Short answer: Model benchmarks are useful only when they match the job. Use leaderboards to shortlist Claude, GPT, Gemini, Grok, and open models, then decide by task quality, latency, cost, tooling, and governance.
Verdict
There is no universal best AI model in May 2026. Treat Claude Opus 4.7, Gemini 3.1 Pro, and GPT-5.4 as a top frontier cluster, then pick by task. Use Claude first for complex coding, agentic software work, and high-stakes business writing. Use Gemini first for long research, science reasoning, and visual or video-heavy workflows. Use GPT-5.4 when you need a balanced daily assistant, structured automation, and broad ecosystem compatibility. For cheap API routing, test DeepSeek V4 Pro, GLM-5.1, Qwen3.6 Plus, and MiMo-V2.5-Pro before sending everything to a premium model.
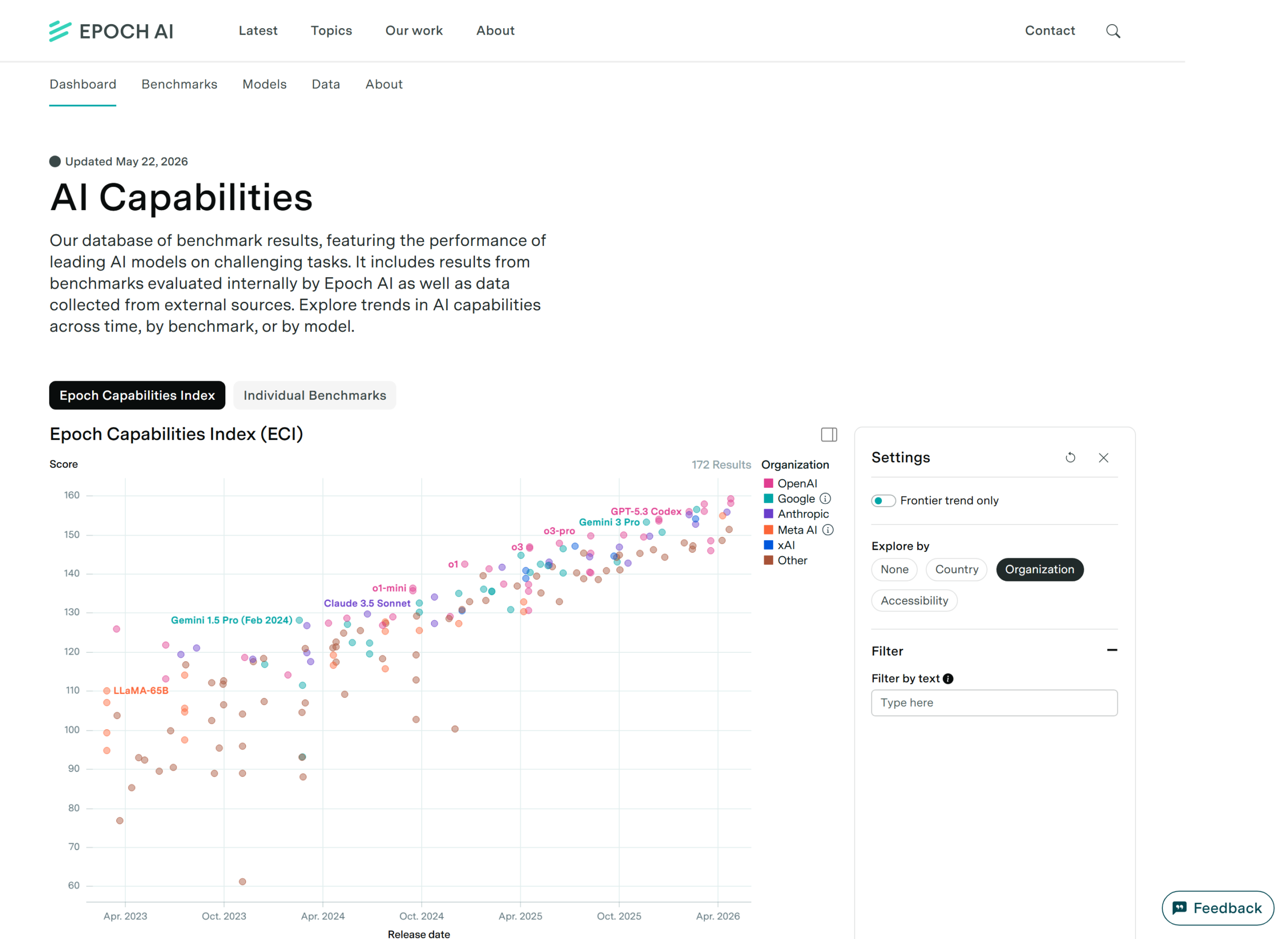
The May 2026 scoreboard
The headline race is tight. LMSpeed’s Intelligence Index leaderboard, updated May 21, 2026, ranks models by the imported Artificial Analysis Intelligence Index aggregate score. Its top three are separated by only 0.5 points: Claude Opus 4.7 at 57.3, Gemini 3.1 Pro at 57.2, and GPT-5.4 at 56.8. That is a useful signal, not a mandate to buy one subscription and ignore every other model.
Epoch AI’s benchmark database adds a second lens: it tracks leading models across challenging tasks, including Epoch-evaluated and externally collected results. A Feb. 27, 2026 PitchBook heatmap, now older but still useful for domain context, had Gemini 3.1 Pro strong in GPQA Diamond, ARC-AGI-2, and Terminal-Bench; Claude Opus 4.6 strong in SWE-bench Verified, OSWorld, creative writing, and GDPval-AA; GPT-5.2 competitive but not dominant; and Grok 4.1 behind the top three in that comparison.
| Model | Aggregate signal | Useful domain signal | Practical caveat |
|---|---|---|---|
| Claude Opus 4.7 | LMSpeed / Artificial Analysis Intelligence Index: 57.3, rank 1 | LMArena text pages show Claude Opus variants near the top; PitchBook’s Feb. context favored Claude Opus 4.6 for SWE-bench and agentic work. | Likely premium quality, but do not route cheap, repetitive work here by default. |
| Gemini 3.1 Pro | LMSpeed / Artificial Analysis Intelligence Index: 57.2, rank 2 | PitchBook showed strength in GPQA Diamond, ARC-AGI-2, and Terminal-Bench; Epoch FrontierMath notes show Gemini 3 Pro Preview at 38% private and 19% Tier 4. | Strong reasoning signals do not automatically mean best prose, coding UX, or enterprise fit. |
| GPT-5.4 | LMSpeed / Artificial Analysis Intelligence Index: 56.8, rank 3 | LMArena lists GPT-5.4-high in the top band, below leading Claude and Gemini entries on the text page accessed. | Best judged as a broad, ecosystem-friendly model, not a clean benchmark champion. |
| MiMo-V2.5-Pro | LMSpeed / Artificial Analysis Intelligence Index: 53.8, rank 4 | Important as a cost and routing candidate if your own evals confirm quality. | Do not assume frontier reliability from one aggregate rank. |
| GPT-5.3 Codex | LMSpeed / Artificial Analysis Intelligence Index: 53.6, rank 5 | Relevant for coding-tuned workflows and developer tooling comparisons. | Use coding-specific tests before switching IDE workflows. |
| DeepSeek V4 Pro, GLM-5.1, GPT-5.2, Qwen3.6 Plus, GLM-5 | LMSpeed places these in the next cluster from 51.5 to 49.8 | Shortlist for API routing, low-cost automation, and open or self-hosted evaluation. | Validate license, latency, data handling, and failure rate before production use. |

Why rankings disagree
Rankings disagree because they measure different jobs. LMArena is useful for broad open-ended preference signals across text, coding, writing, math, and other categories. The Artificial Analysis Intelligence Index is an aggregate benchmark view. FrontierMath is a specialized research-level math benchmark. SWE-bench is closer to real software engineering than old code puzzles. GPQA is a scientific reasoning signal, not a full research workflow.
That is why a model can look brilliant on one chart and ordinary in your product. A long-context research assistant can fail at concise executive writing. A coding model that solves isolated bugs can get lost in your monorepo. Community discussions in Claude, Singularity, and LocalLLaMA circles reflect the same mood: users are tired of models acing one benchmark and failing another. Treat that as sentiment, not evidence.

Task-by-task model picker
For the best AI model May 2026 decision, start with the task, not the leaderboard. Here is the practical version of Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro.
| Task | Start with | Also test | Why |
|---|---|---|---|
| Complex coding, repo repair, agentic software work | Claude Opus 4.7 or Claude Opus 4.6 | GPT-5.3 Codex, GPT-5.4, Gemini 3.1 Pro | Claude leads several arena and domain signals for coding-style work; GPT Codex variants may fit developer tooling better. |
| Long research over documents, transcripts, filings, and notes | Gemini 3.1 Pro | GPT-5.4, Claude Opus 4.7 | Gemini’s aggregate and domain reasoning signals make it a good first test for long-context research. |
| Science and hard math reasoning | Gemini 3.1 Pro / Gemini 3 Pro family | Claude Opus 4.7, GPT-5.4 | GPQA and FrontierMath-style signals favor Gemini in several snapshots, but hard math remains benchmark-specific. |
| Business writing, strategy memos, board-ready drafts | Claude Opus 4.7 | GPT-5.4, Claude Sonnet-class models | Claude remains a strong default for nuance, tone control, and rewriting; run a house-style eval. |
| Image, video, and multimodal workflow planning | Gemini 3.1 Pro | GPT-5.4 plus specialist image/video tools | Use Gemini first when visual context is central; use GPT or Claude when final generation happens elsewhere. |
| Cheap API routing for summaries, extraction, tagging, support drafts | DeepSeek V4 Pro, GLM-5.1, Qwen3.6 Plus, MiMo-V2.5-Pro | GPT-5.4 Mini, Gemini Flash-class models, Claude Sonnet-class models | Do not spend flagship money on low-risk repetitive tasks unless failure costs are high. |
| Open-weight or self-hosted evaluation | GLM-5.1, Qwen3.6 Plus, DeepSeek V4 Pro | Kimi / other open-license contenders visible in arena lists | Pick by license, hardware, privacy, and latency; the leaderboard is only the first filter. |
| General daily assistant for paid subscribers | GPT-5.4, Claude Opus 4.7, or Gemini 3.1 Pro | The cheaper tier from the same provider | Choose by ecosystem: OpenAI for automation breadth, Claude for prose and coding feel, Gemini for Google-native research and multimodal work. |
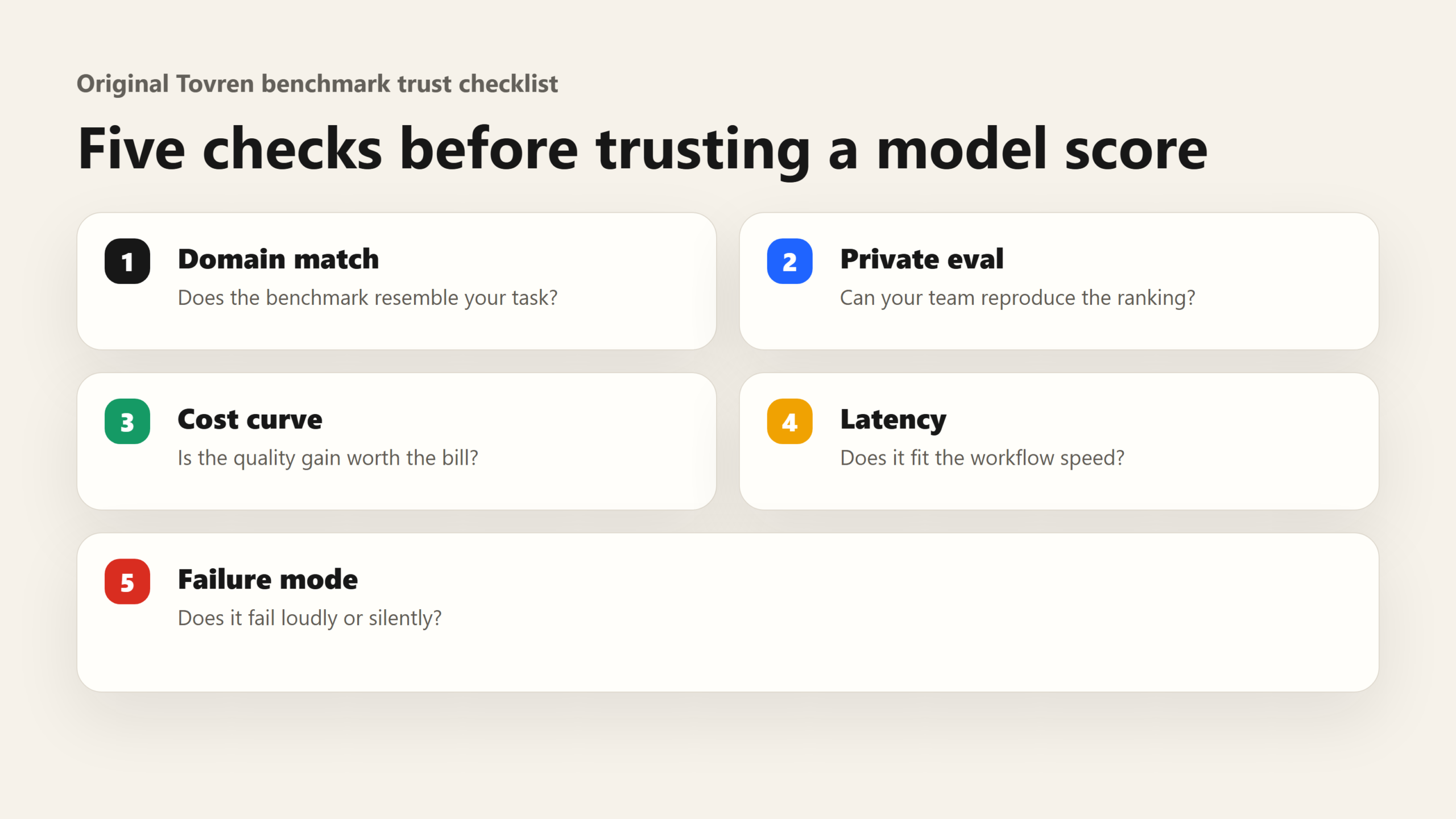
Benchmark trust framework
Use this five-part filter before trusting any AI model benchmarks 2026 claim. First, check whether the benchmark matches your job: SWE-bench is more relevant to repo repair than HumanEval, and FrontierMath is not a normal business reasoning test. Second, check whether the leaderboard is aggregate, domain-specific, or human preference. Third, check whether the result is independent, vendor-reported, or collected from mixed sources. Fourth, check the operating setup: context length, tool use, retries, scaffolding, temperature, and API errors can change results. Fifth, convert quality to cost. A two-point gain is not worth a 10x bill for bulk extraction unless that gain prevents expensive human review.
For procurement, build a 50-task private eval: ten coding tasks, ten research tasks, ten writing tasks, ten automation tasks, and ten failure-mode tasks. Score correctness, citation hygiene, instruction following, latency, cost, and escalation behavior. Then route by confidence: cheap model first, premium model on hard cases, human review on regulated or customer-facing claims.
Buyer recommendations
For individual paid subscriptions: choose the model whose interface matches your daily work. Writers and developers should try Claude first. Researchers and analysts working with long documents should try Gemini first. Operators who need custom assistants, automations, API compatibility, or broad tool integrations should keep GPT-5.4 in the mix.
For teams: avoid a single-model mandate. Standardize on two premium models and one cheaper routing tier: Claude for code and writing, Gemini for research and multimodal analysis, GPT-5.4 for automation and assistant work, and a DeepSeek / GLM / Qwen / MiMo tier for bulk jobs.
For API builders: start with the cheapest model that passes your own eval. Escalate only when the task has ambiguity, long context, high customer impact, or expensive downstream errors. Log prompts, model versions, cost, latency, and failures.
For more buying guides, compare this with Tovren’s AI Tools, Automation & Agents, Business AI, and AI Papers coverage.
What not to do
Do not buy the model that is number one on one leaderboard and call procurement finished. Do not compare Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro using only vibes from X, Reddit, or YouTube. Do not treat FrontierMath as proof that a model will handle finance, law, medicine, or business strategy. Do not treat LMArena as a factual accuracy benchmark. Do not move sensitive data into a cheaper API until legal, security, retention, and regional processing questions are answered. And do not ignore latency: a slightly weaker model that answers in two seconds can beat a stronger one that breaks your workflow.
FAQ
What is the best AI model in May 2026?
There is no clean universal winner. Claude Opus 4.7, Gemini 3.1 Pro, and GPT-5.4 form the practical top cluster, with different strengths by task.
Which benchmark should I trust most?
Trust the benchmark closest to your workload. Use SWE-bench for software engineering, GPQA for scientific reasoning signals, FrontierMath for research-level math, LMArena for broad preference, and an aggregate index only as a first-pass overview.
Is Claude Opus 4.7 better than GPT-5.4?
For coding, writing, and some agentic software workflows, Claude is the better first test. GPT-5.4 may be the better platform choice if your workflow depends on OpenAI-compatible automation, tools, and integrations.
Is Gemini 3.1 Pro better than Claude Opus 4.7?
For long research, science reasoning, and multimodal workflows, Gemini is the stronger first test. For prose, code review, and developer feel, Claude remains highly competitive.
Should I use open-weight or self-hosted models?
Use them when privacy, cost, customization, or deployment control matters. But benchmark rank is not enough: confirm license terms, hardware cost, latency, maintenance burden, and safety review.
Source Log
| Source | Publisher | Date / access | Claims supported |
|---|---|---|---|
| LMSpeed Intelligence Index Model Leaderboard | LMSpeed | Updated May 21, 2026; accessed May 23, 2026 | Artificial Analysis Intelligence Index aggregate ranking and top scores. |
| AI Capabilities and Benchmarking | Epoch AI | Updated May 22, 2026; accessed May 23, 2026 | Benchmark database scope and benchmark categories. |
| FrontierMath Tier 4 | Epoch AI | Accessed May 23, 2026 | FrontierMath difficulty and Gemini 3 Pro Preview notes. |
| Ranking the AI Giants: A New Framework for the Frontier Five | PitchBook | As of Feb. 27, 2026; accessed May 23, 2026 | Older domain heatmap for GPT-5.2, Claude Opus 4.6, Gemini 3.1 Pro, and Grok 4.1. |
| LMArena Text Leaderboard | LMArena / Arena | Page labeled May 17, 2026; accessed May 23, 2026 | Arena ranking, votes, category pages, and top-band Claude, Gemini, and GPT entries. |
Refresh Triggers
- Refresh within 24 hours when OpenAI, Anthropic, Google, xAI, DeepSeek, Qwen, GLM, Kimi, or MiMo releases a new frontier model.
- Refresh when LMSpeed or Artificial Analysis changes the top-three Intelligence Index order by more than one point.
- Refresh when LMArena publishes a new overall, coding, software, image, or video leaderboard that changes the top cluster.
- Refresh when Epoch AI updates FrontierMath, SWE-bench, GPQA, or the Epoch Capabilities Index with new frontier results.
- Refresh pricing and context-window recommendations monthly.