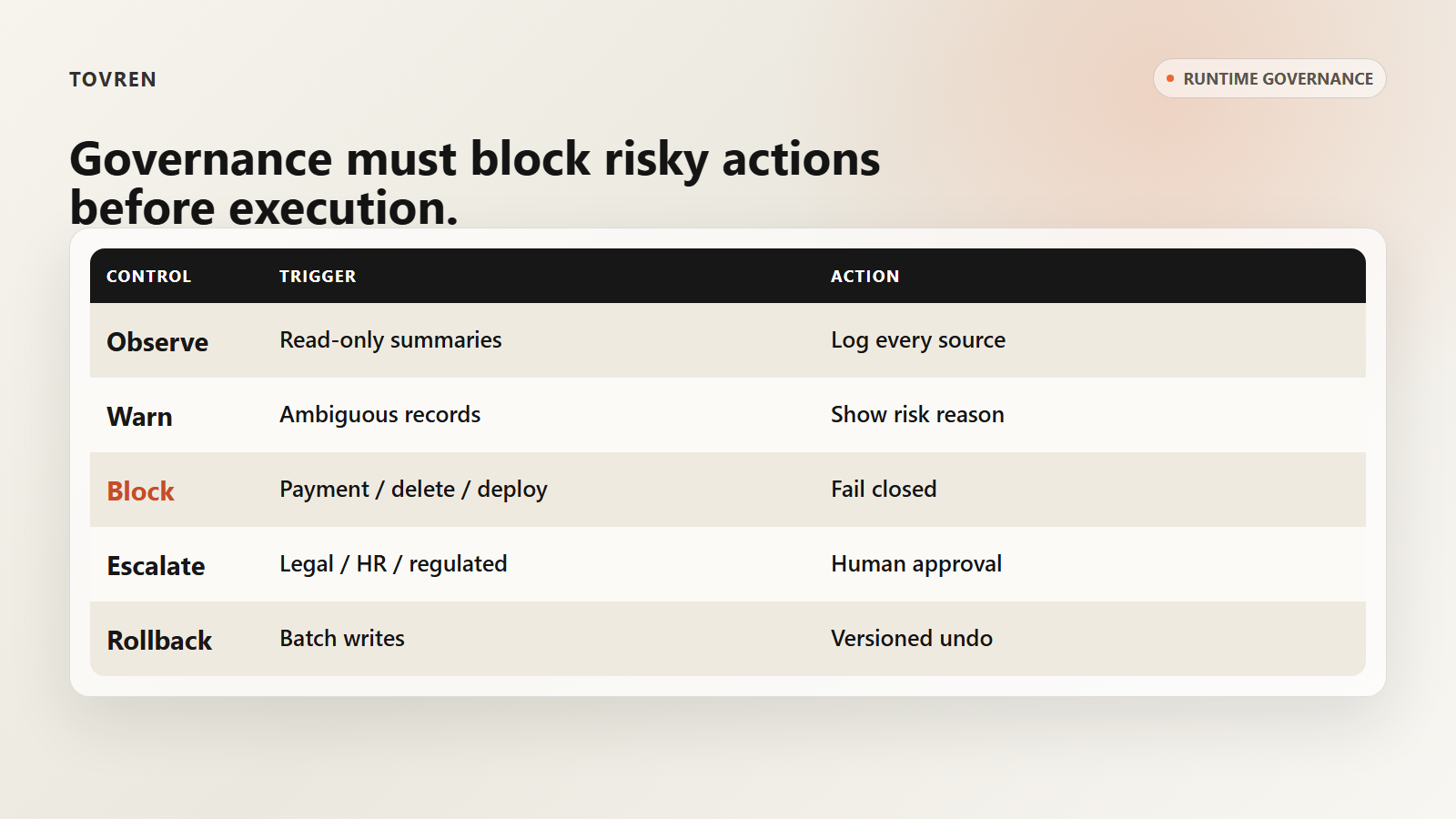
Runtime governance checklist
- Owner: Name the business owner, technical owner, risk reviewer, and on-call contact.
- Agent identity: Give the agent its own service identity. Do not reuse a human admin account.
- Least privilege: Separate read, draft, write, send, approve, delete, deploy, and pay permissions.
- Tool registry: Maintain an approved list of tools, actions, schemas, data classes, and forbidden arguments.
- Argument inspection: Validate the exact tool arguments before execution, especially account IDs, refund amounts, contract recipients, branch names, database hosts, and payment fields.
- Approval gates: Require human approval for destructive, external, financial, legal, HR, regulated, or customer-visible actions.
- Policy as code: Convert policy into runtime rules that can block, warn, route, or escalate.
- Trace capture: Store prompt, input, retrieved context, tool calls, outputs, approvals, and policy decisions in a log the agent cannot alter.
- Sandbox first: Simulate failures, exceptions, and edge cases before production.
- Canary limits: Limit users, volume, records, regions, dollar amount, systems, and action types during early rollout.
- Fallback: Define how the workflow returns to human operation when the agent is blocked, degraded, or uncertain.
- Review cadence: Re-run evals after model changes, tool changes, policy changes, prompt changes, connector changes, and workflow changes.
Vendor comparison: what to ask before buying or expanding
This is not a market-share ranking. It is a production-readiness comparison based on May 2026 public announcements and how each platform maps to agent evaluation and runtime governance needs.
| Vendor or platform | Best fit | Relevant May 2026 signal | Questions to ask in a pilot | Caveat |
|---|---|---|---|---|
| Automation Anywhere | Cross-system enterprise process automation such as invoices, HR operations, service workflows, and finance operations. | AI Evaluations available as of the May 19 announcement; Process Simulation, Optimization & Testing announced for process-level testing; Context Intelligence Graph in preview. | Can we export eval results? Can we replay traces? Can we test edge cases before deployment? How are tool calls and execution paths scored? How are failures monitored in runtime? | Some announced capabilities have preview or future GA timing, so validate availability in your tenant and region. |
| Glean | Enterprise knowledge and work agents that need traceability, sandboxing, access policy, and ongoing monitoring. | Enterprise Agent Development Lifecycle, Debug & Trace Views, Expanded Agent Sandbox, Agent Access Policies, and Agent Insights Dashboard. | Can admins see every input, tool call, LLM decision, and output? Can policies block sensitive content or write actions? What dashboard metrics prove value and safety? | Some capabilities are listed as beta or coming soon, so confirm status before depending on them for production control. |
| UiPath | Coding-agent-driven automation where generated automations must enter governed CI/CD and production operations. | UiPath for Coding Agents with orchestration, multiple coding agent support, policy enforcement, audit trails, credential vaults, RBAC, and runtime controls. | Can coding-agent output be forced through tests, code review, credential vaults, and deployment gates? Can unsafe tool arguments be blocked at runtime? | Strong fit for organizations already investing in orchestration and automation governance; less relevant if you only need a lightweight internal chatbot. |
| SAP | Core enterprise workflows where agents must operate inside business context, process data, and governed systems. | SAP Sapphire 2026 autonomous enterprise direction, SAP Business AI Platform, Joule Studio, partnerships for model choice, workflow orchestration, interoperability, and secure runtime. | How are Joule agents governed across SAP and non-SAP systems? How are external agent frameworks authorized? What runtime evidence is retained for regulated workflows? | Use SAP’s announcement as context for enterprise-platform direction, not as proof that every promised workflow is ready for your production case today. |
| Docusign | Agreement workflows across legal, sales, HR, procurement, and finance. | AI Assistant and agents for agreement work; open platform and MCP connections with Claude, Gemini, and ChatGPT; Docusign MCP globally in beta in English. | Can the agent prove which clause, policy, or precedent drove a recommendation? Can it route nonstandard terms to counsel? Can it prevent external send or approval without review? | Agreement agents are high-value but high-risk. Treat drafting, review, and obligation tracking differently from signing, sending, or approving commitments. |
The release rule: assisted first, autonomous later
For most teams, the first production step should not be full autonomy. Use this ladder:
- Read-only: Agent retrieves, summarizes, and explains.
- Draft: Agent prepares a proposed action, but a human executes it.
- Assisted write: Agent writes only after approval and within strict limits.
- Constrained automation: Agent executes low-risk actions under policy, logs, and rollback.
- Expanded autonomy: Agent handles more cases only after repeated eval passes and incident-free canaries.
Invoice exception triage might reach assisted write quickly. Contract commitments, HR access grants, refunds above threshold, CI/CD deployments, and banking workflows should move much slower.
What a good result looks like
At the end of the pilot, the team should not be arguing from vibes. It should have evidence:
- A workflow map showing systems, data, tools, side effects, and approval points.
- An evaluation set with normal, edge, exception, and adversarial cases.
- A scorecard with outcome accuracy, tool choice, execution path, runtime enforcement, and traceability.
- A runtime policy matrix that blocks unsafe actions before execution.
- A trace package showing inputs, retrieved context, tool calls, outputs, approvals, and policy decisions.
- A canary plan with strict limits, rollback, and an owner who can be paged.
The strongest signal is not that the agent succeeds on easy tasks. It is that the system behaves safely when the agent is uncertain, the data is messy, the user asks for too much, or the tool call would create a real-world side effect.
Bottom line
Enterprise agents are becoming production software. That means release gates, eval suites, sandbox tests, runtime controls, audit trails, and owners. If an agent cannot be evaluated, traced, constrained, and rolled back, it is not ready to operate a real workflow.
Use the 14-day pilot to force the decision. Ship a narrow assisted workflow only if the agent passes the scorecard and the runtime can block unsafe actions before they happen. Otherwise, keep it in sandbox. That is not slowing AI down. It is how enterprise automation earns the right to run.
Source log
Source access date: May 28, 2026.
| Publisher | Date | Accessed | Used for | Source |
|---|---|---|---|---|
| Automation Anywhere via PRNewswire | May 19, 2026 | May 28, 2026 | AI Evaluations, design-time and runtime assessment, correct outcome, right tool use, execution paths, Process Simulation, Context Intelligence Graph, preview and availability details. | Automation Anywhere 2026 platform enhancements |
| Glean | May 12, 2026 | May 28, 2026 | Enterprise Agent Development Lifecycle, Debug & Trace Views, Expanded Agent Sandbox, Agent Access Policies, Agent Insights Dashboard, lifecycle framing. | Glean Enterprise Agent Development Lifecycle |
| UiPath | May 12, 2026 | May 28, 2026 | UiPath for Coding Agents, build/test/deploy/operate/govern framing, orchestration, policy enforcement, audit trails, credential vaults, RBAC, runtime controls. | UiPath for Coding Agents launch |
| SAP News Center | May 12, 2026 | May 28, 2026 | Context on autonomous enterprise direction, SAP Business AI Platform, orchestration, secure runtime, interoperability, and partnerships. | SAP Sapphire 2026 autonomous enterprise announcement |
| Docusign | May 21, 2026 | May 28, 2026 | AI Assistant and agents for agreement work, MCP connections with Claude, Gemini, and ChatGPT, agreement workflow examples, availability details. | Docusign AI Assistant and agents announcement |
| Reddit r/AI_Agents | May 2026 thread, relative timestamp visible at access | May 28, 2026 | Anecdotal community signal on the policy-versus-runtime enforcement gap. Not used as proof of adoption rates or incident rates. | AI governance enforcement discussion |
| Reddit r/AI_Governance | May 2026 thread, relative timestamp visible at access | May 28, 2026 | Anecdotal community signal on ownership of real-time enforcement for agents. Not used as proof of adoption rates or incident rates. | Real-time enforcement ownership discussion |
| Reddit r/sre | May 2026 thread, relative timestamp visible at access | May 28, 2026 | Anecdotal community signal on observability versus enforcement and SRE-style runtime governance concerns. Not used as proof of adoption rates or incident rates. | AI agent governance tools by enforcement layer |