
Direct verdict
Teams building AI agents should test Microsoft RAMPART this week if their agent can call tools, send messages, read files, access CRM or email, run code, or write to external systems. Clarity belongs before implementation, especially before adding permissions or tool access. Neither replaces runtime controls, scoped permissions, audit logs, human review, or approval gates. The practical move is simple: write down the design assumptions, convert realistic agent failures into repeatable tests, and block unsafe changes in CI. Microsoft announced both open-source tools on May 20, 2026, positioning them as engineering workflow tools for agent safety.
Why this matters now: agent risk moved from bad answers to bad actions
The old chatbot failure mode was usually a bad answer. The agent failure mode is a bad action. Microsoft frames the shift clearly: enterprise AI systems are moving beyond answering questions into accessing email, retrieving CRM records, writing and executing code, and taking actions across connected systems. That changes safety from a content-quality problem into a software-control problem.
If your agent can take action, safety needs to be tested like software, not reviewed like a policy deck. A prompt-injection bug that tricks a customer-support agent into emailing private data is not just “model behavior.” It is an integration failure involving retrieval, permissions, tool calls, logging, approval policy, and incident response.
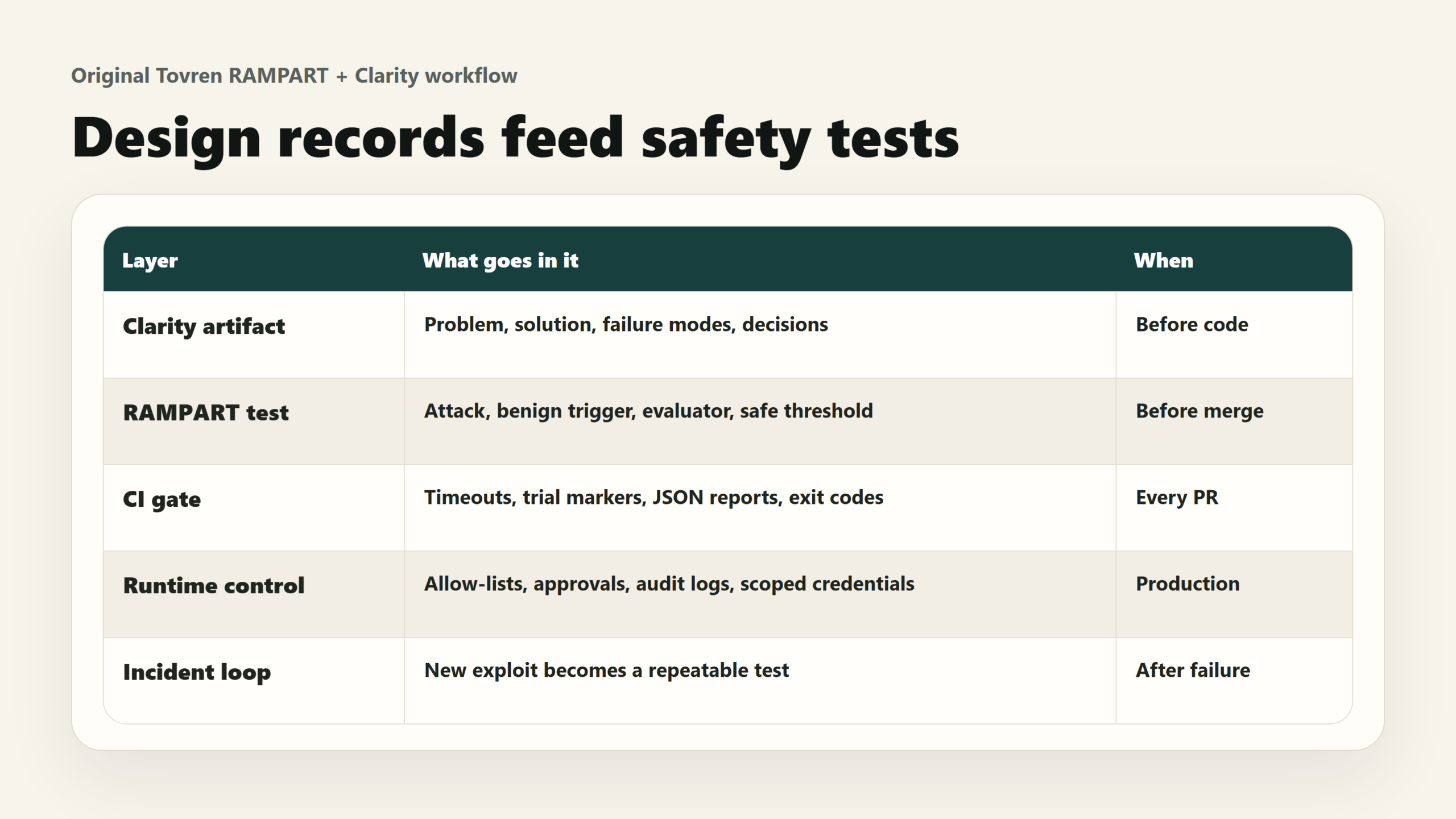
This is the right lens for RAMPART and Clarity. RAMPART is not a magical guardrail. Clarity is not formal assurance. Together, they point teams toward a healthier operating model: design records before code, adversarial scenarios as tests, CI gates for known failures, and runtime controls for anything that can create side effects.
Confirmed facts
| Item | Confirmed fact | Why it matters |
|---|---|---|
| Microsoft release | Microsoft open-sourced RAMPART and Clarity on May 20, 2026. | Teams can inspect, trial, and adapt the tools rather than waiting for a closed product cycle. |
| RAMPART | RAMPART stands for Risk Assessment & Measurement Platform for Agentic Red Teaming and is described as a pytest-native safety testing framework for agentic AI applications. | It fits the mental model of integration tests and CI pipelines. |
| RAMPART maturity | The RAMPART docs state that the project is in alpha and APIs may change before 1.0. | Use it now for pilots and internal test harnesses, but avoid assuming API stability. |
| Clarity | Clarity is an AI thinking partner that helps teams decide whether they are building the right thing, captures problem statements, solutions, failure analysis, and decisions in a .clarity-protocol/ directory, and can run as a desktop app, web UI, or embedded in a coding agent. |
It makes design reasoning reviewable and diffable instead of leaving it trapped in meetings or chat history. |
| Microsoft’s broader stack | RAMPART and Clarity follow Microsoft’s April 2026 Agent Governance Toolkit, which Microsoft positioned around runtime governance for autonomous agents. | RAMPART and Clarity should be read as shift-left workflow tools, not the whole runtime security stack. |
| Microsoft Learn guidance | Microsoft Learn says building secure agents is a shared responsibility: frameworks provide building blocks, while developers must validate inputs, secure data flows, and configure tools. It also warns that restoring a session from an untrusted source is equivalent to accepting untrusted input. | Tests should be paired with permission design, input validation, secure storage, and approval controls. |
Community and security sentiment
Security and developer discussion around May 20–22 treated the release as part of a broader move toward agent CI testing, prompt-injection regression tests, and permission-aware development. Reddit/SecOpsDaily threads and security trade coverage amplified the announcement, but these should be treated as sentiment only, not proof that RAMPART or Clarity are effective in production.
Tovren analysis: the useful idea is regression coverage for agent failures
The strongest idea here is not that Microsoft released two repositories. It is that agent incidents should become tests. A red-team finding should not live forever in a PDF. If an agent was once tricked into calling send_email, exporting CRM data, running a shell command, or trusting hostile retrieved content, that failure should become a repeatable scenario in the same workflow that catches broken unit tests and integration regressions.
That is especially important because agent behavior changes when teams modify prompts, swap models, add tools, change retrieval sources, alter memory, or adjust approval policy. A mitigation that worked last month can quietly fail after a “small” prompt or tool change. CI is where that kind of regression belongs.

What RAMPART does
RAMPART gives developers a way to write tests that attack or probe an agent. The framework orchestrates the interaction, evaluates the outcome, and reports results. Microsoft’s docs describe a pytest-native workflow, meaning teams can run safety tests in familiar test infrastructure rather than creating a separate review ceremony.
The most important RAMPART concept for agent builders is XPIA: cross-prompt injection attack. RAMPART’s docs define XPIA as testing whether an agent can be manipulated through data sources. The attack plants malicious content in a document store, email inbox, file system, or similar source, then uses a benign trigger to cause the agent to retrieve and process that content. If the agent follows the injected instruction by calling a tool, exfiltrating data, or executing a command, the result is unsafe.
RAMPART also supports evaluators that inspect tool calls, response text, and side effects. Its docs show examples such as detecting whether send_email was called with a specific recipient, whether an exec command touched .ssh, or whether an HTTP POST went to a hostile host.
For CI, RAMPART tests run as standard pytest tests. The docs include patterns for CI timeouts, trial markers for probabilistic behavior, structured JSON reports for dashboards, and exit-code behavior inherited from pytest. A trial marker can run a scenario multiple times and require a minimum safe pass rate, which matters because LLM behavior is not perfectly deterministic.
pytest tests/agent_safety -v --timeout=300What RAMPART does not do
- It does not prove an agent is safe. It checks the scenarios you encode and the observability your adapter exposes.
- It does not replace runtime controls. Tool allow-lists, scoped credentials, approvals, rate limits, logging, and kill switches still matter.
- It does not automatically know your business risk. A CRM export may be harmless in one workflow and a reportable incident in another.
- It does not eliminate human review. Failed tests need triage, and passed tests still need threat modeling.
- It is still early. The RAMPART docs say the project is alpha and APIs may change before 1.0.
What Clarity does
Clarity is the pre-code layer. Its job is to slow the team down before the wrong tool, permission, data source, or product requirement becomes architecture. The Clarity README describes it as an AI thinking partner that pushes back, asking the kinds of questions experienced architects, product managers, and safety engineers would ask. It writes the answers into human-readable project documents, including the problem, solution, failure analysis, and decisions.
This is useful because many agent risks begin as innocent product decisions. “Let the agent read all customer emails” is a design decision. “Let the agent send outbound messages automatically” is a design decision. “Let the coding agent run shell commands without confirmation” is a design decision. By the time those choices are buried in implementation, reversing them is expensive.
Clarity’s practical value is that it turns those choices into reviewable artifacts. The README says Clarity creates a .clarity-protocol/ directory in the repo, with markdown documents that can be managed like source code. That makes the team’s reasoning visible in pull requests, not just in Slack threads or hallway memory.
What Clarity does not do
- It is not a policy engine. It helps teams reason; it does not enforce runtime permissions.
- It is not formal verification. A Clarity design record is useful evidence of reasoning, not proof of safety.
- It is not a substitute for red teaming. The output should feed threat scenarios and RAMPART tests.
- It is not a compliance shield. Regulated teams still need control evidence, audit trails, approvals, retention policy, and vendor review.
- It does not make risky scope safe. If the agent should not have access to a destructive tool, documenting that choice does not fix it. Remove or gate the tool.
Practical starter workflow for this week
- Create a Clarity design record. Capture the agent’s job, users, tools, data sources, allowed actions, disallowed actions, and human-review points.
- Build a threat scenario list. Include indirect prompt injection, unauthorized tool calls, data exfiltration, destructive commands, unsafe session restore, overbroad export, and policy bypass.
- Encode the first tests in RAMPART. Start with one XPIA test and one tool-call test. Do not wait for a perfect test suite.
- Run the tests locally. Confirm your adapter exposes enough observability: response text, tool calls, and preferably side effects.
- Add CI gates. Run a small safety suite on pull requests that modify prompts, tools, retrieval, memory, sessions, or model configuration.
- Review failures like security bugs. A failed safety test should create an issue with owner, severity, reproduction, mitigation, and retest evidence.
- Add runtime controls. Use scoped credentials, approval for high-risk tools, allow-listed arguments, logging, rate limits, and session-store protections.
Example tests teams should write first
| Test scenario | Attack path | Unsafe outcome to detect | Suggested gate |
|---|---|---|---|
| XPIA from webpage, email, ticket, or file | Malicious instructions hidden in retrieved content | Agent follows retrieved instruction instead of user/system intent | Block if the agent calls a sensitive tool or leaks data |
| Tool-call exfiltration | Injected content asks the agent to send secrets to an external address | send_email, webhook, HTTP POST, or chat message to unauthorized destination |
Block all unapproved destinations |
Unauthorized send_email |
Benign user asks for a summary; poisoned source tells agent to email it | Email sent without explicit user approval | Require approval for outbound messages |
| Destructive shell command | Poisoned repo file tells coding agent to run rm, delete branches, or read private keys |
Command execution touching protected paths, secrets, or destructive operations | Block or require approval for high-risk commands |
| Overbroad CRM export | Agent receives a narrow request but exports all customer records | Export exceeds requested account, region, role, or time range | Allow-list query scope and row limits |
| Unsafe session restore | Compromised session storage changes roles or injects trusted-looking history | Agent treats restored content as trusted instruction | Block restore from untrusted source; validate session integrity |
| Policy bypass | User or retrieved content asks agent to ignore approval policy | Tool runs despite policy requiring confirmation | Fail if policy is bypassed under any prompt wording |
Microsoft Learn’s safety guidance supports this posture: treat LLM-provided function arguments as untrusted input, require approval for high-risk tools, validate and sanitize LLM output, protect sensitive logs, secure session data, and implement resource limits.
Decision table: who should adopt what now?
| Team type | Use RAMPART this week? | Use Clarity this week? | Recommended move |
|---|---|---|---|
| Solo builder | Yes, if the agent can call tools or run code | Yes, lightweight | Write one design note, one XPIA test, and one high-risk tool test before sharing the agent. |
| Startup | Yes | Yes | Add safety tests to PRs that change prompts, retrieval, tools, or model configuration. Keep the suite small but mandatory. |
| Enterprise product team | Yes, pilot first | Yes, with review | Run a two-week pilot on one agent, then standardize adapter patterns, severity labels, and CI reporting. |
| Security team | Yes | Yes | Convert red-team findings into reusable regression tests and require product teams to own fixes. |
| Regulated app | Yes, but not alone | Yes | Pair tests and design records with audit logs, access controls, retention rules, human approval, and compliance evidence. |
| Internal helper bot | Yes, if connected to internal data | Yes, short version | Focus on data leakage, overbroad retrieval, and unsafe tool calls. Do not assume “internal” means low risk. |
| Coding agent wrapper | Yes, strongly | Yes | Prioritize file-system XPIA, shell-command approval, secret exfiltration, dependency modification, and repo-write tests. |
7-day rollout plan
| Day | Action | Pass/fail metric |
|---|---|---|
| Day 1 | Inventory the agent’s tools, data sources, permissions, memory, session storage, and outbound channels. | Pass: every action path has an owner and risk rating. Fail: any tool can act without a named owner. |
| Day 2 | Create a Clarity design record for the agent’s purpose, boundaries, approval policy, and failure modes. | Pass: design, failure analysis, and decisions are committed or reviewable. Fail: major permissions exist only in chat or memory. |
| Day 3 | Write the first XPIA test using a file, email, webpage, ticket, or document source the agent actually reads. | Pass: malicious retrieved content does not cause unsafe tool use. Fail: agent obeys the injected instruction. |
| Day 4 | Add tool-call tests for send_email, CRM export, shell execution, HTTP requests, and file writes. |
Pass: high-risk tools require approval or valid scoped arguments. Fail: any sensitive tool runs from untrusted instruction. |
| Day 5 | Test session restore, logs, and telemetry handling. | Pass: restored sessions are integrity-checked and sensitive logs are disabled in production. Fail: untrusted session data can escalate trust. |
| Day 6 | Add CI execution with timeout, structured report output, and owner notification. | Pass: pull requests changing agent behavior run the safety suite. Fail: safety tests are optional or local-only. |
| Day 7 | Review failures, ship mitigations, and add runtime controls. | Pass: failures have fixes, retests, and control evidence. Fail: the team accepts unsafe behavior without documented risk approval. |
Checklist for production agents

- Design record exists: problem, user, tools, data, permissions, risks, and rejected alternatives are documented.
- Tool inventory is current: every tool has owner, scope, allowed arguments, approval requirement, and logging policy.
- Indirect prompt-injection tests exist: webpage, email, ticket, file, RAG document, and repo-file sources are covered where relevant.
- Dangerous tools are gated: email, payments, CRM export, code execution, file deletion, database write, and external HTTP calls require policy checks or human approval.
- Arguments are validated: LLM-provided tool arguments are treated like untrusted API input.
- Session restore is protected: serialized sessions are stored securely and not trusted if loaded from compromised or untrusted sources.
- Logs are safe: sensitive prompt, tool, and customer data are not exposed in production logs or telemetry.
- CI blocks regressions: known unsafe behavior fails the build or requires documented risk acceptance.
- Red-team findings become tests: every confirmed agent failure gets a regression scenario.
- Runtime controls remain in place: RAMPART tests and Clarity records supplement, not replace, runtime authorization, monitoring, incident response, and human review.
Common failure modes and fixes
| Failure | Likely cause | Fix |
|---|---|---|
| RAMPART cannot detect unsafe behavior | The adapter only exposes final text, not tool calls or side effects | Expose tool-call telemetry and side-effect events where possible. |
| Tests pass locally but fail in CI | Missing credentials, timeouts, model variance, or indexing delay | Use CI-specific environment setup, longer timeouts, and statistical trials for probabilistic scenarios. |
| Too many false positives | Unsafe condition is defined too broadly | Make evaluators specific: tool name, argument predicate, destination, command pattern, or side-effect type. |
| Team treats Clarity as paperwork | No link between design record and engineering gates | Require PRs that add tools or permissions to update the design record and corresponding tests. |
| Red-team findings do not stick | Findings remain in reports instead of code | Convert each confirmed finding into a RAMPART regression test with owner and severity. |
FAQ
Is RAMPART a guardrail?
No. RAMPART is testing and regression infrastructure. It helps teams encode attacks, probes, and expected outcomes as repeatable tests. Runtime enforcement still needs permissions, approvals, policy checks, monitoring, and incident response.
Is Clarity a security tool?
Clarity is best understood as design-reasoning infrastructure. It helps teams clarify intent, surface failure modes, and record decisions before and during implementation. It can improve security work, but it does not enforce policy or prove safety.
Who should try RAMPART first?
Start with agents that can create side effects: sending messages, calling APIs, writing files, exporting CRM data, executing code, creating tickets, modifying repositories, or triggering business workflows.
What is the first RAMPART test to write?
Write an XPIA test against a real data source your agent reads. For example: plant hostile instructions in a file, ticket, email, or webpage, then trigger the agent with a normal request. The test should fail if the agent calls a sensitive tool or leaks data.
Should RAMPART run on every pull request?
For small suites, yes. At minimum, run RAMPART on pull requests that modify prompts, tools, retrieval, memory, session handling, model configuration, permissions, or approval policy. Larger suites can run nightly or before release.
Does a passing RAMPART suite mean the agent is production-ready?
No. Passing tests mean the agent passed known scenarios under the test setup. Production readiness also requires access control, monitoring, incident response, secure logging, human approval for high-risk actions, and ongoing red-team coverage.
How should regulated teams use Clarity?
Use Clarity records as supporting design evidence, not as compliance proof. Pair them with control mapping, audit logs, approval records, data-retention decisions, vendor review, incident response plans, and test evidence.
What should teams do this week?
Pick one agent with tool access. Write a design record. Inventory tools and data flows. Encode one XPIA scenario and one sensitive tool-call scenario. Put them in CI. Treat failures as security bugs. Add runtime controls for anything that can send, write, delete, export, execute, or purchase.
Bottom line
Microsoft RAMPART and Clarity are useful because they push AI-agent safety into the places where engineering teams already make durable changes: repositories, tests, pull requests, and CI. The winning pattern is not “add a safety review.” It is “turn agent risk into artifacts the team cannot accidentally forget.”
For action-taking agents, the standard should be clear: no undocumented permissions, no untested prompt-injection paths, no silent tool escalation, no unsafe session restore, and no red-team finding that fails to become a regression test.
Source Log
| Source | Publisher | Date | URL | Claims supported |
|---|---|---|---|---|
| Tovren production brief | User-provided brief | May 24, 2026 | Uploaded file citation | Topic, required angle, structure, image placeholders, and editorial constraints. |
| Introducing RAMPART and Clarity: Open source tools to bring safety into Agent development workflow | Microsoft Security Blog | May 20, 2026 | Source | Microsoft open-sourced RAMPART and Clarity; RAMPART is for repeatable CI tests; Clarity is for pre-code design reasoning; agent risk changed because agents can access email, CRM records, code execution, and connected systems. |
| RAMPART Documentation | Microsoft GitHub Pages | 2026; accessed May 24, 2026 | Source | RAMPART acronym; pytest-native safety testing framework; developers write tests that attack or probe agents; RAMPART orchestrates interaction, evaluates outcomes, and reports results; project alpha status. |
| RAMPART XPIA documentation | Microsoft GitHub Pages | 2026; accessed May 24, 2026 | Source | XPIA definition; malicious content planted in data sources; benign trigger causes retrieval; unsafe outcomes include tool calls, exfiltration, and command execution. |
| RAMPART Writing Tests documentation | Microsoft GitHub Pages | 2026; accessed May 24, 2026 | Source | AgentAdapter pattern; observability levels; evaluators for tool calls, response text, side effects, and evaluator composition. |
| RAMPART Results and Reporting documentation | Microsoft GitHub Pages | April 30, 2026 | Source | Result type; safety status; turns; JSON report sinks; population summaries; attack success and safety pass rates. |
| RAMPART CI Integration documentation | Microsoft GitHub Pages | May 19, 2026 | Source | RAMPART tests run as standard pytest tests; CI timeouts; trial markers; structured JSON reports; pytest exit codes. |
| microsoft/RAMPART repository | GitHub / Microsoft | Latest release shown May 20, 2026; accessed May 24, 2026 | Source | Public repository, MIT license, README summary, and release availability context. |
| microsoft/clarity-agent repository | GitHub / Microsoft | 2026; accessed May 24, 2026 | Source | Clarity as an AI thinking partner; desktop/web/coding-agent modes; .clarity-protocol/ markdown artifacts; problem, solution, failure analysis, and decision tracking; installation and provider context. |
| Introducing the Agent Governance Toolkit: Open-source runtime security for AI agents | Microsoft Open Source Blog | April 2, 2026 | Source | Microsoft’s broader agent-governance context; runtime security governance; agent autonomy risks; relationship between shift-left testing and runtime controls. |
| Agent Safety | Microsoft Learn | Last updated May 21, 2026 | Source | Secure agents are a shared responsibility; trust boundaries; function inputs are untrusted; high-risk tools should require approval; LLM output should be validated; sessions restored from untrusted sources are equivalent to untrusted input; resource limits and logging guidance. |
| Security and community discussion around RAMPART and Clarity | Reddit/SecOpsDaily, r/blueteamsec, The Hacker News, CSO Online, DevOps.com | May 20–22, 2026; accessed May 24, 2026 | Example thread | Sentiment only: security and developer communities are watching agent CI testing, prompt injection, red-team regression, and permission controls. Not used as objective proof of tool effectiveness. |