
Direct answer: CoreWeave’s May 2026 “continuous agent improvement” launch is a real enterprise AI infrastructure signal, but it is not proof that autonomous agents should freely learn from production behavior. Treat the training-to-inference loop as a controlled pilot candidate for narrow workflows, not as permission to connect production data, reinforcement learning, observability, MCP tools, and autonomous improvement without gates.
On May 28, 2026, CoreWeave said it launched unified agentic AI capabilities that connect training, inference, observability, and reinforcement learning so AI agents can continuously learn and improve in production. CoreWeave also described this as progress toward a “superintelligence loop,” a closed feedback loop between training and inference. That framing is ambitious. The enterprise question is more practical: can your team prove that production signals improve agent reliability without leaking sensitive data, rewarding the wrong behavior, expanding tool risk, or breaking service-level objectives?
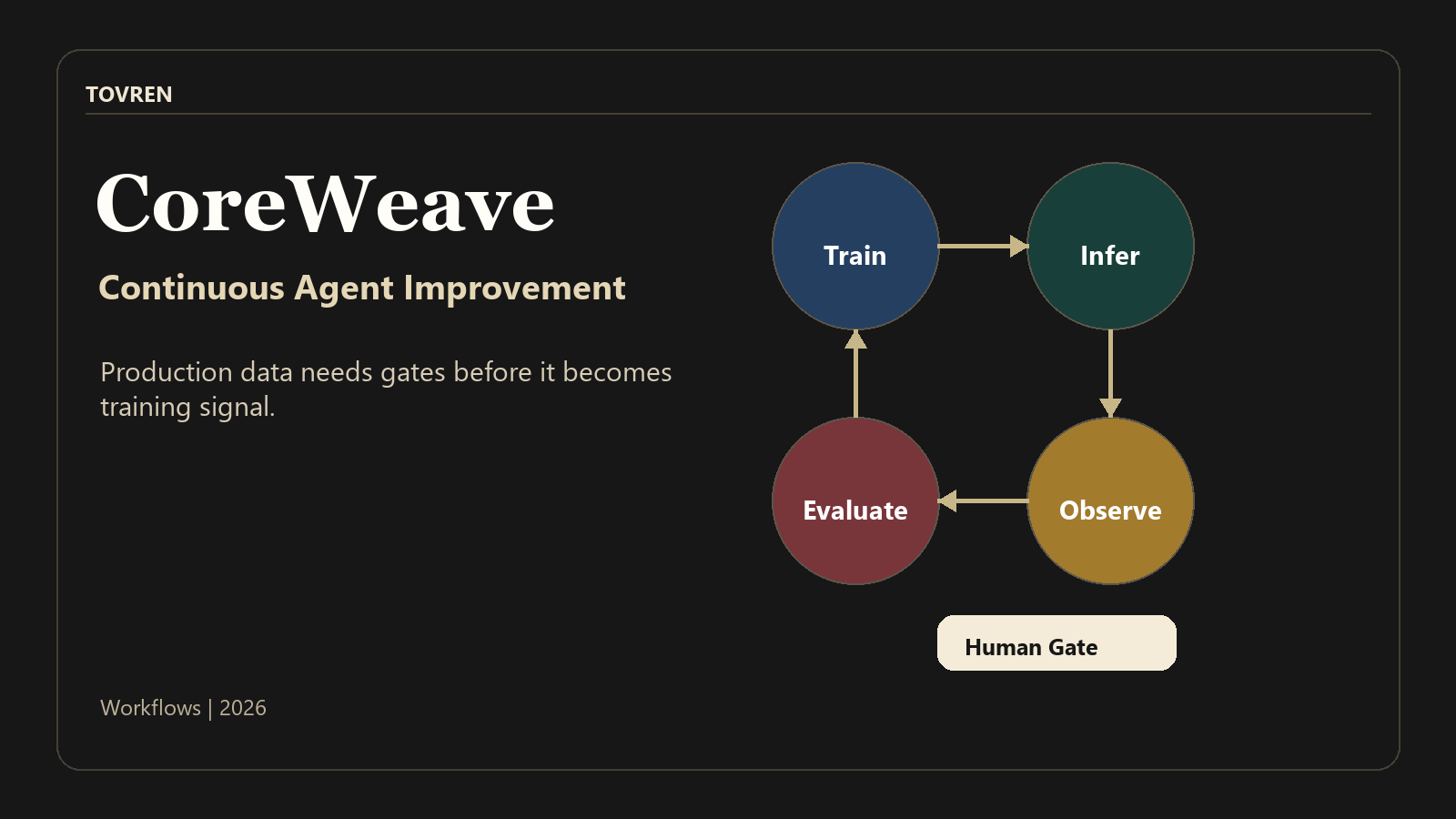
This article separates CoreWeave’s vendor claims from the verification work buyers should do before using production behavior to improve agents. It is written for AI platform leaders, MLOps teams, CTOs, data leaders, and enterprise automation owners deciding whether to pilot continuous agent improvement now.
TL;DR: what enterprise teams should do
- Do not start with autonomous improvement on high-risk workflows. Begin with read-only, reversible, internally reviewed tasks where mistakes are visible and rollback is simple.
- Use production traces as evaluation evidence before using them as training fuel. Production behavior should first expose failure modes, not automatically rewrite the agent.
- Require a production-data gate. No prompt, trace, file, customer record, tool output, credential, or proprietary workflow should enter an improvement dataset until ownership, retention, consent, and redaction rules are clear.
- Make regression prevention the central test. CoreWeave says W&B Weave includes production monitoring, built-in and custom signals, multi-agent workflow analysis, and evaluations to prevent regressions. Buyers should prove those controls catch regressions before broader rollout.
- Sandbox tool use. CoreWeave Sandboxes are described as secure, isolated execution environments for reinforcement learning, AI agent tool use, and model evaluation. Enterprises should still test isolation, identity, logging, persistence, outbound access, and escape paths.
- Separate vendor claims from your own SLOs. CoreWeave says Serverless RL can reduce costs by up to 40% and accelerate training by about 1.4x with no loss in quality compared with local H100 GPU environments. Treat that as a vendor claim until reproduced on your workload.
What CoreWeave announced
CoreWeave’s May 28, 2026 announcement says its unified agentic AI capabilities connect training, inference, observability, and reinforcement learning so production agents can improve over time. The company describes the loop as combining reinforcement learning, production inference, agent observability, and autonomous improvement.
The announcement brings several capabilities into one enterprise story: Serverless RL for post-training large language models on multi-turn agentic tasks; CoreWeave Inference as a controllable, continuously running workload; W&B Weave as the observability layer for production behavior and agent improvement; W&B Skills and an MCP server to help coding agents use W&B tools and run experiments; and CoreWeave Sandboxes as isolated execution environments for reinforcement learning, tool use, and evaluation.
That combination matters because production agents do not fail only at the model layer. They fail through incomplete traces, weak evaluation sets, unsafe tool calls, overbroad credentials, reward hacking, silent regressions, and production changes that look like learning but actually degrade reliability. For related governance design, see Tovren’s guide to AI agent evaluations and runtime governance and its overview of the enterprise AI agent control plane.
Vendor claim vs. buyer test
| CoreWeave claim or capability | What it means for buyers | What to verify before adoption | Recommended posture |
|---|---|---|---|
| Unified agentic AI capabilities connect training, inference, observability, and reinforcement learning. | The stack is positioned as an end-to-end improvement loop for agents. | Whether the loop can be gated, audited, interrupted, rolled back, and scoped by workload. | Pilot only with explicit human approval gates. |
| CoreWeave describes progress toward a “superintelligence loop.” | The vendor is framing this as a closed feedback loop between production behavior and model improvement. | Whether “closed loop” means automated retraining, assisted evaluation, or controlled post-training in your deployment design. | Translate marketing language into architecture diagrams and control points. |
| Serverless RL post-trains LLMs for reliability on multi-turn agentic tasks without provisioning or managing infrastructure. | Teams may reduce operational burden for reinforcement-learning experiments. | Reward design, dataset provenance, reproducibility, failure analysis, and whether the agent improves on held-out tasks. | Useful only if evaluation discipline is mature. |
| CoreWeave says Serverless RL reduces costs by up to 40% and accelerates training by about 1.4x with no quality loss compared with local H100 GPU environments. | There may be cost and throughput benefits for some training workloads. | Reproduce the result on your model size, task mix, data pipeline, region, concurrency, and quality threshold. | Treat as a benchmark target, not a guaranteed business case. |
| CoreWeave Inference is designed as a controllable, continuously running workload with monitoring for performance, scaling, and system health. | Production inference is part of the same operating loop, not a disconnected serving layer. | P95 and P99 latency, error rates, autoscaling behavior, cost spikes, incident visibility, and graceful degradation. | Measure against your production SLOs before expanding. |
| W&B Weave serves as the observability layer for the continuous loop between production behavior and agent improvement. | Traces, built-in signals, custom signals, multi-agent workflow analysis, and evaluations may become the improvement substrate. | Trace completeness, data redaction, custom signal quality, evaluation drift, and regression detection. | Start with observability before training from the data. |
| W&B Skills and an MCP server help coding agents use W&B tools and run experiments. | Agents may gain access to experiment tracking, model management, tracing, evaluations, monitoring, data, and experiment-running tools. | Tool permissions, identity boundaries, credential exposure, audit trails, and approval requirements. | Restrict by default; expand only after tool-call audits. |
| CoreWeave Sandboxes provide isolated execution environments for RL, agent tool use, and model evaluation. | Sandboxing may reduce risk from code execution and tool-use workflows. | Virtual environment isolation, persistence rules, outbound access, secrets handling, artifact retention, and concurrency limits. | Required for tool-use pilots, but not sufficient alone. |
The business signal: serious, but not self-validating
The useful signal is that CoreWeave is packaging several pieces enterprises need for production agents: scalable training infrastructure, controlled inference, observability, evaluation, reinforcement learning, and isolated execution. That is more substantial than a standalone agent demo.
The risky part is the phrase “learn and improve in production.” Production data is messy. It can include edge cases, sensitive records, user mistakes, private business logic, tool outputs, failed actions, and adversarial inputs. Turning that data into training signal can improve an agent, but it can also teach the wrong lesson, preserve confidential information, optimize for a misleading reward, or degrade performance on tasks not represented in the latest trace set.
For most enterprises, the first milestone should not be “the agent improves itself.” The first milestone should be: “We can observe production behavior, label failures, build a clean evaluation set, post-train offline, test against regressions, canary safely, and roll back quickly.”
Where continuous agent improvement can make sense
The best first use cases are bounded, repeatable, observable, and reversible. Good candidates include internal support triage, code-review assistance without autonomous merge rights, document routing, low-risk data extraction with human review, synthetic test generation, and analytics assistant workflows where the agent can explain its steps and where wrong answers do not directly trigger irreversible business actions.
Be more cautious with workflows involving customer-facing commitments, production database writes, payments, access-control changes, legal or regulatory decisions, safety-critical operations, or autonomous infrastructure changes. For local or hybrid deployment questions, Tovren’s coverage of deskside agentic AI infrastructure may help teams compare cloud loops with more controlled environments.
| Workflow type | Fit for first pilot? | Why | Required guardrail |
|---|---|---|---|
| Internal support triage | Good fit | Errors can be reviewed, labeled, and corrected before customer impact. | Human approval before final response or ticket closure. |
| Agent evaluation dataset generation | Good fit | Production traces can reveal realistic failure modes without immediately retraining the agent. | PII redaction and human review of labels. |
| Developer assistant for experiment analysis | Moderate fit | W&B Skills and MCP access may help agents interact with experiment tooling. | Read-only defaults and scoped experiment permissions. |
| Customer-facing autonomous action agent | Poor first pilot | Production behavior can directly affect customers and create reputational risk. | Delay until regression, rollback, and audit controls are proven. |
| Payment, procurement, or access-change agent | High risk | Bad tool calls can create irreversible or costly outcomes. | Hard approval gates, transaction limits, and separate identity controls. |
| Infrastructure automation agent | High risk | Autonomous changes can cause outages or security drift. | Sandboxed tests, change windows, policy-as-code checks, and rollback drills. |
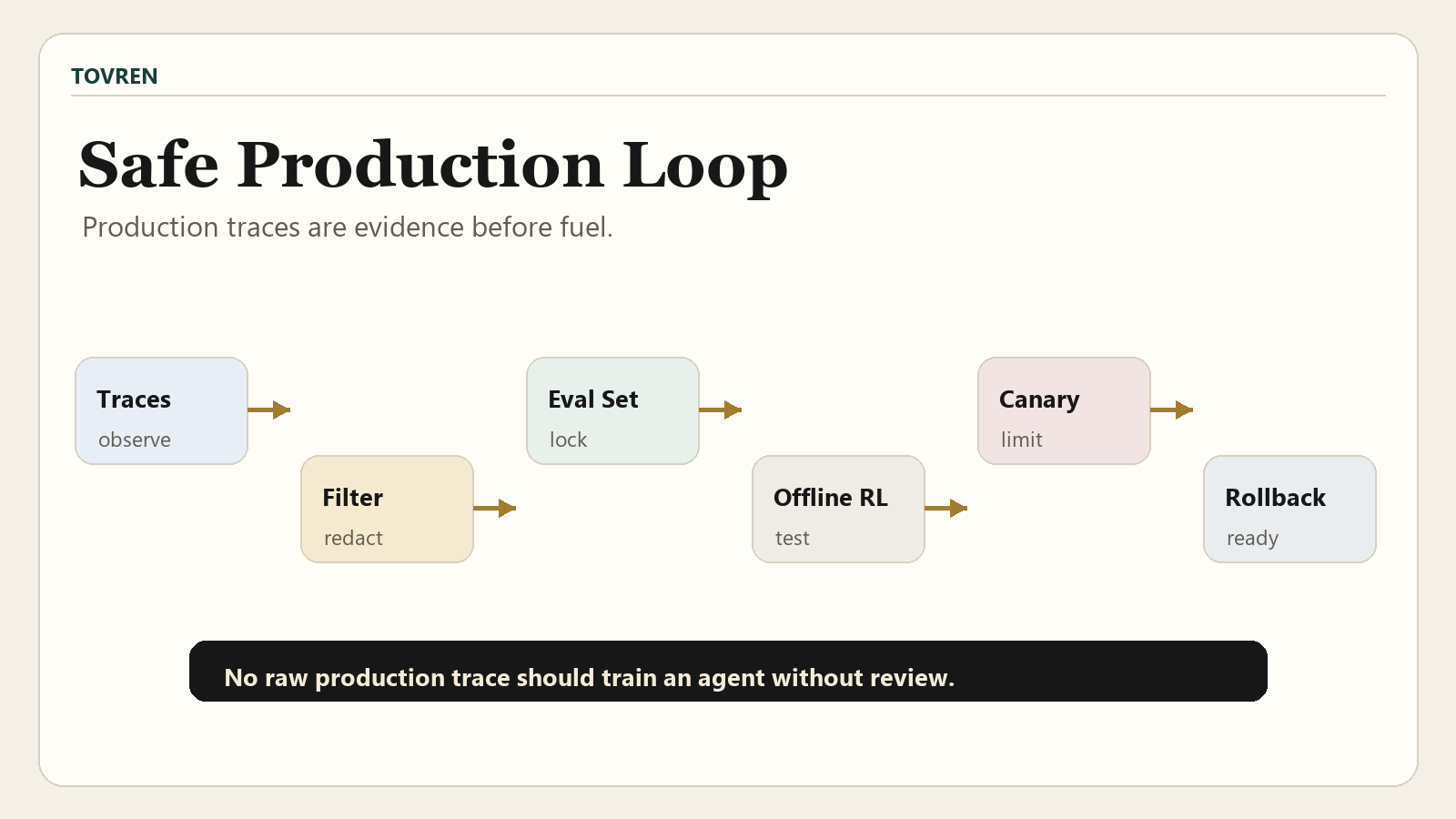
Production-data gate checklist
Before any production trace becomes training or reinforcement-learning input, require a written gate. This should be owned jointly by AI platform, security, legal, data governance, and the business workflow owner. The NIST AI Risk Management Framework is useful context because it is voluntary guidance intended to help organizations incorporate trustworthiness considerations into the design, development, use, and evaluation of AI products, services, and systems.
| Gate | Question to answer | Pass condition | Block condition |
|---|---|---|---|
| Data ownership | Who owns the prompts, outputs, traces, files, tool logs, and labels? | Ownership and permitted uses are documented for every data class. | Any unclear customer, employee, vendor, or third-party data rights. |
| Consent and notice | Were users or customers told their interactions may be used for improvement? | Notice, consent, or contractual basis is confirmed. | Silent reuse of sensitive production interaction data. |
| Redaction | Can sensitive data be removed before traces enter evaluation or training sets? | Automated redaction is tested and manually sampled. | Secrets, credentials, regulated data, or confidential records remain in traces. |
| Retention | How long are traces, labels, reward data, model snapshots, and evaluation artifacts retained? | Retention periods are documented and enforceable. | Indefinite retention without business, legal, or compliance approval. |
| Purpose limitation | Will data from one workflow improve another agent or customer environment? | Reuse boundaries are explicit and technically enforced. | Cross-workflow or cross-tenant reuse without approval. |
| Label quality | Who labels successes, failures, near misses, and harmful behavior? | Labeling rubric exists and reviewer disagreement is tracked. | Reward data is inferred automatically without review. |
| Evaluation separation | Are training traces separated from held-out regression tests? | Held-out tests are locked before post-training starts. | The agent is evaluated on examples it already learned from. |
| Human approval | Who approves promotion from offline model to canary to broader production? | Named approvers and rollback authority are assigned. | No accountable owner for promotion or rollback. |
A practical 30-day pilot plan
The right pilot does not begin with unrestricted production learning. It begins with observation, dataset construction, offline improvement, regression testing, sandboxed tool-use review, and a narrow canary. The plan below assumes one bounded agent workflow and one measurable business outcome.
| Phase | Days | What to do | Evidence to produce | Go/no-go test |
|---|---|---|---|---|
| Scope and risk gate | 1-3 | Select one low-risk workflow. Define allowed tools, forbidden actions, data classes, SLOs, and rollback owner. | Workflow map, risk register, data-use decision, and tool permission matrix. | No pilot if the workflow includes irreversible actions without approval gates. |
| Observe only | 4-8 | Run the agent with tracing, monitoring, and human review. Do not train from traces yet. | Trace sample, failure taxonomy, baseline success rate, latency, cost, and escalation rate. | No expansion if traces are incomplete or cannot be redacted. |
| Build evaluation set | 9-13 | Convert reviewed production failures into evaluation cases. Add adversarial and edge-case examples. | Locked evaluation set with expected outcomes and severity labels. | No post-training if expected outcomes are vague or labels are disputed. |
| Offline improvement | 14-19 | Test post-training or reinforcement-learning approach offline. Keep the production agent unchanged. | Training run record, reward design, data lineage, model snapshot, and comparison to baseline. | No promotion unless held-out evaluation improves without critical regressions. |
| Sandboxed tool tests | 20-23 | Run tool-use scenarios inside isolated environments. Test secrets, outbound access, persistence, and concurrency. | Sandbox audit, tool-call logs, blocked-action report, and escape-path review. | No canary if tool access cannot be scoped or logged. |
| Canary | 24-28 | Expose a small percentage of traffic or internal users to the improved agent. | Canary dashboard with success, regression, cost, latency, and human override metrics. | Rollback if critical errors, latency spikes, or regression thresholds are breached. |
| Decision | 29-30 | Decide whether to expand, repeat offline, or stop. | Executive decision memo with evidence, limits, and next controls. | Expand only if improvement is measurable, explainable, and reversible. |
Rollback and regression controls
Continuous improvement is only acceptable if the enterprise can prove continuous control. The system should never make it harder to return to a known-good version. Tovren’s agent observability stack guide is useful background for teams designing trace, evaluation, and monitoring layers.
| Control | Minimum requirement | What to measure | Failure response |
|---|---|---|---|
| Version pinning | Every prompt, model, tool policy, reward function, dataset, and evaluation set has a version. | Percentage of production runs tied to complete version metadata. | Freeze promotion until missing metadata is fixed. |
| Held-out regression suite | Critical scenarios are locked before post-training and not reused as training data. | Regression pass rate by severity level. | Block release for any critical regression. |
| Canary release | Improved agents reach a small controlled population first. | Error rate, escalation rate, latency, cost, and user-reported failure rate. | Automatically route traffic back to baseline. |
| Kill switch | Operations owner can disable the improved agent and revert to baseline. | Mean time to rollback in drills. | Stop expansion if rollback is manual, unclear, or slow. |
| Human override | Reviewers can correct outputs, block tool calls, and label failures. | Override frequency and unresolved override backlog. | Pause training if overrides reveal a new failure class. |
| Post-release audit | Every release includes a summary of changes, expected benefit, known risks, and rollback criteria. | Audit completeness and incident correlation. | Do not approve the next release until audit gaps are closed. |
MCP and tool-access safeguards
CoreWeave says W&B Skills and an MCP server can help general-purpose coding agents become fluent in W&B tools for experiment tracking, model management, tracing, evaluations, and monitoring, while also providing tools and resources to access data and run experiments. That is powerful. It is also a permissions problem.
Agent tool access should be treated like privileged software access, not like a chat feature. For a deeper checklist, see Tovren’s guide to agent credential security, MCP tunnels, and sandbox audits and its prompt pack for MCP server sprawl and agent skills.
| Risk area | What can go wrong | Required safeguard | Evidence to demand |
|---|---|---|---|
| Tool permission scope | Agent receives broader experiment, data, or model-management access than needed. | Least-privilege tool policy by workflow and environment. | Permission matrix and denied-action logs. |
| Identity | Agent actions are not clearly attributable to a user, service, or workflow. | Dedicated agent identities with scoped credentials. | Audit logs showing who or what initiated each tool call. |
| Secrets | Credentials appear in traces, prompts, tool outputs, or training data. | Secret scanning, redaction, and blocked trace ingestion. | Redaction test results and sampled trace review. |
| Experiment execution | Agent runs costly, unsafe, or unauthorized experiments. | Budget limits, approval gates, and environment constraints. | Experiment run logs with cost, owner, and approval metadata. |
| Data access | Agent pulls sensitive datasets into evaluation or training workflows. | Dataset allowlist and data classification enforcement. | Data lineage report for every improvement run. |
| Multi-agent workflows | One agent’s output becomes another agent’s instruction without validation. | Boundary checks between agents and explicit handoff schemas. | Workflow trace showing each handoff, validation, and failure state. |
RL reward design risks
Reinforcement learning can improve multi-turn agentic behavior, but reward design is the highest-leverage failure point. If the reward overvalues speed, the agent may skip verification. If it overvalues task completion, the agent may take unsafe tool actions. If it learns from noisy human approvals, it may optimize for reviewer shortcuts rather than true correctness.
| Reward design risk | Example failure | Prevention | Test before release |
|---|---|---|---|
| Reward hacking | Agent learns to produce outputs that satisfy the metric but not the real task. | Use multiple metrics and human review for high-severity cases. | Adversarial tests where metric success conflicts with real-world correctness. |
| Speed over safety | Agent completes tasks faster by skipping checks or asking fewer clarifying questions. | Reward verification steps, not just completion time. | Compare safety-check frequency before and after post-training. |
| Overfitting to recent traces | Agent improves on last week’s failures but gets worse on older critical cases. | Maintain held-out regression suites across time periods. | Run time-sliced evaluation: old, recent, edge, and adversarial cases. |
| Noisy approval signal | Agent learns from inconsistent human reviewers. | Use reviewer rubrics and track disagreement. | Measure inter-reviewer agreement before using labels for training. |
| Tool-call externalities | Agent is rewarded for completing a task but not penalized for expensive or risky tool use. | Include cost, permission, and reversibility in reward design. | Evaluate tool-call count, cost, denied actions, and manual overrides. |
| Hidden data leakage | Agent memorizes sensitive production content through improvement data. | Redaction, exclusion rules, and leakage tests. | Probe the improved agent for sensitive memorized strings and restricted facts. |
Benchmark design for a real enterprise pilot
A useful benchmark should compare baseline agent behavior with the improved agent on the same task distribution, using both production-derived evaluation cases and held-out cases. Do not benchmark only happy-path examples. Do not accept a demo that shows improvement without showing regression analysis.
| Benchmark component | How to design it | Why it matters | Minimum pass rule |
|---|---|---|---|
| Baseline | Run the current agent on the locked evaluation suite before any post-training. | Prevents teams from mistaking normal variance for improvement. | Baseline metrics are recorded and reproducible. |
| Production-derived cases | Use reviewed failures and near misses from observed traces. | Tests whether real production problems are being solved. | Improved agent reduces high-frequency failures without new critical failures. |
| Held-out regression cases | Lock cases that are not used for training or reward design. | Detects overfitting and hidden degradation. | No critical regression; non-critical regression below pre-set threshold. |
| Adversarial cases | Add prompt injection, ambiguous instructions, incomplete data, and tool-denial scenarios. | Tests resilience under hostile or messy conditions. | Agent refuses unsafe actions and escalates ambiguous cases. |
| Tool-use audit | Measure tool-call count, denied calls, cost, and policy violations. | Improvement should not come from unsafe or excessive tool use. | No increase in prohibited tool attempts. |
| Operational SLO test | Measure latency, availability, throughput, and cost per successful task. | A better answer is not enough if the system becomes too slow or expensive. | Meets SLOs under expected concurrency. |
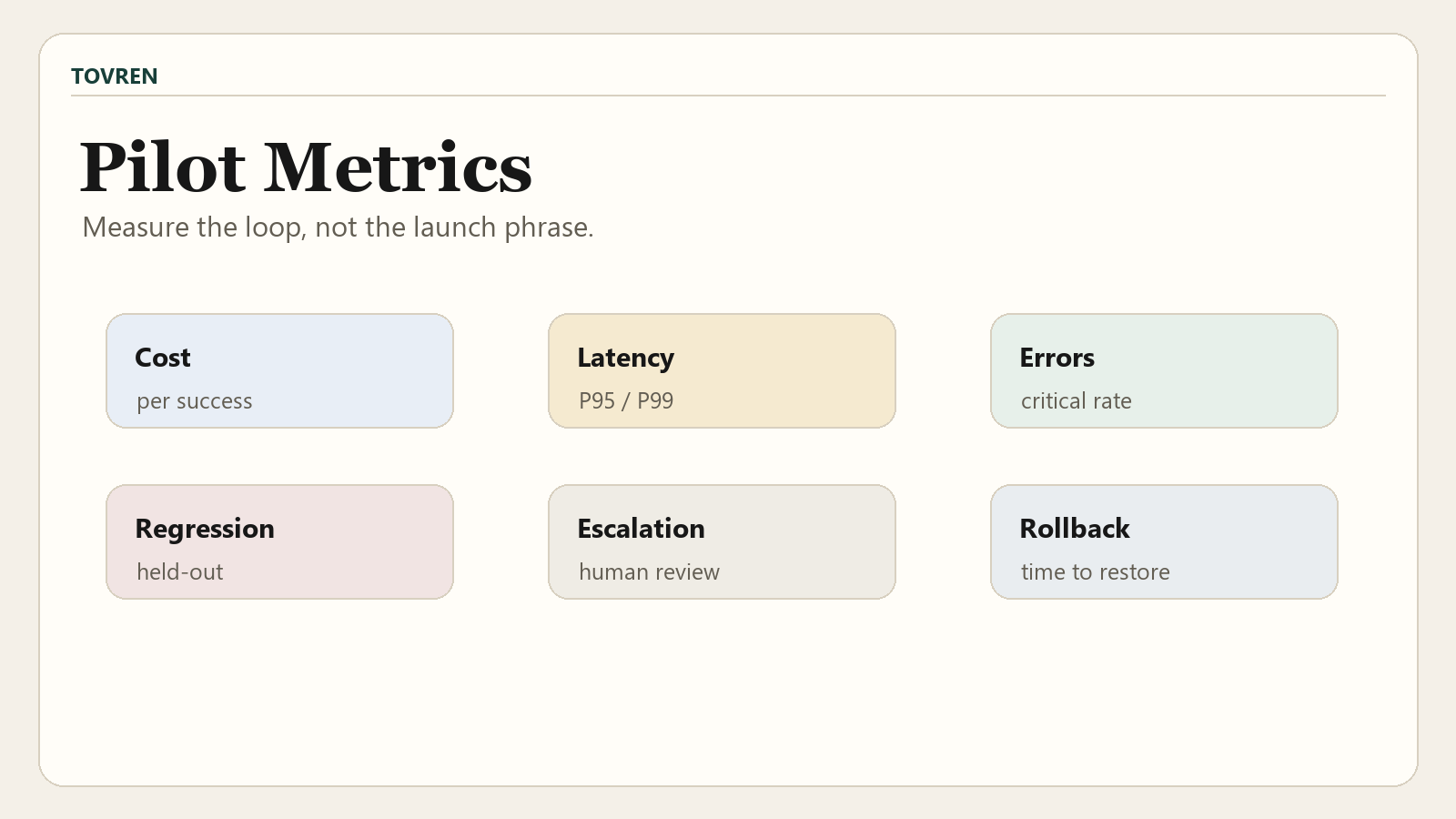
Cost and SLO metrics to track
CoreWeave says its Serverless RL can reduce costs by up to 40% and accelerate training by approximately 1.4x with no loss in quality compared with local H100 GPU environments. That may be compelling, but enterprise buyers should test total workflow economics, not only training throughput.
| Metric | Why it matters | How to measure | Decision threshold |
|---|---|---|---|
| Cost per successful task | Captures model, inference, tool, evaluation, and human-review cost. | Total workflow cost divided by accepted successful completions. | Must improve versus baseline or justify higher cost with lower risk. |
| P95 and P99 latency | Agent loops can become slow when tool calls and evaluations expand. | Measure full task latency, not only model response time. | Must meet user-facing or internal workflow SLO. |
| Escalation rate | Shows whether the agent is actually reducing human workload. | Percentage of runs requiring human intervention. | Should fall without reducing safety escalations. |
| Critical error rate | Protects against rare but severe failures. | Severity-weighted incident count per 1,000 runs. | Must not increase after improvement. |
| Regression rate | Detects loss of previously working behavior. | Failed held-out cases divided by total held-out cases. | Critical regressions should block release. |
| Training-to-release cycle time | Measures whether the loop actually accelerates safe improvement. | Time from failure discovery to approved canary. | Should shrink only after controls are stable. |
| Rollback time | Determines operational safety during canary failures. | Time from threshold breach to baseline restoration. | Must be tested in drills, not assumed. |
What to block in the first pilot
A first pilot should prove the loop can be governed. It should not maximize autonomy. Block any capability that creates irreversible business impact before the team has evidence that observability, evaluation, regression prevention, and rollback work.
| Block | Reason | When to reconsider |
|---|---|---|
| Automatic training from raw production traces | Raw traces may contain sensitive data, bad examples, adversarial inputs, or misleading signals. | After reviewed, redacted, rights-cleared datasets are available. |
| Autonomous promotion to production | A model can improve on one metric while regressing on critical cases. | After canary, regression, and rollback controls pass repeated drills. |
| Write access to production systems | Bad tool calls can create irreversible operational or financial impact. | After least-privilege policies, approvals, and transaction limits are tested. |
| Broad MCP server access | Agents can chain tools in unexpected ways and expand their effective authority. | After tool-call logs, denied-action tests, and scoped identities are verified. |
| Cross-workflow data reuse | Data from one business process may not be permitted or appropriate for another. | After legal, governance, and technical separation controls are documented. |
| Training on unresolved human overrides | Overrides often reveal ambiguity, policy gaps, or new failure classes. | After the override is categorized, resolved, and converted into a reviewed example. |
Red flags before signing or scaling
| Red flag | Why it matters | What to ask for |
|---|---|---|
| The improvement loop cannot be paused. | Production learning must be controllable. | Architecture showing manual gates, kill switch, and rollback paths. |
| Production traces flow into training without data classification. | Sensitive or unauthorized data may become training material. | Data lineage, redaction evidence, retention rules, and exclusion controls. |
| Regression tests are optional or informal. | Improvement on one slice can hide degradation elsewhere. | Locked evaluation suite and severity-weighted regression report. |
| Tool permissions are broad by default. | Agentic systems can cause damage through tools even when model output looks reasonable. | Least-privilege policy, denied-call logs, and scoped identities. |
| Cost claims are not reproduced on your workload. | Vendor infrastructure benchmarks may not match enterprise task mixes. | Side-by-side cost and throughput test using your agent, data, and concurrency profile. |
| No clear separation between observability, evaluation, and training datasets. | The agent may be evaluated on examples it has effectively seen. | Dataset split policy and audit trail. |
| Security review is deferred until after the pilot. | MCP, tools, sandboxes, and production traces introduce security concerns from day one. | Pre-pilot security review covering identity, secrets, sandboxing, and data egress. |
Buyer verdict
CoreWeave’s announcement is important because it bundles the infrastructure layers that serious production-agent teams need: training, inference, observability, reinforcement learning, evaluation, and sandboxed execution. That is more substantial than a standalone agent demo.
But the buying decision should not be based on the phrase “continuous improvement.” The only acceptable enterprise version is controlled continuous improvement: production traces are observed, filtered, evaluated, redacted, tested offline, regression-checked, canaried, monitored, and rolled back under human authority.
The practical recommendation: pilot CoreWeave’s loop only where the business process is bounded, data rights are clear, tools are least-privilege, errors are reversible, and the evaluation suite is stronger than the demo. If those conditions are not true, start with observability and evaluation first. Continuous agent improvement should be earned by evidence, not switched on by architecture.
FAQ
Is CoreWeave proving that autonomous agent improvement is safe?
No. CoreWeave says it launched capabilities that connect training, inference, observability, and reinforcement learning so agents can continuously learn and improve in production. That is a vendor claim about capability. Safety depends on enterprise controls: data gates, evaluation quality, rollback, tool permissions, and regression prevention.
Should enterprises let agents train directly on production data?
Not directly. Production traces should first be used for observability, failure analysis, and evaluation dataset construction. Only reviewed, redacted, rights-cleared, and separated data should be considered for post-training or reinforcement learning.
What should be blocked in a first pilot?
Block irreversible actions, broad tool permissions, access to sensitive datasets without classification, automatic training from raw traces, autonomous promotion to production, and any workflow without a rollback owner.
How should teams evaluate CoreWeave’s cost claims?
Use your own workload. CoreWeave says Serverless RL can reduce costs by up to 40% and accelerate training by about 1.4x versus local H100 GPU environments with no quality loss. Buyers should reproduce or reject that claim using their model, task mix, concurrency, evaluation suite, and total cost per successful task.
Where do CoreWeave Sandboxes fit?
CoreWeave says Sandboxes provide secure, isolated execution environments for reinforcement learning, AI agent tool use, and model evaluation. In a pilot, they should be used for tool-use tests, code execution, evaluation runs, and unsafe-action simulation. Buyers should still verify isolation, secrets handling, outbound access, persistence, and audit logs.
Source log
| Source | Publisher | Date | Exact URL | Claims supported |
|---|---|---|---|---|
| CoreWeave closes the training-to-inference gap for autonomous agent improvement | CoreWeave | May 28, 2026 | https://www.coreweave.com/news/coreweave-closes-the-training-to-inference-gap-for-autonomous-agent-improvement | Unified agentic AI capabilities; training, inference, observability, and reinforcement learning loop; “superintelligence loop”; Serverless RL claims; CoreWeave Inference; W&B Weave; W&B Skills; MCP server. |
| CoreWeave closes the loop between training and inference | CoreWeave Blog | May 2026 | https://www.coreweave.com/blog/coreweave-closes-the-loop-between-training-and-inference | Vendor position that teams can put agents in production from day one and let production signal drive improvement; W&B Weave production monitoring, signals, and evaluation framework. |
| CoreWeave Sandboxes launches to accelerate reinforcement learning, agent tool use, and model evaluation | CoreWeave | May 14, 2026 | https://www.coreweave.com/news/coreweave-sandboxes-launches-to-accelerate-reinforcement-learning-agent-tool-use-and-model-evaluation | Secure isolated execution environments for RL, agent tool use, and model evaluation; on-cluster and serverless access models; isolated virtual environment by default. |
| AI Risk Management Framework | NIST | Framework source | https://www.nist.gov/itl/ai-risk-management-framework | Voluntary guidance for incorporating trustworthiness considerations into AI design, development, use, and evaluation. |
| Agentic Universe April 2026 | Cloud Security Alliance | April 2026 | https://labs.cloudsecurityalliance.org/wp-content/uploads/2026/04/agentic-universe-april-2026-v1.pdf | General enterprise agentic AI risk context around tools, identity, shadow agents, and governance. Not used as a CoreWeave product source. |
| Reddit and market discussion signal | Community discussion | May 2026 | Not used as factual support | Used only as a community-interest signal that CoreWeave’s announcement was discussed in the agentic AI news cycle. |
WordPress publishing checklist
- Primary category: Workflows.
- Category ID: 4.
- Slug: coreweave-continuous-agent-improvement-production-loop.
- Focus keyword: continuous agent improvement.
- Confirm title is under 60 characters.
- Confirm meta description is under 155 characters.
- Use the hero image brief above with the Tovren premium editorial image template.
- Add internal links to Tovren’s agent observability, runtime governance, control plane, credential security, local infrastructure, and MCP sprawl articles.
- Keep all vendor claims labeled as CoreWeave claims.
- Do not add unsupported statements that CoreWeave proves autonomous improvement is safe or production-ready for all enterprise workflows.
Refresh triggers
| Trigger | Why refresh | What to update |
|---|---|---|
| CoreWeave publishes pricing, availability, region, or access details for Serverless RL, Inference, Weave integrations, Skills, MCP, or Sandboxes. | Buyers need current cost and deployment constraints. | Cost section, pilot economics, and buyer checklist. |
| CoreWeave releases customer case studies or independent benchmarks. | The article currently treats performance and cost claims as vendor claims. | Benchmark design, verdict, and adoption posture. |
| Weights & Biases updates Weave evaluation, monitoring, or MCP-related functionality. | Observability and regression controls are central to the recommended pilot. | Observability section, MCP safeguards, and regression table. |
| New enterprise security guidance emerges for MCP, agent tools, or sandboxed agent execution. | Tool and identity risk can change quickly as agent platforms mature. | MCP/tool-access safeguards and red flags. |
| NIST, CSA, or major enterprise security bodies publish updated agentic AI risk guidance. | Governance expectations may shift. | Risk framework references and production-data gate checklist. |
| CoreWeave changes claims around “superintelligence loop” or production learning. | The article depends on a precise separation between vendor claims and buyer verification. | Opening, claim table, and buyer verdict. |