Short answer: Gemini 3.5 Flash should be judged by speed, price, and real workload quality, not launch hype. Test it on summarization, extraction, coding support, and agent routing before moving production traffic.
Verdict first
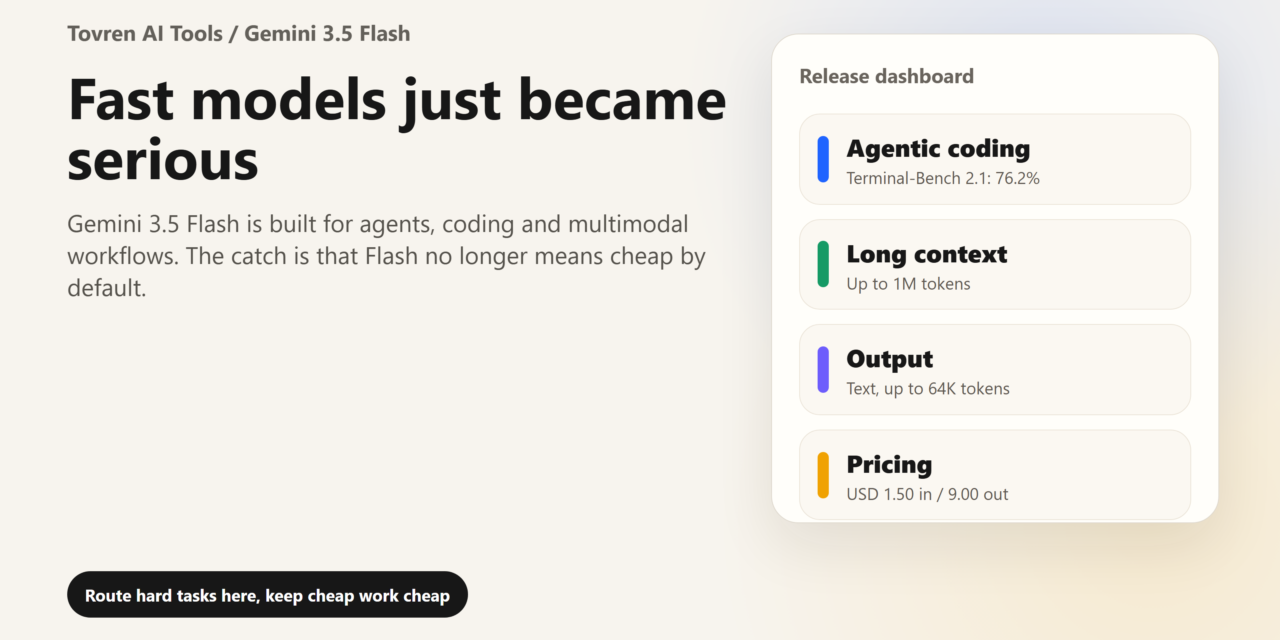
Gemini 3.5 Flash is the first fast model from Google that deserves to be treated as a serious default for agentic coding, long-context reasoning, multimodal analysis, and high-speed tool workflows. Developers should test it now if they run multi-step coding agents, document-heavy workflows, financial or operational analysis, UI generation, or apps where latency directly affects user experience.
But do not blindly replace every previous Flash deployment. At $1.50 per 1 million input tokens and $9.00 per 1 million output tokens on the standard paid API tier, Gemini 3.5 Flash is priced much closer to a premium reasoning model than an old “cheap fast model.” The output price includes thinking tokens, so long reasoning chains can become the real bill driver.
The practical read: use Gemini 3.5 Flash where speed plus reasoning creates value, not where your workload only needs cheap extraction, classification, translation, or summarization.
What launched
Google announced Gemini 3.5 on May 19, 2026, starting the family with Gemini 3.5 Flash. According to Google’s official launch post, 3.5 Flash is available globally in the Gemini app and AI Mode in Search. For developers, it is available through Google Antigravity, the Gemini API in Google AI Studio, and Android Studio. For enterprises, it is available in Gemini Enterprise Agent Platform and Gemini Enterprise.
The model ID for developers is gemini-3.5-flash. Google’s developer documentation describes it as its most intelligent model for sustained frontier performance in agentic and coding tasks. It supports a 1 million-token context window, up to about 64K output tokens, and thinking controls. Google’s docs also note that Computer Use is not supported at this moment, which matters for teams building browser or desktop-control agents.
Google says Gemini 3.5 Pro is already in internal use and planned for rollout next month. That makes 3.5 Flash the model to test now, but not necessarily the final 3.5 model to standardize on for the hardest workloads.
Why this release matters
The old model-selection rule was simple: use “Flash” when you needed speed and cost control; use “Pro” when you needed deeper reasoning. Gemini 3.5 Flash blurs that line. Google is positioning it as a fast model that can handle agentic execution, coding, tool use, long-context work, and multimodal reasoning at a level that previously belonged to larger flagship models.
That matters for two groups:
- Developers and AI product teams: faster agent loops mean more attempts, more tool calls, and more user-visible iteration before latency becomes unacceptable.
- AI users in Gemini and Search: a fast model with stronger reasoning can make everyday research, planning, coding help, chart reading, and document analysis feel less like waiting on a heavyweight model.
The main decision is not “Is Gemini 3.5 Flash good?” The better question is: which jobs justify paying for this much reasoning at Flash speed?

Benchmark snapshot
Google’s benchmark claims are strong, especially for coding, agentic workflows, UI control, multimodal reasoning, finance tasks, and abstract reasoning. Treat them as vendor-reported results, not as a replacement for your own production tests.
| Area | Benchmark or claim | Gemini 3.5 Flash result | Practical meaning |
|---|---|---|---|
| Coding agents | Terminal-Bench 2.1 | 76.2% | Stronger signal for terminal-based agentic coding tasks. |
| Agentic coding | SWE-Bench Pro public | 55.1% | Useful for repo-level repair tests, though still not a guarantee on private codebases. |
| Tool workflows | MCP Atlas | 83.6% | Relevant for multi-step workflows using external tools and context protocols. |
| General tool use | Toolathlon | 56.5% | Suggests better tool orchestration, but needs testing against your own APIs. |
| UI control | OSWorld-Verified | 78.4% | Promising for interface reasoning, though Google’s docs say Computer Use is not currently supported for this model. |
| Economic work | GDPval-AA | 1656 Elo | Strong vendor-reported score for economically valuable knowledge work. |
| Finance | Finance Agent v2 | 57.9% | Worth testing for analysis support, not autonomous financial decisions. |
| Charts and visual reasoning | CharXiv Reasoning | 84.2% | Good fit for chart-heavy reports, scientific figures, dashboards, and visual summaries. |
| Multimodal reasoning | MMMU-Pro | 83.6% | Supports the case for mixed text-image reasoning workflows. |
| Spatial reasoning | Blueprint-Bench 2 | 33.6% | Interesting for layout and spatial tasks, but still an area to validate carefully. |
| Long context | MRCR v2, 128K average | 77.3% | Useful for large documents and codebases, but long-context accuracy can still degrade by task type. |
| Long context | 1M pointwise | 26.6% | Do not assume the full 1M context window gives perfect recall. |
| Hard reasoning | Humanity’s Last Exam | 40.2% | Strong for a fast model, but not a reason to remove expert review. |
| Abstract reasoning | ARC-AGI-2 | 72.1% | Suggests major reasoning gains, but benchmark transfer varies by product use case. |
| Speed | Output tokens per second | Google claims 4x faster than other frontier models | The core reason to test it for interactive agents and user-facing tools. |
Pricing hidden tradeoff
The biggest misunderstanding will be the name. “Flash” sounds cheap, but Gemini 3.5 Flash is priced as a high-capability fast model. That is not automatically bad. A model can be more expensive per token and still cheaper per completed task if it needs fewer retries, finishes faster, or replaces a slower flagship model. But teams must measure task cost, not just token price.
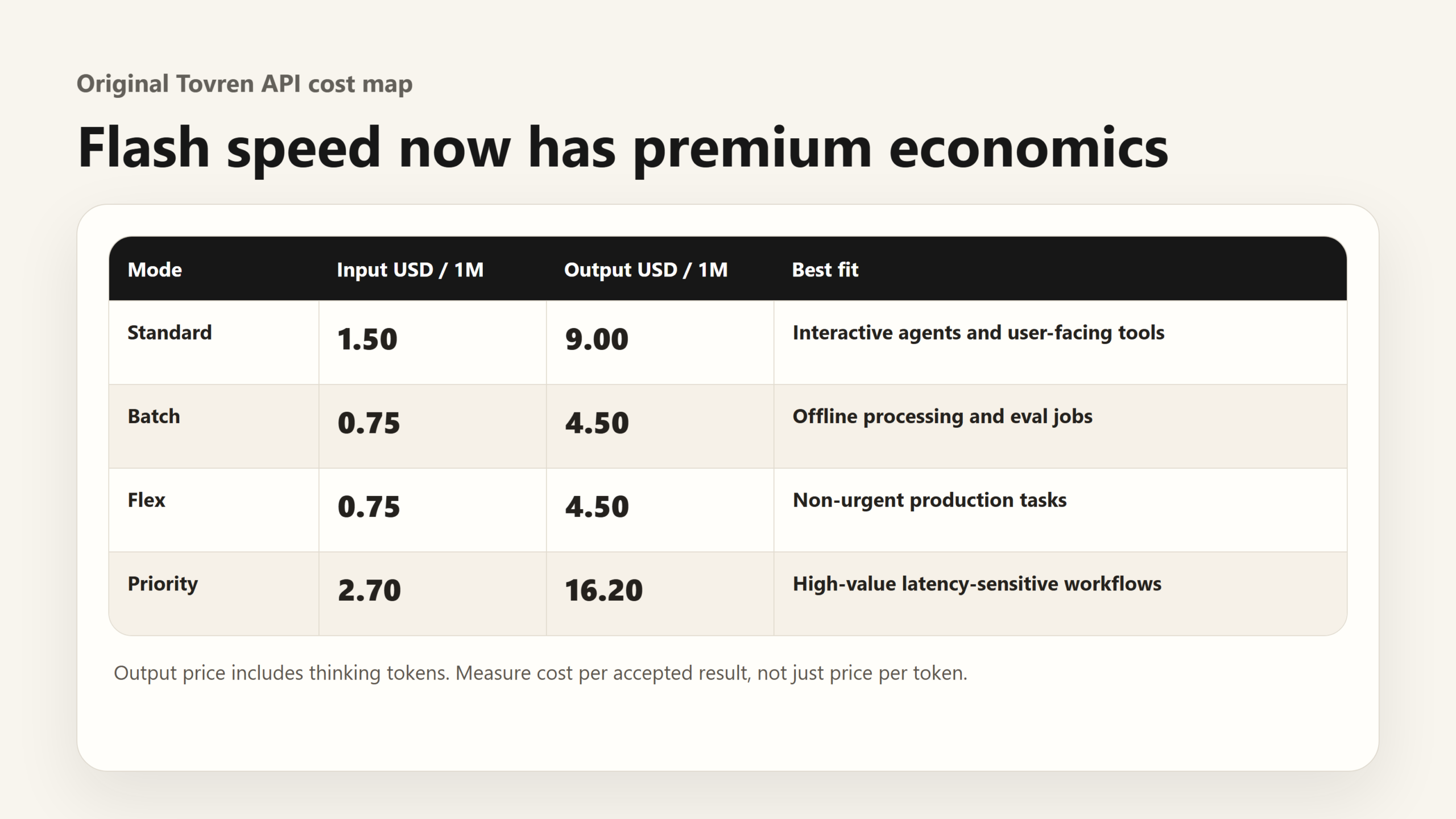
| Pricing mode | Input price | Output price | Hidden tradeoff | Best fit |
|---|---|---|---|---|
| Standard paid | $1.50 per 1M tokens | $9.00 per 1M tokens, including thinking | Output-heavy reasoning can get expensive quickly. | Interactive apps, production agents, coding assistants, user-facing workflows. |
| Context caching | $0.15 per 1M cached tokens | Storage: $1.00 per 1M tokens per hour | Caching helps repeated long-context workloads, but storage time still matters. | Repeated analysis over the same codebase, contract set, policy manual, or dataset. |
| Batch | $0.75 per 1M tokens | $4.50 per 1M tokens | Cheaper, but not for low-latency user interactions. | Offline evaluation, bulk document processing, nightly agent runs. |
| Flex | $0.75 per 1M tokens | $4.50 per 1M tokens | Lower cost with availability and latency tradeoffs depending on capacity. | Non-urgent production workloads where cost matters more than guaranteed speed. |
| Priority | $2.70 per 1M tokens | $16.20 per 1M tokens | Premium throughput can make sense only when latency or reliability is worth the margin. | High-value enterprise workflows, customer-facing agents, peak-hour workloads. |
| Search and Maps grounding | 5,000 prompts per month free, shared across Gemini 3 | Then $14 per 1,000 search queries | One user prompt may trigger multiple search queries, so grounding cost can exceed expectations. | Fresh research, location-aware workflows, source-backed answers, enterprise knowledge tasks. |
| Compared with older Flash tiers | Higher than prior low-cost Flash options | Higher than prior low-cost Flash options | Community concern about the price jump is reasonable; the model should be evaluated as “fast frontier,” not “cheap Flash.” | Switch only when better success rate, speed, or lower retry count offsets the higher token price. |
For developers coming from earlier Flash models, the practical cost test is simple: run the same workload on your current model and on Gemini 3.5 Flash, then compare cost per accepted result. If 3.5 Flash solves the task in one attempt where the older model needs three attempts, it may still win. If the older model already performs well, the price increase may be hard to justify.
Best use cases
1. Agentic coding loops. Gemini 3.5 Flash is most interesting when the model must plan, write, inspect, fix, and retry. Use it for codebase migration, test generation, bug triage, refactoring plans, and local developer copilots that need speed.
2. Long-context document work. With up to a 1M-token context window, it can process large contracts, reports, manuals, support logs, research packs, and code repositories. The caution: a large window is not the same as perfect recall, so build retrieval checks and citation requirements into your workflow.
3. Multimodal analysis. The model card says Gemini 3.5 Flash accepts text, images, audio, and video, and outputs text. That makes it a strong candidate for chart explanation, invoice reasoning, UI review, video-summary workflows, and dashboard interpretation.
4. Enterprise process automation. Google’s launch examples emphasize multi-step enterprise work: onboarding documents, financial analysis, merchant forecasting, tax-form workflows, and data operations. Those are exactly the places where latency, context length, tool use, and reliability all matter.
5. Fast AI Mode and Gemini app help. For everyday users, the value is less about API pricing and more about better answers without the sluggishness usually associated with frontier models. It should be especially useful for planning, coding help, research synthesis, and visual reasoning.
Who should not switch yet
Do not switch by default if your workload is mostly cheap automation. If you are doing high-volume classification, translation, short summarization, data cleanup, sentiment tagging, or simple extraction, cheaper Flash-Lite or older Flash options may still be the better economic choice.
Do not switch without cost telemetry. Because output pricing includes thinking tokens, teams need logging for input tokens, output tokens, thinking-related output, retries, grounded search calls, and final accepted results. A benchmark win is not the same as a margin win.
Do not switch if you need Computer Use today. Google’s developer documentation says Gemini 3.5 Flash does not support Computer Use at this moment. If your agent needs direct browser or desktop interaction, validate platform support before committing.
Do not switch regulated workflows without human review. Finance Agent v2 and GDPval-AA results are impressive, but they do not make the model an autonomous financial, legal, medical, or compliance decision-maker. Use it to assist analysis, draft recommendations, and flag evidence, not to remove accountability.
Do not standardize before checking Gemini 3.5 Pro. Google says 3.5 Pro is planned next month. If your workload is extremely hard reasoning, sensitive enterprise decisioning, or expensive code automation, test 3.5 Flash now but leave room for a Pro comparison in June 2026.

Practical test plan
Before replacing an existing model, run a controlled test on real tasks. Do not use only public benchmarks or cherry-picked prompts. Use your own inputs, your own failure modes, and your own cost thresholds.
| Test | How to run it | Metric to track | Pass condition |
|---|---|---|---|
| Quality baseline | Run 100 to 300 representative tasks against your current model and Gemini 3.5 Flash. | Human acceptance rate, correction rate, severity of errors. | 3.5 Flash improves accepted outputs enough to justify higher token cost. |
| Latency test | Measure end-to-end response time, not just first-token speed. | P50, P90, P99 latency; output tokens per second. | User-visible latency improves or stays within your product target. |
| Cost per accepted task | Include input, output, thinking, retries, tool calls, context caching, and grounding. | Total cost divided by accepted completed tasks. | Cost per accepted result is equal or lower, or the quality lift is worth the premium. |
| Long-context recall | Ask questions that require evidence from early, middle, and late sections of long documents. | Recall accuracy, citation accuracy, missed-evidence rate. | The model reliably finds and uses the right evidence across your context length. |
| Tool-use reliability | Run workflows involving APIs, database lookups, retrieval, code execution, or MCP-style tools. | Wrong tool calls, skipped steps, invalid arguments, recovery success. | Tool failures decrease versus your current model. |
| Grounding cost control | Test Search or Maps grounding with realistic user prompts. | Queries triggered per prompt, grounded answer quality, extra cost. | Grounding improves factuality enough to justify query fees. |
| Safety and escalation | Test borderline prompts, sensitive domains, private data, and refusal behavior. | Unsafe completions, over-refusals, hallucinated authority, escalation accuracy. | The model follows policy and escalates uncertain cases to a human or safer workflow. |
Recommended rollout path
Start with a narrow migration, not a platform-wide replacement. Pick one workflow where Gemini 3.5 Flash’s speed and reasoning can clearly matter: coding repair, long-document review, multimodal report analysis, or an agent loop with tool calls.
Then run a two-week comparison with three model lanes: your current model, Gemini 3.5 Flash standard, and Gemini 3.5 Flash Batch or Flex where latency is not critical. Add Priority only if the workload has measurable value from faster or more reliable throughput.
For AI apps, expose it first to internal testers or a small percentage of production traffic. Log failure types, retries, token usage, grounding calls, and user ratings. If it wins on accepted outputs and latency but loses on cost, try tighter prompts, lower thinking settings where available, context caching, or routing only harder tasks to 3.5 Flash.
FAQ
Is Gemini 3.5 Flash generally available?
Yes. Google says Gemini 3.5 Flash is generally available through Google Antigravity, Gemini API in Google AI Studio and Android Studio, Gemini Enterprise Agent Platform, and Gemini Enterprise. It is also available in the Gemini app and AI Mode in Search.
What is the Gemini 3.5 Flash model ID?
The developer model ID is gemini-3.5-flash.
What inputs and outputs does it support?
The Google DeepMind model card says Gemini 3.5 Flash accepts text, images, audio, and video, with up to a 1M-token context window. It outputs text with up to a 64K-token output limit.
Is Gemini 3.5 Flash cheaper than previous Flash models?
Not necessarily. The standard paid API price is $1.50 per 1M input tokens and $9.00 per 1M output tokens. That is meaningfully higher than older low-cost Flash tiers. The right comparison is cost per accepted completed task, not model name.
Does output pricing include thinking tokens?
Yes. Google’s pricing page says output pricing includes thinking tokens. That makes reasoning length a key cost-control variable.
Should developers replace Gemini 2.5 Flash or Gemini 3 Flash immediately?
No. Test first. Gemini 3.5 Flash is compelling for difficult coding, agentic, long-context, and multimodal tasks. For simple high-volume tasks, older or lighter models may remain more economical.
Does Gemini 3.5 Flash support Computer Use?
Google’s developer documentation says Computer Use is not supported at this moment. Teams building UI-control or browser-control agents should verify platform support before migrating.
When is Gemini 3.5 Pro coming?
Google says Gemini 3.5 Pro is already being used internally and is planned for rollout next month. Based on the May 19, 2026 announcement, that points to June 2026, but exact public availability still needs to be confirmed by Google.
Bottom line
Gemini 3.5 Flash is important because it changes what a “fast” model can reasonably be asked to do. It is not just for quick answers. It is aimed at coding agents, long-horizon workflows, multimodal reasoning, and enterprise automation where speed and intelligence both matter.
The upgrade path is clear: test it on hard workflows first, measure cost per accepted result, and keep cheaper Flash models for simple scale tasks. If your product has been waiting for a model that can reason like a frontier system while responding like a fast one, Gemini 3.5 Flash belongs on your shortlist.
Source Log
- Google official launch blog: “Gemini 3.5: frontier intelligence with action”, Google, published May 19, 2026. Used for launch timing, availability, 3.5 Pro status, benchmark claims, and speed claim.
- Google DeepMind model card: “Gemini 3.5 Flash – Model Card”, Google DeepMind, published May 19, 2026. Used for model description, modalities, context window, output limit, architecture basis, benchmark table, safety notes, and intended use.
- Gemini API pricing: “Gemini Developer API pricing”, Google AI for Developers, accessed May 23, 2026. Used for model ID, standard pricing, Batch, Flex, Priority, context caching, storage, Search grounding, Maps grounding, and thinking-token billing.
- Gemini API developer documentation: “What’s new in Gemini 3.5 Flash”, Google AI for Developers, accessed May 23, 2026. Used for model ID, 1M context window, 65K max output note, thinking support, platform features, and Computer Use limitation.
- Google AI Developers Forum: “Gemini 3.5 Flash is more expensive than 3.1?”, community discussion, May 19, 2026. Used only as a community-sentiment signal around pricing concerns, not as a factual source for official pricing.