
Short answer: SkillRet shows that AI agents can know a skill exists and still fail to retrieve it at the right moment. If you build agents, test skill retrieval separately from model reasoning before deploying reusable tool libraries.

Updated May 12, 2026, Asia/Seoul. The newest AI paper worth paying attention to this week is not another model leaderboard. It is SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents, a May 7, 2026 arXiv paper by Hongcheol Cho, Ryangkyung Kang, and Youngeun Kim.
The paper targets a very practical problem: as AI agents accumulate reusable skills, prompts, scripts, workflows, and policies, the agent has to choose the right skill before it can do useful work. A bigger context window does not solve that by itself. If the wrong skill is retrieved, the agent may fail before planning or execution even begins.
The short version
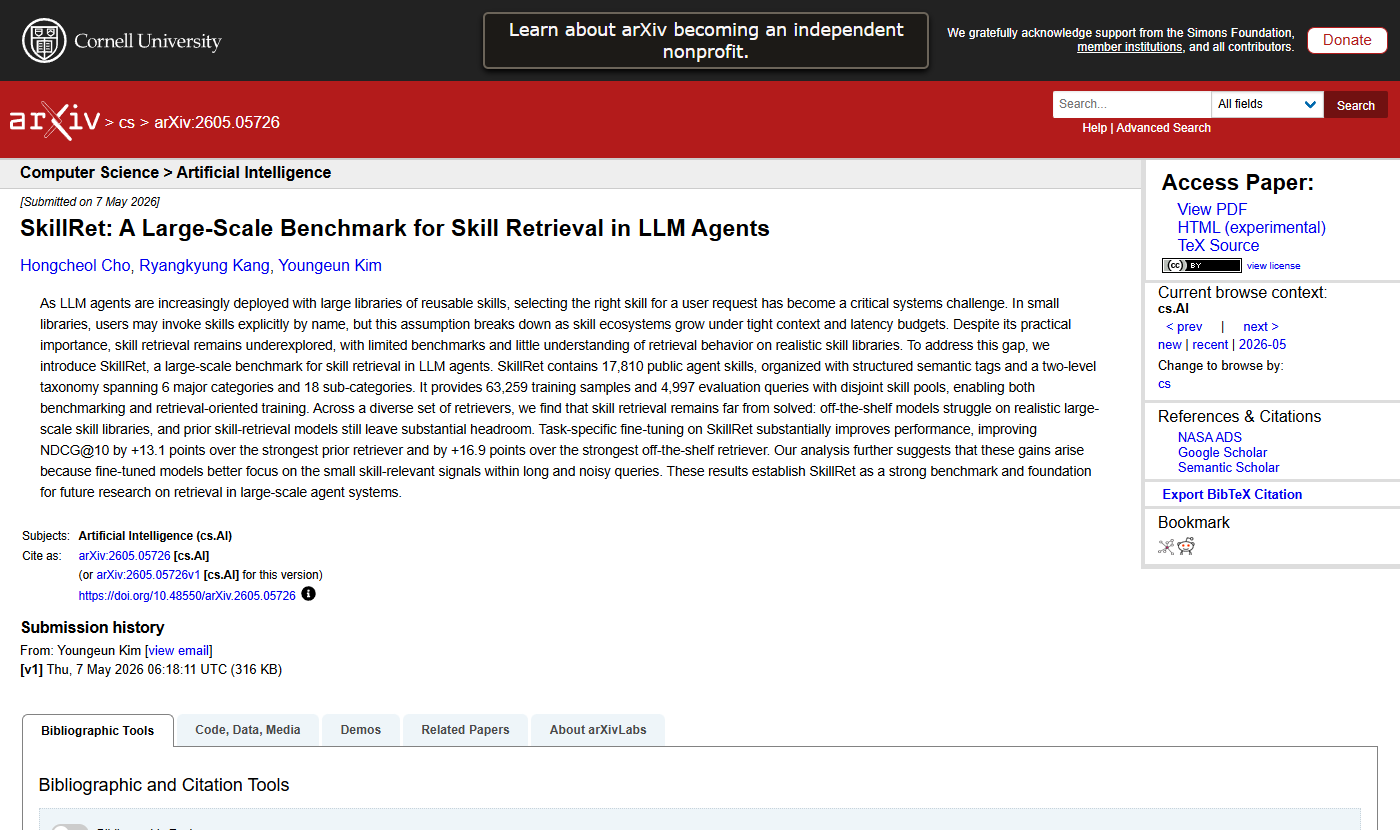
SkillRet introduces a retrieval benchmark built from 17,810 public agent skills, with 63,259 training samples and 4,997 evaluation queries. The authors report that task-specific fine-tuning improves NDCG@10 by +13.1 points over the strongest prior skill retriever and +16.9 points over the strongest off-the-shelf retriever.
For builders, the takeaway is simple: if your agent product has more than a small handful of tools or skills, you should evaluate skill retrieval as its own system component. Do not only measure whether the final agent answer looks good. Measure whether the right procedural knowledge was found in the first place.
What SkillRet is actually testing
The benchmark treats each skill as a document that can include a name, description, and full Markdown body. Queries are realistic user requests that may require one, two, or three skills. The retriever must rank the relevant skills from a large library, and the evaluation reports ranking quality with metrics such as NDCG, Recall, and Completeness.
This matters because skill retrieval is different from normal web search or FAQ retrieval. The relevant signal may be a small actionable capability hidden inside a long user request. The skill document may also be long, procedural, and noisy. Matching the user to the right reusable workflow is closer to routing operational capability than matching semantic topic similarity.
Key numbers from the paper
- Raw skill crawl: 22,795 community-contributed skills.
- Final curated skill set: 17,810 skills after filtering, licensing checks, and deduplication.
- Training split: 10,123 skills and 63,259 queries.
- Evaluation split: 6,660 held-out skills and 4,997 queries, with no skill overlap.
- Best off-the-shelf NDCG@10: 66.55 in the paper’s embedding retrieval table.
- SkillRet-Embedding-8B NDCG@10: 83.45 before reranking.
- Best reported reranked NDCG@10: 84.22 with SkillRet-Embedding-8B plus SkillRet-Reranker-0.6B.
Why this matters for agent teams
Many agent systems still treat skill selection as a prompt-engineering detail: list some tools, add descriptions, and hope the model chooses correctly. SkillRet argues that this layer deserves the same seriousness as vector search, reranking, and regression testing in a RAG system.
If your product has a growing skill library, retrieval quality can become the hidden failure mode. The user may ask for a spreadsheet audit, a security triage, a slide rewrite, or a data-cleaning workflow. The agent might be capable of doing the work, but only if it retrieves the right procedural module at the right time.
A practical architecture pattern
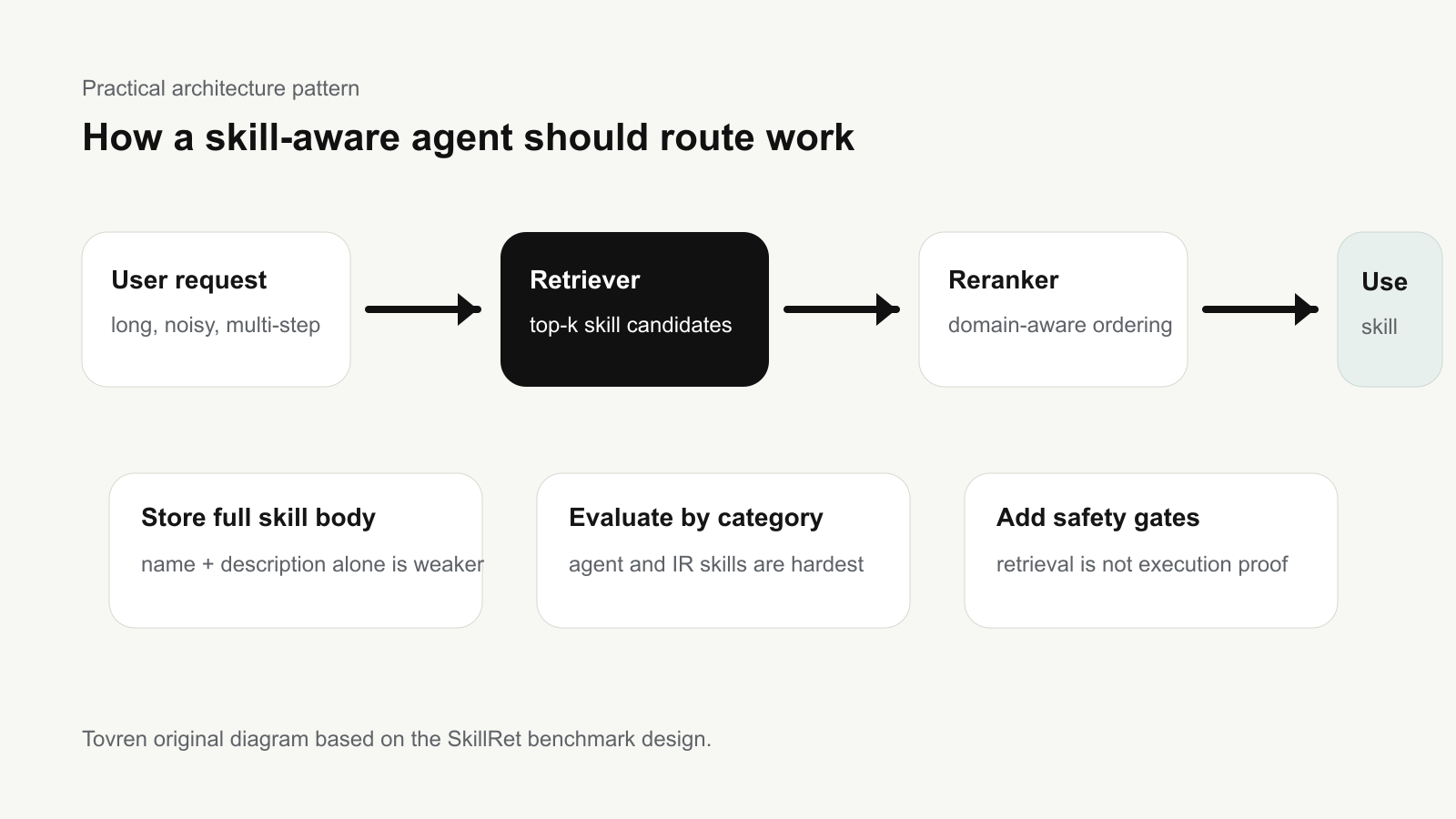
A useful production pattern is to separate the system into four layers:
- Skill inventory: keep a structured registry with name, description, full body, owner, version, license, dependencies, and risk tier.
- First-stage retrieval: retrieve a broader candidate set quickly using an embedding model trained or adapted for skill documents.
- Reranking: rerank candidates with a domain-aware reranker, but test carefully because the paper reports that general-purpose rerankers can reduce performance when they override a specialized retriever.
- Execution gate: before running a skill, check permissions, freshness, user intent, sandboxing needs, and whether human approval is required.
What to change in your agent stack
1. Stop indexing only skill titles. The paper’s appendix reports that encoding the full skill body outperforms using only the name and description. For a real agent library, this means your index should include the procedural details that make a skill useful, not just a short marketplace blurb.
2. Track retrieval metrics before end-to-end success. Add tests such as Recall@10, NDCG@10, and “all required skills found” for multi-skill queries. If the retriever fails, the agent’s final answer is not a fair measure of the planner or executor.
3. Evaluate categories separately. SkillRet reports that Information Retrieval and AI Agents are among the harder major categories. A single aggregate score can hide weak spots. Your internal benchmark should break results down by skill family: coding, research, data, automation, compliance, content, security, and so on.
4. Be careful with generic rerankers. The paper finds that off-the-shelf rerankers can reduce NDCG@10 for SkillRet embedding models. That does not mean reranking is bad. It means rerankers need to understand the domain and the structure of skill-selection decisions.
5. Do not confuse retrieval with safe execution. A model can retrieve the correct skill and still apply it incorrectly. SkillRet is a retrieval benchmark, not proof that an deployed agent is safe, secure, or reliable. Production systems still need provenance checks, sandboxing, permission controls, logging, and human oversight for high-impact actions.
Limitations to keep in mind
The authors are clear that SkillRet does not measure full downstream agent success. It isolates retrieval quality. The queries are also synthetically generated rather than collected from live agent traffic, which means real users may be shorter, more ambiguous, more conversational, or more dependent on private context than the benchmark examples.
That limitation does not weaken the paper’s practical value. It tells teams how to use the benchmark correctly: as a diagnostic tool for the retrieval layer, not as a certification that an agent product will behave well in production.
Who should read the paper
- Agent framework builders who maintain tool or skill registries.
- Enterprise AI teams building internal workflow libraries.
- RAG engineers who need to route long requests to procedural assets, not just documents.
- AI safety and platform teams that need evidence of which capability modules were selected before execution.
- Model evaluators designing benchmarks for agent systems beyond final-answer accuracy.
Bottom line
SkillRet is important because it names a real bottleneck in agent systems. The future of agents is not just larger models, larger context windows, or longer tool lists. It is reliable selection of the right reusable capability at the right moment.
If you are building agents today, the immediate action is to audit your skill library. Index full skill bodies, build retrieval tests, measure multi-skill completion, and keep execution guardrails separate from retrieval success. SkillRet gives teams a concrete way to start measuring that layer.
Source note
This article is based on the arXiv paper, released dataset, code repository, and model cards available at publication time. External facts and benchmark numbers should be checked against the original sources before using them for model-selection or production decisions.
FAQ
What is SkillRet?
SkillRet is a benchmark focused on whether AI agents can retrieve and use the right stored skill at the right time.
Why does skill retrieval matter?
Agents with many reusable skills can still fail if they choose the wrong skill, ignore a relevant skill, or use it in the wrong context.
How should builders use SkillRet?
Use it as a reminder to test retrieval, routing, and skill-library design separately from raw model reasoning.